Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel vindt u een overzicht van de schaalbaarheid en prestatieverschillen tussen gepagineerde rapporten in de Power BI-service versus SQL Server Reporting Services/Power BI Report Server. Het artikel is bedoeld voor gebruikers die gepagineerde rapporten van on-premises naar de Power BI-service migreren. Daarnaast biedt het ook inzicht in het optimaliseren van de prestaties van gepagineerde rapporten in de service.
Overwegingen voor schaalbaarheid
Bij het vergelijken van de schaalbaarheid van gepagineerde rapporten in de Power BI-service versus on-premises, zijn er twee belangrijke overwegingen: of de uitvoeringsomgeving is geoptimaliseerd voor het verwerken van de expressies die u gebruikt en het volume aan gegevens. Dit zijn enkele van de factoren die essentieel zijn voor het verbeteren van de schaalbaarheid van gepagineerde rapporten in de service.
Uitvoeringsomgeving
Een gepagineerd rapport kan worden uitgevoerd in twee verschillende uitvoeringsomgevingen: de standaardomgeving en de geoptimaliseerde omgeving. Het belangrijkste verschil tussen deze omgevingen is dat geoptimaliseerde omgeving hogere gegevensvolumes kan verwerken in vergelijking met de standaarduitvoeringsomgeving. De expressies die in het rapport worden gebruikt, bepalen de uitvoeringsomgeving en gebruikers kunnen deze niet wijzigen via instellingen of configuraties. De enige manier om ervoor te zorgen dat een rapport wordt uitgevoerd in een geoptimaliseerde omgeving, is het verwijderen van niet-ondersteunde expressies, omdat de geoptimaliseerde omgeving alleen een specifieke subset van rapportexpressies ondersteunt.
Als uw rapport niet-ondersteunde expressies bevat, kunt u overwegen deze expressies te verwijderen of bij te werken om ervoor te zorgen dat het rapport wordt uitgevoerd in een geoptimaliseerde omgeving. Eén benadering is het verplaatsen van berekeningen naar de gegevenssetquery. Daarnaast is een ander voordeel van het gebruik van berekende velden in de gegevensbronnen van het semantische model dat andere rapporten ze ook kunnen gebruiken. Power Query is een andere optie voor het uitvoeren van geavanceerde berekeningen en gegevensverwerkingsbewerkingen buiten het gepagineerde rapport. Meer informatie vindt u hier .
Opmerking
Een voorbeeld van een niet-ondersteunde expressie is het gebruik van berekende velden in de RDL, zoals: If(Weekday(Fields!SalesDate.Value) > 5, "Relax", "Work"). Weekdag is een functie die nog niet is geoptimaliseerd. In plaats van een rapportexpressie te gebruiken, kan dit worden berekend als onderdeel van een SQL-query. Voor SQL Server/Azure SQL dat kan worden uitgevoerd met behulp van de Transact SQL-functies DATEPART en IF..ELSE.
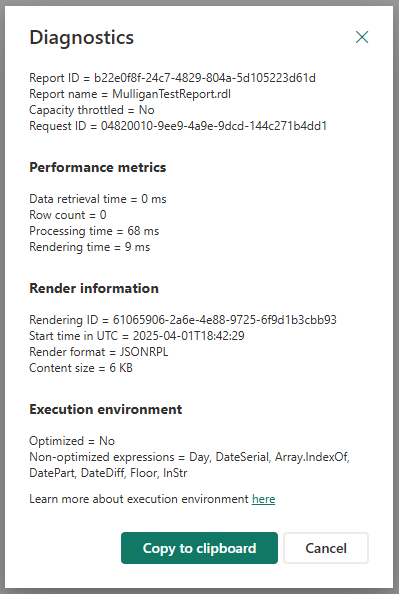
Als u wilt controleren of een rapport is uitgevoerd in de geoptimaliseerde omgeving, klikt u op de knop Diagnostische gegevens in het gepagineerde rapport en controleert u de sectie Uitvoeringsomgeving. Als het rapport wordt uitgevoerd in de geoptimaliseerde omgeving, wordt 'Geoptimaliseerd' 'Ja' weergegeven. Als het rapport wordt uitgevoerd in de standaardomgeving, niet-geoptimaliseerde omgeving, wordt in de sectie Uitvoeringsomgeving een lijst met niet-ondersteunde rapportexpressies weergegeven. Meer informatie over de metrische prestatiegegevens die op de kaart Diagnostische gegevens worden weergegeven, vindt u hier.
Grote gegevensvolumes
Zowel de standaard- als geoptimaliseerde uitvoeringsomgevingen voor gepagineerde rapporten hebben specifieke limieten voor gegevensvolumes die, wanneer deze worden overschreden, de verwerking van rapporten aanzienlijk vertragen. Wanneer de prestaties tijdens het exportrapportscenario vertragen, ziet de gebruiker de waarschuwing die in deze afbeelding wordt weergegeven:
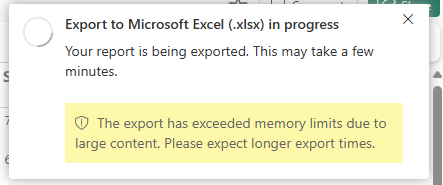
Dit probleem treedt doorgaans op in twee scenario's:
Gegevensdumps van tabellen zonder groeperingen en veel kolommen/rijen: deze gegevensdumps vereisen aanzienlijke resources bij het exporteren van het gepagineerde rapport naar Excel. U kunt het rapport ook exporteren naar CSV-indeling, wat minder intensief is.
