Overzicht van modeltypen in Microsoft Syntex
Van toepassing op: ✓ Alle aangepaste modellen | ✓ Alle vooraf gemaakte modellen
Inhoudsinformatie in Microsoft Syntex begint met documentverwerkingsmodellen. Met documentverwerkingsmodellen kunt u documenten identificeren en classificeren die worden geüpload naar SharePoint-documentbibliotheken en vervolgens de informatie extraheren die u nodig hebt uit elk bestand.
Wanneer het model wordt toegepast op een SharePoint-documentbibliotheek, wordt het gekoppeld aan een inhoudstype en bevat het kolommen voor het opslaan van de informatie die wordt geëxtraheerd. De inhoud die u maakt, wordt opgeslagen in de SharePoint-inhoudstypegalerie. U kunt er ook voor kiezen om het schema van bestaande inhoudstypen te gebruiken.
Syntex maakt gebruik van aangepaste modellen en vooraf gemaakte modellen.
Modellen kunnen bedrijfsmodellen zijn, die worden gemaakt in een inhoudscentrum, of lokale modellen die op uw lokale SharePoint-site worden gemaakt.
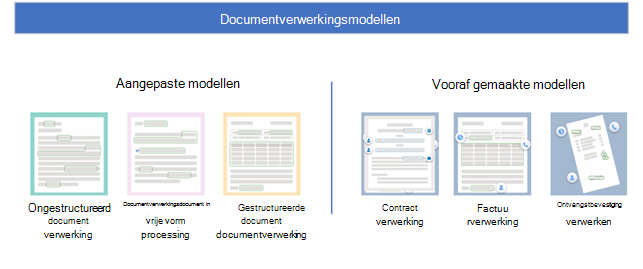
Aangepaste modellen
Het type aangepast model dat u kiest, is afhankelijk van de bestandstypen die u gebruikt, de indeling en structuur van de bestanden en waar u het model wilt toepassen.
Aangepaste modellen zijn onder andere:
- Ongestructureerde documentverwerking
- Documentverwerking in vrije vorm
- Gestructureerde documentverwerking
Zie Aangepaste modellen vergelijken om de verschillen naast elkaar in aangepaste modellen weer te geven.
Wanneer u een aangepast model maakt, selecteert u de trainingsmethode die is gekoppeld aan het modeltype. Als u bijvoorbeeld een ongestructureerd documentverwerkingsmodel wilt maken, kiest u op de pagina Opties voor het maken van een model waar u een model maakt de optie Methode onderwijzen . In de volgende tabel ziet u de trainingsmethode die is gekoppeld aan elk aangepast modeltype.
| Ongestructureerde documentverwerking |
Vrije documentverwerking |
Gestructureerde documentverwerking |
|---|---|---|
 |
 |
 |
Opmerking
Als u de opties voor de selectiemethode Vrije vorm en de indelingsmethode beschikbaar wilt maken voor gebruikers, moeten ze eerst worden geconfigureerd in de Microsoft 365-beheercentrum.
Ongestructureerde documentverwerking
Gebruik het niet-gestructureerde documentverwerkingsmodel om documenten automatisch te classificeren en er informatie uit te extraheren. Dit werkt het beste met ongestructureerde documenten zoals brieven of contracten. Deze documenten moeten tekst bevatten die kan worden geïdentificeerd op basis van frasen of patronen. De geïdentificeerde tekst duidt aan wat het bestandstype is (de classificatie) en wat u eruit wilt halen (de extractoren).
Een niet-gestructureerd document kan bijvoorbeeld een brief zijn voor het verlengen van een contract, die op verschillende manieren kan zijn geschreven. Informatie bestaat echter consistent in de hoofdtekst van elk contractverlengingsdocument, zoals de tekenreeks 'Begindatum van service' gevolgd door een werkelijke datum.
Dit modeltype ondersteunt het breedste scala aan bestandstypen en ondersteunt meer dan 40 talen.
Wanneer u een ongestructureerd documentverwerkingsmodel maakt, gebruikt u de optie Methode onderwijzen .
Zie Overzicht van ongestructureerde documentverwerking voor meer informatie.
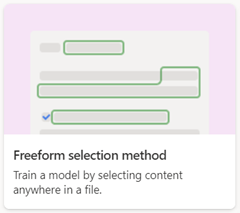
Documentverwerking in vrije vorm
Gebruik het freeform-documentverwerkingsmodel om automatisch informatie te extraheren uit ongestructureerde en vrije documenten, zoals brieven en contracten, waarbij de informatie overal in het document kan worden weergegeven.
Vrije documentverwerkingsmodellen maken gebruik van Microsoft Power Apps AI Builder om modellen in Syntex te maken en te trainen.
Opmerking
Het documentverwerkingsmodel in vrije vorm is nog niet beschikbaar in sommige regio's. Zie Beschikbaarheid van functies per regio voor meer informatie.
