Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met de fetchMoreData-API kunt u gegevenssegmenten van verschillende grootten laden als een manier om Power BI-visuals in te schakelen om de harde limiet van een gegevensweergave van 30.000 rijen te omzeilen. Naast de oorspronkelijke benadering van het aggregeren van alle aangevraagde segmenten, biedt de API nu ook ondersteuning voor het incrementeel laden van gegevenssegmenten.
U kunt het aantal rijen dat u op voorhand wilt ophalen, configureren of u kunt dit gebruiken dataReductionCustomization om de auteur van het rapport de segmentgrootte dynamisch in te stellen.
Notitie
De fetchMoreData API is beschikbaar in versie 3.4 en hoger.
De dynamische dataReductionCustomization API is beschikbaar in versie 5.2 en hoger.
Als u wilt achterhalen welke versie u gebruikt, controleert u het apiVersion bestand in het pbiviz.json .
Een gesegmenteerd ophalen van grote semantische modellen inschakelen
Definieer een venstergrootte voor dataReductionAlgorithm in het capabilities.json-bestand van de visual voor de vereistedataViewMapping. Hiermee count bepaalt u de venstergrootte, waarmee het aantal nieuwe gegevensrijen wordt beperkt dat u aan de dataview update kunt toevoegen.
Voeg bijvoorbeeld de volgende code toe in het bestand capabilities.json om 100 rijen met gegevens tegelijk toe te voegen:
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"window": {
"count": 100
}
}
}
}
]
Nieuwe segmenten worden als aanroep update toegevoegd aan de bestaande dataview en aan de visual aangeboden.
FetchMoreData gebruiken in de Power BI-visual
In Power BI kunt fetchMoreData u op twee manieren:
- aggregatiemodus segmenten
- modus incrementele updates
Aggregatiemodus segmenten (standaard)
Met de aggregatiemodus segmenten bevat de gegevensweergave die aan de visual wordt verstrekt de verzamelde gegevens van alle vorige fetchMoreData requests. Daarom groeit de grootte van de gegevensweergave met elke update volgens de venstergrootte. Als er bijvoorbeeld een totaal van 100.000 rijen wordt verwacht en de grootte van het venster is ingesteld op 10.000, moet de eerste updategegevensweergave 10.000 rijen bevatten, de tweede updategegevensweergave moet 20.000 rijen bevatten, enzovoort.
Selecteer de aggregatiemodus segmenten door aan te roepen fetchMoreData met aggregateSegments = true.
U kunt bepalen of er gegevens bestaan door te controleren op het bestaan van dataView.metadata.segment:
public update(options: VisualUpdateOptions) {
const dataView = options.dataViews[0];
console.log(dataView.metadata.segment);
// output: __proto__: Object
}
U kunt ook controleren of de update de eerste update of een volgende update is door deze te controleren options.operationKind. In de volgende code VisualDataChangeOperationKind.Create verwijst u naar het eerste segment en VisualDataChangeOperationKind.Append verwijst u naar volgende segmenten.
// CV update implementation
public update(options: VisualUpdateOptions) {
// indicates this is the first segment of new data.
if (options.operationKind == VisualDataChangeOperationKind.Create) {
}
// on second or subsequent segments:
if (options.operationKind == VisualDataChangeOperationKind.Append) {
}
// complete update implementation
}
U kunt de fetchMoreData methode ook aanroepen vanuit een UI-gebeurtenishandler:
btn_click(){
{
// check if more data is expected for the current data view
if (dataView.metadata.segment) {
// request for more data if available; as a response, Power BI will call update method
let request_accepted: bool = this.host.fetchMoreData(true);
// handle rejection
if (!request_accepted) {
// for example, when the 100 MB limit has been reached
}
}
}
Als reactie op het aanroepen van de this.host.fetchMoreData methode roept Power BI de update methode van de visual aan met een nieuw segment gegevens.
Notitie
Om beperkingen voor clientgeheugen te voorkomen, beperkt Power BI het opgehaalde gegevenstotaal tot 100 MB. Wanneer deze limiet is bereikt, fetchMoreData() wordt deze geretourneerd false.
Modus Incrementele updates
Met de modus incrementele updates bevat de gegevensweergave die aan de visual wordt verstrekt alleen de volgende set incrementele gegevens. De grootte van de gegevensweergave is gelijk aan de gedefinieerde venstergrootte (of kleiner als de laatste bit met gegevens kleiner is dan de venstergrootte). Als er bijvoorbeeld in totaal 101.000 rijen worden verwacht en de venstergrootte is ingesteld op 10.000, krijgt de visual 10 updates met een gegevensweergavegrootte van 10.000 en één update met een gegevensweergave van grootte 1.000.
De modus incrementele updates wordt geselecteerd door aan te roepen fetchMoreData met aggregateSegments = false.
U kunt bepalen of er gegevens bestaan door te controleren op het bestaan van dataView.metadata.segment:
public update(options: VisualUpdateOptions) {
const dataView = options.dataViews[0];
console.log(dataView.metadata.segment);
// output: __proto__: Object
}
U kunt ook controleren of de update de eerste update of een volgende update is door deze te controleren options.operationKind. In de volgende code VisualDataChangeOperationKind.Create verwijst u naar het eerste segment en VisualDataChangeOperationKind.Segment verwijst u naar volgende segmenten.
// CV update implementation
public update(options: VisualUpdateOptions) {
// indicates this is the first segment of new data.
if (options.operationKind == VisualDataChangeOperationKind.Create) {
}
// on second or subsequent segments:
if (options.operationKind == VisualDataChangeOperationKind.Segment) {
}
// skip overlapping rows
const rowOffset = (dataView.table['lastMergeIndex'] === undefined) ? 0 : dataView.table['lastMergeIndex'] + 1;
// Process incoming data
for (var i = rowOffset; i < dataView.table.rows.length; i++) {
var val = <number>(dataView.table.rows[i][0]); // Pick first column
}
// complete update implementation
}
U kunt de fetchMoreData methode ook aanroepen vanuit een UI-gebeurtenishandler:
btn_click(){
{
// check if more data is expected for the current data view
if (dataView.metadata.segment) {
// request for more data if available; as a response, Power BI will call update method
let request_accepted: bool = this.host.fetchMoreData(false);
// handle rejection
if (!request_accepted) {
// for example, when the 100 MB limit has been reached
}
}
}
Als reactie op het aanroepen van de this.host.fetchMoreData methode roept Power BI de update methode van de visual aan met een nieuw segment gegevens.
Notitie
Hoewel de gegevens in de verschillende updates van de gegevensweergaven voornamelijk exclusief zijn, is er enige overlap tussen opeenvolgende gegevensweergaven.
Voor tabel- en categorische gegevenstoewijzing kunnen de eerste N rijen voor gegevensweergaven naar verwachting gegevens bevatten die zijn gekopieerd uit de vorige gegevensweergave.
N kan worden bepaald door: (dataView.table['lastMergeIndex'] === undefined) ? 0 : dataView.table['lastMergeIndex'] + 1
De visual bewaart de gegevensweergave die eraan is doorgegeven, zodat deze toegang heeft tot de gegevens zonder extra communicatie met Power BI.
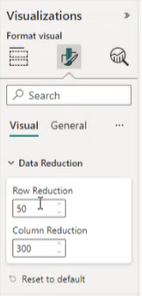
Aangepaste gegevensreductie
Omdat de ontwikkelaar niet altijd van tevoren weet welk type gegevens door de visual wordt weergegeven, kan de auteur van het rapport de grootte van het gegevenssegment dynamisch instellen. Vanuit API-versie 5.2 kunt u de auteur van het rapport toestaan de grootte van de gegevenssegmenten in te stellen die telkens worden opgehaald.
Als u wilt dat de auteur van het rapport het aantal kan instellen, moet u eerst een object voor het eigenschappenvenster definiëren dat is aangeroepen dataReductionCustomization in uw capabilities.json-bestand :
"objects": {
"dataReductionCustomization": {
"displayName": "Data Reduction",
"properties": {
"rowCount": {
"type": {
"numeric": true
},
"displayName": "Row Reduction",
"description": "Show Reduction for all row groups",
"suppressFormatPainterCopy": true
},
"columnCount": {
"type": {
"numeric": true
},
"displayName": "Column Reduction",
"description": "Show Reduction for all column groups",
"suppressFormatPainterCopy": true
}
}
}
},
Definieer daarna dataViewMappingsde standaardwaarden voor dataReductionCustomization.
"dataReductionCustomization": {
"matrix": {
"rowCount": {
"propertyIdentifier": {
"objectName": "dataReductionCustomization",
"propertyName": "rowCount"
},
"defaultValue": "100"
},
"columnCount": {
"propertyIdentifier": {
"objectName": "dataReductionCustomization",
"propertyName": "columnCount"
},
"defaultValue": "10"
}
}
}
De gegevensreductiegegevens worden weergegeven onder visual in het opmaakvenster.
Overwegingen en beperkingen
De venstergrootte is beperkt tot een bereik van 2-30.000.
Het totaalaantal rijen in de gegevensweergave is beperkt tot 1.048.576 rijen.
De geheugengrootte van de gegevensweergave is beperkt tot 100 MB in de aggregatiemodus segmenten.