Aggregatie van grote hoeveelheden gegevens tijdens het verwerken van rapporten: in plaats van grote gegevensvolumes in gepagineerde rapporten te aggregeren, voert u deze aggregaties uit in de query die wordt gebruikt door een gegevensset met gepagineerde rapporten. Deze aanpak vermindert de hoeveelheid gegevens die worden verwerkt door gepagineerde rapporten en verbetert doorgaans de algehele prestaties omdat gegevensbronnen zoals SQL Server of Power BI Semantisch model zeer geoptimaliseerd zijn voor gegevensaggregatie.
De aanbevolen drempelwaarde voor het gegevensvolume in een standaarduitvoeringsomgeving voordat de verwerking van rapporten aanzienlijk wordt vertraagd, is 1.000.000 rijen met 15-20 kolommen, bestaande uit een combinatie van numerieke, datum- en kleine tot middelgrote tekenreeksgegevenstypen.
Deze limiet verdubbelt voor geoptimaliseerde uitvoeringsomgevingen. Door afbeeldingsgegevens (byte[]) toe te voegen aan gegevensdumps, neemt het aantal gegevensvolumes aanzienlijk toe. Op dezelfde manier zou het selecteren van meer of minder kolommen dan opgegeven ook van invloed zijn op gegevensvolumes, net zoals de combinatie van gegevenstypen.
Prestatie-overwegingen
Zelfs voor middelgrote tot lage gegevensvolumes zijn er meer factoren die van invloed kunnen zijn op de prestaties van gepagineerde rapporten in de service voor deze scenario's:
- Rapportparameters verwerken telkens wanneer een rapport wordt geopend in de Power BI-service.
- Het rapport weergeven wanneer een gebruiker op de knop Rapport weergeven klikt.
- Gegevens ophalen uit verschillende gegevensbronnen
Aanbevolen procedures voor het verbeteren van de verwerking van rapportparameters
Rapportparameters kunnen worden ondersteund door gegevenssets met beschikbare en standaardwaarden, wat vaak het geval is voor meerdere parameters. Parameters kunnen ook afhankelijk zijn van andere parameters, zoals trapsgewijze parameters. Als gevolg hiervan worden parameterquery's opeenvolgend uitgevoerd. Wanneer een rapport trapsgewijze parameters heeft, wordt elke geparameteriseerde query uitgevoerd telkens wanneer volgende waarden worden geselecteerd.
Aangezien parameterwaarden meestal statisch zijn en niet regelmatig veranderen, gebruikt SQL Server Reporting Services ('SSRS') dit voordeel om robuuste ondersteuning te bieden voor gegevenssetcaches (zoals hier wordt uitgelegd), waardoor de verwerking van rapportparameters in SSRS wordt verbeterd. Gepagineerde rapporten in de service bieden echter geen ondersteuning voor gegevensset-caches. Daarom moeten gebruikers deze aanbevolen procedures volgen om de uitvoeringstijd voor parameterquery's voor gepagineerde rapporten in de service te verbeteren:
- Vermijd het gebruik van parameterquery's die worden uitgevoerd op on-premises gegevensbronnen die worden geopend via een Power BI Gateway. Gebruik in plaats daarvan een semantisch Power BI-model als een cache.
- Verminder de hoeveelheid gegevens die worden opgehaald door parameterquery's om de efficiëntie te garanderen. Het ophalen van meer dan 1000 waarden kan tijdrovend zijn en is mogelijk niet gebruiksvriendelijk in de gebruikersinterface.
- Gebruik de EnterData-gegevensextensie voor een statische set parameterwaarden om ze in te sluiten in de RDL. Naast het leveren van parameterwaarden kunnen deze gegevenssets ook worden gebruikt in uw rapport zonder een query uit te voeren.
Aanbevolen procedures voor het verbeteren van gepagineerde rapportweergave
Net als in de richtlijnen in de sectie schaalbaarheid, vermijdt u het gebruik van livequery's voor on-premises gegevensbronnen die worden geopend via een Power BI Gateway. Als u de weergave van rapporten in gepagineerde rapporten wilt verbeteren, gebruikt u in plaats daarvan een semantisch Power BI-model als cache. In plaats van gegevens in het gepagineerde rapport te aggregeren, voert u aggregaties uit in de gegevenssetquery om het gegevensvolume te verminderen en de prestaties te verbeteren. Gebruik gegevensbronnen zoals Azure SQL of semantische Power BI-modellen die sterk zijn geoptimaliseerd voor het verwerken van aggregaties.
Vermijd bovendien het gebruik van gegevensset- of tabel-/matrixfilters, omdat gepagineerde rapporten eerst alle gegevens ophalen en vervolgens filters intern toepassen, wat van invloed is op de prestaties. Gebruik in plaats daarvan waar mogelijk filters in gegevenssetquery's.
Aanbevolen procedures voor efficiënt ophalen van gegevens
Omgevingen met meerdere geografische gebieden, waarbij het rapport en de gegevensbron, zoals een semantisch model, zich in verschillende regio's bevinden, vertragen het ophalen van gegevens. Meer richtlijnen voor het efficiënt ophalen van gegevens voor gepagineerde rapporten vindt u hier.
Verwante inhoud
Raadpleeg de volgende bronnen voor meer informatie over dit artikel: