Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
[Dit artikel maakt deel uit van de voorlopige documentatie en kan nog veranderen.]
Het nieuwe geoptimaliseerde DirectLake semantische model zorgt voor snellere en meer geheugenefficiënte analyse van processen. Door geheugen te besparen kunt u grotere processen analyseren en bespaart u op kosten door kleinere Fabric-capaciteiten te gebruiken om analyses uit te voeren. Bovendien wordt gebruikgemaakt van een intuïtievere semantische modelgegevensstructuur van Power BI, waardoor u met minder tijd en moeite dieper op inzichten kunt ingaan.
Belangrijk
- Dit is een preview-functie.
- Preview-functies zijn niet bedoeld voor productiegebruik en bieden mogelijk beperkte functionaliteit. Deze functies zijn beschikbaar voorafgaand aan een officiële release, zodat klanten vroeg toegang kunnen krijgen en feedback kunnen geven.
- Ga voor meer informatie naar onze preview-voorwaarden.
Beschrijving van het semantische model
Wanneer een proces wordt gepubliceerd in de Fabric-werkruimte, wordt er een nieuw semantisch model en een bijbehorend rapport gemaakt. Deze schermafbeelding is een voorbeeld van een semantische modelstructuur die op Fabric is gepubliceerd.
Selecteer het vergrootglas in de rechterbenedenhoek van de afbeelding om deze te vergroten.

Relaties
Relaties die nodig zijn voor het filteren en de interconnectiviteit van visuals zijn vooraf gedefinieerd in het gepubliceerde gegevensmodel. Het is niet nodig om handmatig meer relaties te maken, tenzij andere gegevensbronnen zijn verbonden. Voor dit scenario gebruikt u het samengestelde semantische model van Power BI en bouwt u relaties op basis van dat model.
Overzicht van gegevensmodel
Vanuit logisch perspectief bestaat het gegevensmodel uit vele subsets van entiteiten, zoals weergegeven in de eerste paragraaf van deze sectie.
- Procesgegevens: alle procesgerelateerde gegevens zonder filtering en berekende meetwaarden
- Gegevens voor visuals: entiteiten die vooraf berekende gegevens bieden die nodig zijn om aangepaste visuals voor procesmining weer te geven
- Helpende entiteiten: andere entiteiten die nodig zijn voor Power BI
Hieronder volgt een korte beschrijving van de subsets en opgenomen entiteiten.
Procesgegevens
De inhoud van procesgegevensentiteiten verandert in specifieke scenario's.
- Wanneer procesmodelgegevens worden vernieuwd
- Wanneer een nieuwe weergave wordt gemaakt
- Wanneer een nieuwe aangepaste meetwaarde wordt gemaakt
- Wanneer een gebruiker de filterdefinitie in een procesweergave wijzigt
Door met deze entiteiten te werken, kunt u:
- Toegang tot de ruwe procesgegevens
- Procesgegevens beïnvloed door toegepaste filters
- Toegang krijgen tot de meetwaarden die zijn berekend op basis van de toegepaste filters
| Entity | Omschrijving |
|---|---|
| Aanvragen | Lijst van alle gevallen en hun kenmerken in het proces. Elke uitvoering bevat een unieke weergave van uitvoerings-id en waarden voor elk van de uitvoeringskenmerken, zoals gedefinieerd in de stap voor het instellen van de toewijzing. Combineer dit met de entiteit CaseMetrics om volledige uitvoeringsinformatie te krijgen. |
| Gebeurtenissen | Lijst met alle gebeurteniskenmerken in het proces. Elke gebeurtenis bevat een unieke index van gebeurtenis-id´s en waarden voor elk van de gebeurteniskenmerken, zoals gedefinieerd in de stap voor het instellen van de toewijzing. Combineer dit met de entiteit ProcessMapMetrics gefilterd op de kolom Is_Node om volledige gebeurtenisinformatie te verkrijgen. |
| CaseMetrics | Entiteit bevat alle metrische gegevens op caseniveau die betrekking hebben op een specifieke combinatie van case en weergave. Aangepaste metrische gegevens op uitvoeringsniveau die zijn gedefinieerd in de bureaublad-app Power Automate Process Mining, worden aan deze entiteit toegevoegd. |
| AttributesMetadata | Entiteit bevat de definitie van alle kenmerken op aanvraag-/gebeurtenisniveau zoals gedefinieerd bij het importeren van gebeurtenislogboekgegevens in het procesmodel. Het omvat het gegevenstype, het kenmerktype en het kenmerkniveau, dat aanvraag of gebeurtenis kan zijn. |
| MiningAttributes | Bevat waarden van beschikbare miningkenmerken. Er kan een procesweergave worden ingesteld om het proces vanuit verschillende perspectieven te bekijken op basis van het geselecteerde miningkenmerk. Als er geen ander miningkenmerk beschikbaar is, bevat de entiteit de waarden van het kenmerk Activity. |
| Weergaven | Lijst met beschikbare (gepubliceerde) weergaven die zijn gemaakt in de bureaublad-app Power Automate Process Mining. Alleen openbare procesweergaven worden naar de gegevensset gepubliceerd. Invoer kan worden gebruikt om rapporten, rapportpagina's en visuals te filteren om alleen gegevens uit de specifieke procesweergave te visualiseren. |
| Varianten | Entiteit bevat de relaties tussen varianten en procesweergaven. Er wordt een record opgenomen als een bepaalde variant in een weergave wordt opgenomen nadat rekening is gehouden met de filtercriteria. |
Visuele gegevens
Visuele gegevensentiteiten worden alleen opnieuw berekend wanneer er gegevens worden vernieuwd voor het procesmodel.
| Entity | Omschrijving |
|---|---|
| ProcessMapMetrics | Geaggregeerde metingen voor alle knooppunten en overgangen in het procesmodel die nodig zijn voor visualisatie in de aangepaste visual van het procesoverzicht. Deze entiteit combineert informatie van gebeurtenis (knooppunt) en informatie van rand (overgang). Als u gebeurtenissen of randen in uw andere visuele elementen wilt gebruiken, filtert u op de waarde in de kolom Is_Node.
Aangepaste metrische gegevens op gebeurtenisniveau die zijn gedefinieerd in de bureaublad-app Power Automate Process Mining, worden aan deze entiteit toegevoegd. |
Overige entiteiten
| Entity | Omschrijving |
|---|---|
| LocalizationTable | Interne tabel die wordt gebruikt voor lokalisatiedoeleinden. |
Samengesteld Power BI-model
Wij raden u aan het samengestelde Power BI-model te gebruiken op basis van het semantische model dat is gepubliceerd door Power Automate Process Mining en daarin de nodige aanpassingen door te voeren voor de volgende scenario's:
- U moet meer gegevensbronnen aanmaken
- U moet meer entiteiten maken
- U moet meer relaties maken
- U moet meer aangepaste DAX-query's (Data Analysis Expressions) maken
Belangrijk
Het semantische model wordt gemaakt in de DirectLake-toegangsmodus, maar de optie is ingesteld op Automatisch. Deze instelling houdt in dat het gebruik van niet-optimale DAX-query's of het onjuist instellen van een samengesteld model kan resulteren in een terugval naar de DirectQuery-modus. Dit betekent dat uw rapport niet kapot zal gaan, maar dat de prestaties wel lager kunnen uitvallen.
Ga voor meer informatie over het maken van samengestelde Power BI-gegevensmodellen op basis van semantische DirectLake-modellen naar: Samengestelde modellen bouwen op een semantisch model of model.
Vernieuwen van semantische modellen
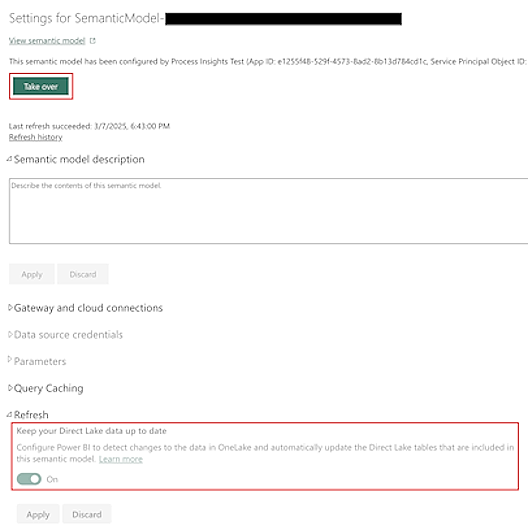
Standaard wordt het semantische model van Power Automate Process Mining automatisch up-to-date gehouden.
Bij grote datasets kan het langer duren voordat de gegevens in onderliggende tabellen in OneLake worden vernieuwd. Dit kan leiden tot mogelijke inconsistenties in het rapport. Hoewel er uiteindelijk consistentie zal zijn aan het einde van de gegevensvernieuwing (het semantische model wordt expliciet vernieuwd), wilt u de mogelijke tussenliggende inconsistenties wellicht verwijderen door de markering Uw Direct Lake-gegevens up-to-date houden uit te schakelen in het scherm Instellingen van het semantische model.
Voordat u dit scherm bijwerkt, moet u eigenaar worden van het semantische model door Overnemen boven aan het scherm Instellingen te selecteren.