Use cases for Speaker Recognition
What is a Transparency Note?
An AI system includes not only the technology, but also the people who will use it, the people who will be affected by it, and the environment in which it's deployed. Creating a system that is fit for its intended purpose requires an understanding of how the technology works, its capabilities and limitations, and how to achieve the best performance.
Microsoft provides Transparency Notes to help you understand how our AI technology works. They include the choices system owners can make that influence system performance and behavior, and the importance of thinking about the whole system, including the technology, the people, and the environment. You can use Transparency Notes when developing or deploying your own system, or share them with the people who will use or be affected by your system.
Transparency Notes are part of a broader effort at Microsoft to put our AI principles into practice. To find out more, see Microsoft's AI principles.
Introduction to Speaker Recognition
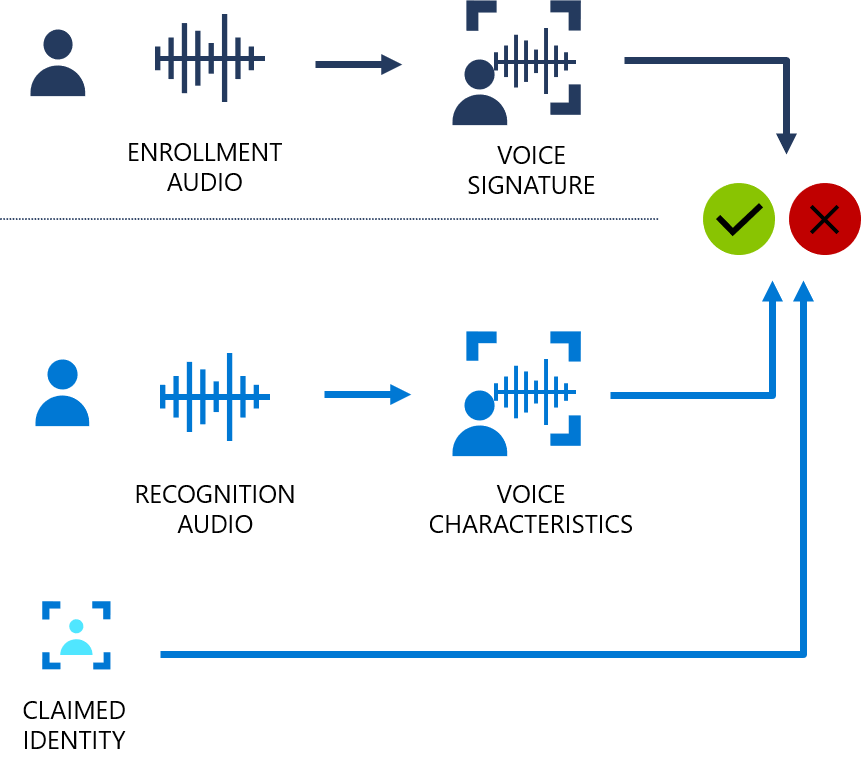
Speaker Recognition is an AI feature that can identify an individual speaking in an audio clip. The human voice has unique characteristics that can be associated with an individual. Speaker Recognition can recognize speakers by comparing the unique voice characteristics of incoming speech with registered voice signatures. For more information, see Speaker Recognition.
The basics of Speaker Recognition
Speaker Recognition capabilities are provided through two APIs:
Speaker Verification allows you to determine scenarios like “Is this Anna speaking?”. It verifies an individual’s identity by comparing the voice characteristics of their speech with the registered voice signature of the claimed identity.
Speaker Identification allows you to determine scenarios like “Who is speaking, Anna, Isha, or Jing?”. It attributes speech to individual speakers within a group of enrolled individuals.
| Term | Definition |
|---|---|
| Voice signature | Also called template or voiceprint. It's a numeric vector that represents an individual’s voice characteristics, extracted from audio recordings of a person speaking. The original audio recordings can't be interpreted or reconstructed based on a voice signature. Voice signature quality is a key determinant of how accurate your results are. |
| Enrollment | Enrollment is the process of creating voice signatures from the audio files of individuals’ speech, so they can be recognized at a later time. When a person is enrolled to a recognition system, that person's template is also associated with a primary identifier1 that will be used to determine which voice signature to compare with the recognition speech input. |
| Recognition | During Recognition, audio of a person speaking is compared against one or more voice signatures. The process is called verification if the audio is compared with one specific voice signature. It's called identification if the audio is compared with more than one voice signature to identify the speaker. |
| Text-dependent speaker verification | Also called active verification. The speaker chooses a specific passphrase (set of words) to be spoken during both enrollment and verification phases. During verification, the system recognizes the passphrase text and compares it with the enrollment passphrase. The result is based on both voice signature match and passphrase match. |
| Passphrase signature | In the enrollment audio of text-dependent APIs, the chosen passphrase is recognized to text. Then both the voice signature and the passphrase text are stored. The unique passphrase, such as "My voice is my passport verify me," is called a passphrase signature. The passphrase signature is also compared with the text of speech audio input during recognition. |
| Text-independent speaker verification | Also called passive verification. Speakers aren't required to speak pre-defined words, instead speakers can use any phrase. The voice signature is used during verification, but the speech content isn't considered. During recognition, speakers don't necessarily need to use the same phrase they did during enrollment. Longer audio recordings are recommended during enrollment to achieve reliable performance. |
| Activation phrase | It is a predefined phrase that the speaker has to read in the beginning of the enrollment when using text-independent APIs when active enrollment is enabled. Although speakers can use any phrases during the recognition process in text-independent speaker verification or identification, with active enrollment enabled, Microsoft requires the speaker to read this activation phrase first. After the activation step, the speaker can continue enrollment by using any phrases. |
1 Developers can associate the GUID (globally unique identifiers) generated by Microsoft with an individual’s primary identifier to support verification of that individual. Speaker Recognition doesn't store primary identifiers, such as customer IDs, with voice signatures. Instead, Microsoft associates stored voice signatures with random GUIDs.
Limited Access to Speaker Recognition
Speaker Recognition is a Limited Access service, and registration is required for access to some features. To learn more about Microsoft’s Limited Access policy visit aka.ms/limitedaccesscogservices. Certain features are only available to Microsoft managed customers and partners, and only for certain use cases selected at the time of registration.
Approved use cases
The following use cases are approved for customers:
- Customer identity verification: Call center or interactive voice response systems can use speaker verification to help verify a customer’s identity when a caller seeks to access the customer’s information or to take action with respect to the customer’s account.
- Multi-factor authentication: Verify identity by matching voice characteristics against registered voice signature as one factor to enhance security.
- Smart device personalization: Voice-enabled interaction devices, such as smart vehicles or smart speakers, can use Speaker Recognition to provide personalized content. For example, you can play different types of movies or music in response to voice commands in a household by using the text-independent Speaker Verification API.
- Speaker identification for meetings: Identify individual speakers from a meeting transcription or in captions.
- [Public Sector Only] Speaker identification or verification to: (a) assist law enforcement or court officials in the prosecution or defense of a serious crime or to identify a missing person, in all cases only to the extent specifically authorized by a court order issued in a jurisdiction that maintains a fair and independent judiciary, and provided that the person sought to be identified or verified is not a minor; OR (b) assist officials of duly empowered international organizations in the prosecution of abuses of international criminal law, international human rights law, or international humanitarian law, provided that the person sought to be identified or verified is not a minor.
Considerations when using Speaker Recognition
- Avoid using for recognizing multiple speakers in a speech input: Speaker Recognition can't recognize more than one person in a single speech input. Speaker Recognition is intended to take in one person's speech input and compare it to one or more voice signatures.
- Avoid using as a sole factor in authentication where security is important: Speaker Recognition is not designed to differentiate a synthesized voice or recordings of a voice from a live human speaker. Carefully consider scenarios with a risk of spoofing. Speaker Recognition shouldn't be used as the sole factor in authenticating a user in applications where security is the goal, such as access to financial information or physical security.
- Actively enroll users: Voice signatures contain speakers' biometric voiceprint characteristics. To help prevent misuse of Speaker Recognition, Microsoft provides an active enrollment feature for users of text-independent APIs through an activation step. The activation step indicates the speakers' active participation in creating their voice signatures and is intended to help avoid the scenario in which speakers are enrolled without their awareness. Be advised that this activation step does not alleviate customer’s legal obligations to ensure it has received all necessary permissions and consents from its users for the purposes of its processing, retention, and intended uses of speaker signatures created.
- Limit the number of candidates for speaker identification: Speaker Identification API can only take up to 50 candidates to compare the speech input against in an API call.
- Legal and regulatory considerations: Organizations need to evaluate potential specific legal and regulatory obligations when using any AI services and solutions, which may not be appropriate for use in every industry or scenario. Additionally, AI services or solutions are not designed for and may not be used in ways prohibited in applicable terms of service and relevant codes of conduct.