Omdat uw organisatie brieven en documenten in grote hoeveelheden ontvangt van verschillende bronnen, zoals e-mail, fax en e-mail, kan het verwerken van deze documenten en het handmatig invoeren ervan in een database veel tijd in beslag nemen. Door AI te gebruiken om de tekst en andere informatie uit deze documenten te extraheren, automatiseert dit model dit proces.
Dit modeltype is de beste optie voor documenten in PDF- of afbeeldingsbestanden wanneer u geen automatische classificatie van het type document nodig hebt en meer dan 40 talen ondersteunt.
Wanneer u een documentverwerkingsmodel met vrije vorm maakt, gebruikt u de optie Vrije vormselectiemethode .
Zie Overzicht van gestructureerde en vrije documentverwerking voor meer informatie.
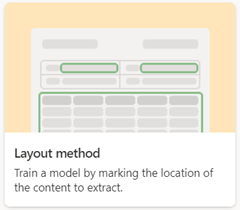
Gestructureerde documentverwerking
Gebruik het gestructureerde documentverwerkingsmodel om veld- en tabelwaarden automatisch te identificeren. Dit werkt het beste voor gestructureerde of semi-gestructureerde documenten, zoals formulieren en facturen.
Gestructureerde documentverwerkingsmodellen maken gebruik van Microsoft Power Apps AI Builder-documentverwerking (voorheen bekend als formulierverwerking) om modellen in Syntex te maken en te trainen.
Dit modeltype ondersteunt het breedste scala aan talen en is getraind om de indeling van uw formulier te begrijpen op basis van voorbeelddocumenten en leert vervolgens te zoeken naar de gegevens die u nodig hebt om uit vergelijkbare locaties te extraheren. Formulieren hebben meestal een meer gestructureerde indeling waarbij entiteiten zich op dezelfde locatie bevinden (bijvoorbeeld een burgerservicenummer op een belastingformulier).
Wanneer u een gestructureerd documentverwerkingsmodel maakt, gebruikt u de optie Indelingsmethode .
Zie Overzicht van gestructureerde en vrije documentverwerking voor meer informatie.
Vooraf gebouwde modellen
Als u geen aangepast model hoeft te maken, kunt u een vooraf samengesteld documentverwerkingsmodel gebruiken dat al is getraind voor specifieke gestructureerde documenten.
Vooraf gemaakte modellen zijn onder andere:
Vooraf gemaakte modellen zijn vooraf getraind om documenten en de gestructureerde informatie in de documenten te herkennen. In plaats van dat u een nieuw aangepast model hoeft te maken, kunt u een bestaand vooraf getraind model herhalen om specifieke velden toe te voegen die voldoen aan de behoeften van uw organisatie.
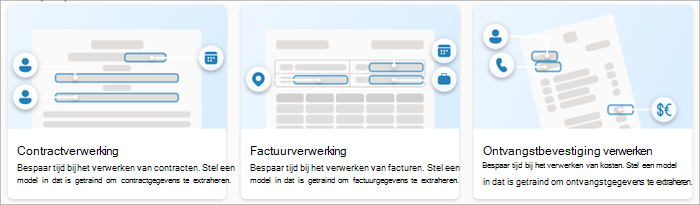
Contractverwerking
Het contractverwerkingsmodel analyseert en extraheert belangrijke informatie uit contractdocumenten. De API analyseert contracten in verschillende indelingen en extraheert belangrijke contractgegevens, zoals de naam van de klant of partij, het factureringsadres, de jurisdictie en de vervaldatum.
Zie Een vooraf samengesteld model gebruiken om informatie uit contracten te extraheren voor meer informatie over vooraf gemaakte contractverwerkingsmodellen.
Factuurverwerking
Het factuurverwerkingsmodel analyseert en extraheert belangrijke informatie uit verkoopfacturen. De API analyseert facturen in verschillende indelingen en extraheert belangrijke factuurgegevens, zoals de naam van de klant, het factuuradres, de vervaldatum en het verschuldigde bedrag.
Zie Een vooraf samengesteld model gebruiken om informatie uit facturen te extraheren voor meer informatie over vooraf gemaakte factuurverwerkingsmodellen.
Ontvangstbevestiging verwerken
Het vooraf gemaakte model voor het verwerken van ontvangstbewijzen analyseert en extraheert belangrijke informatie uit verkoopbevestigingen. De API analyseert afgedrukte en handgeschreven ontvangstbewijzen en extraheert belangrijke ontvangstgegevens, zoals de naam van de verkoper, het telefoonnummer van de verkoper, de transactiedatum, de belasting en het transactietotaal.
Zie Een vooraf samengesteld model gebruiken om informatie uit ontvangstbevestigingen te extraheren voor meer informatie over vooraf gemaakte modellen voor het verwerken van ontvangstbewijzen.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor