Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Power BI Dataflow Gen1 heeft nu een verouderde status en ontvangt geen nieuwe functie-investering. Voor Premium-klanten met infrastructuurtoegang is Dataflow Gen2 het aanbevolen pad, dat verbeteringen biedt in prestaties, schaal, betrouwbaarheid, functionaliteit en ingebouwde AI. Pro/PPU-klanten kunnen Gen1 blijven gebruiken als Gen2-richtlijnen voor deze scenario's zich ontwikkelen. Zie Upgrade van Dataflow Gen1 naar Dataflow Gen2 voor upgraderichtlijnen.
Het ontwerpen van een dimensional model is een van de meest voorkomende taken die u met een gegevensstroom kunt uitvoeren. In dit artikel worden enkele van de aanbevolen procedures beschreven voor het maken van een dimensional model met behulp van een gegevensstroom.
Faseringsgegevensstromen
Een van de belangrijkste punten in elk systeem voor gegevensintegratie is het aantal leesbewerkingen van het operationele bronsysteem te verminderen. In de traditionele architectuur voor gegevensintegratie wordt deze reductie uitgevoerd door een nieuwe database te maken die een faseringsdatabasewordt genoemd. Het doel van de faseringsdatabase is het laden van gegevens as-is uit de gegevensbron in de faseringsdatabase volgens een normaal schema.
De rest van de gegevensintegratie gebruikt vervolgens de faseringsdatabase als bron voor verdere transformatie en converteert deze naar de dimensionale modelstructuur.
U wordt aangeraden dezelfde benadering te volgen met behulp van gegevensstromen. Maak een set gegevensstromen die verantwoordelijk zijn voor het laden van gegevens as-is van het bronsysteem (en alleen voor de tabellen die u nodig hebt). Het resultaat wordt vervolgens opgeslagen in de opslagstructuur van de gegevensstroom (Azure Data Lake Storage of Dataverse). Deze wijziging zorgt ervoor dat de leesbewerking van het bronsysteem minimaal is.
Vervolgens kunt u andere gegevensstromen maken die hun gegevens uit faseringsgegevensstromen halen. De voordelen van deze aanpak zijn:
- Het aantal leesbewerkingen van het bronsysteem verminderen en de belasting van het bronsysteem verminderen als gevolg hiervan.
- De belasting van gegevensgateways verminderen als een on-premises gegevensbron wordt gebruikt.
- Een tussenliggende kopie van de gegevens hebben voor afstemmingsdoeleinden, voor het geval de bronsysteemgegevens veranderen.
- De transformatiegegevensstromen brononafhankelijk maken.
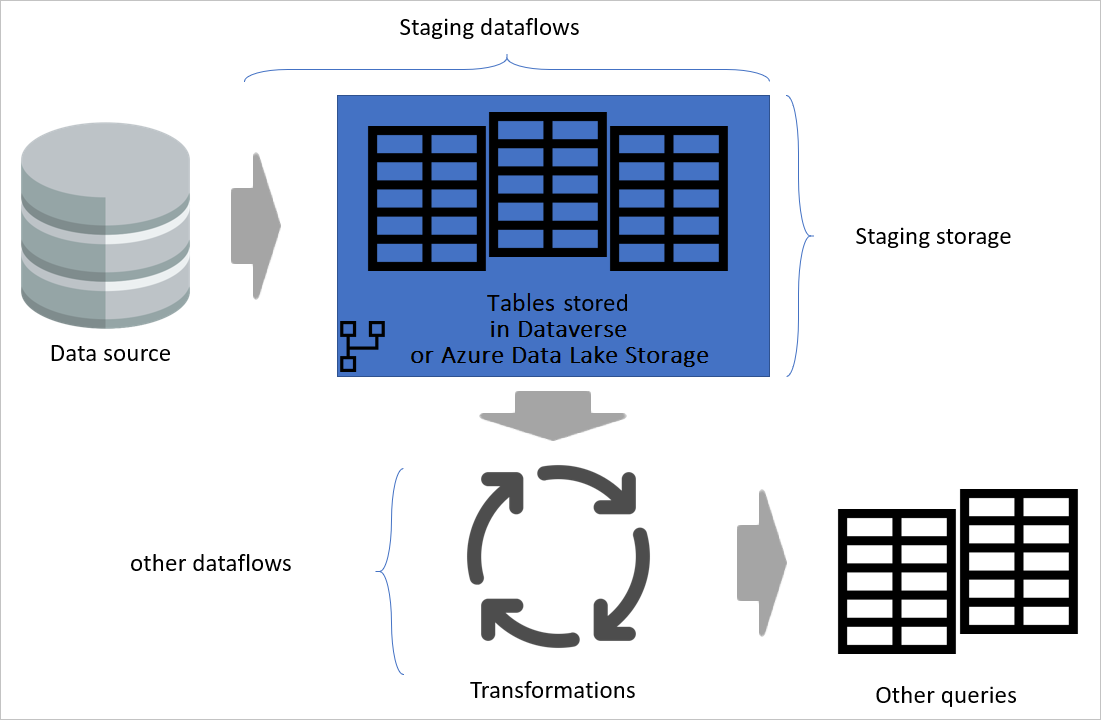
Diagram waarin de faseringsgegevensstromen en faseringsopslag worden benadrukt. Het diagram toont de gegevens die worden geopend vanuit de gegevensbron door de staging-dataflow en tabellen die worden opgeslagen in Cadavers of Azure Data Lake Storage. De tabellen worden vervolgens samen met andere gegevensstromen getransformeerd, die vervolgens worden verzonden als query's.
Gegevensstromen transformeren
Wanneer u uw transformatiegegevensstromen van de faseringsgegevensstromen scheidt, is de transformatie onafhankelijk van de bron. Deze scheiding helpt als u het bronsysteem naar een nieuw systeem migreert. In dat geval hoeft u alleen maar de faseringsgegevensstromen te wijzigen. De transformatiegegevensstromen werken waarschijnlijk zonder problemen, omdat ze alleen afkomstig zijn van de faseringsgegevensstromen.
Deze scheiding helpt ook als de bronsysteemverbinding traag is. De transformatiegegevensstroom hoeft niet lang te wachten op records die via een trage verbinding van het bronsysteem binnenkomen. De faseringsgegevensstroom heeft dat onderdeel al gedaan en de gegevens zijn klaar voor de transformatielaag.
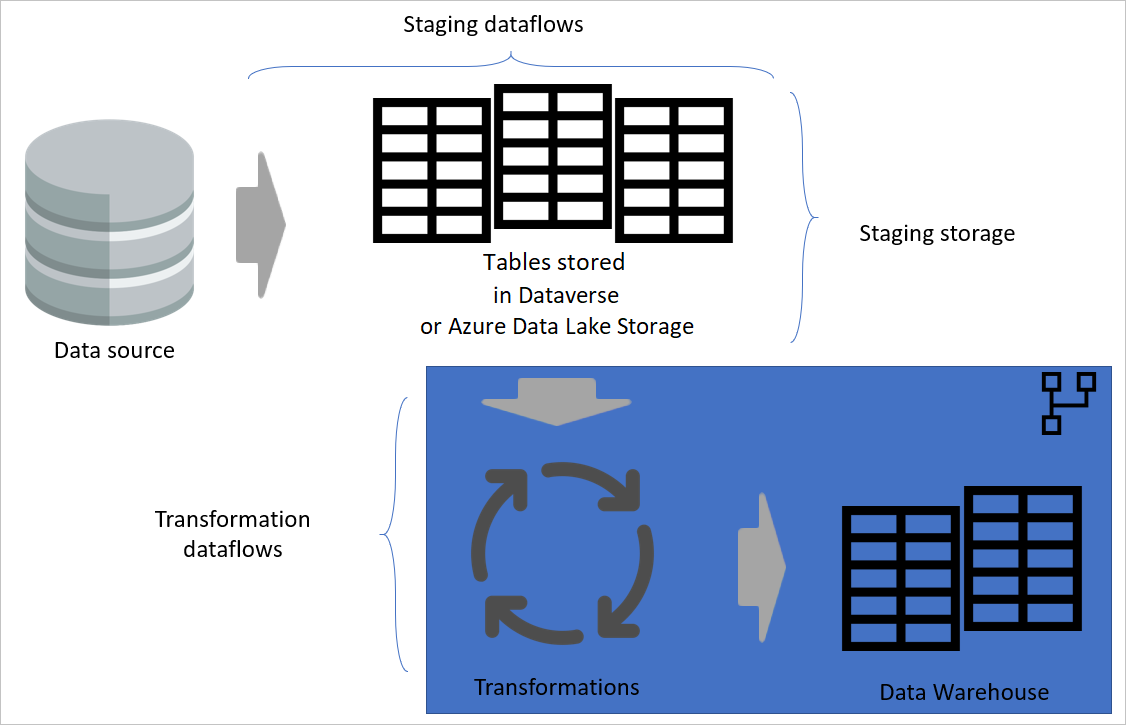
Gelaagde architectuur
Een gelaagde architectuur is een architectuur waarin u acties uitvoert in afzonderlijke lagen. De faserings- en transformatiegegevensstromen kunnen twee lagen van een architectuur met meerdere lagen zijn. Het uitvoeren van acties in lagen zorgt voor het minimale onderhoud dat vereist is. Als u iets wilt wijzigen, hoeft u deze alleen te wijzigen in de laag waar deze zich bevindt. De andere lagen moeten allemaal goed blijven werken.
In de volgende afbeelding ziet u een architectuur met meerdere lagen voor gegevensstromen waarin hun tabellen vervolgens worden gebruikt in semantische Power BI-modellen.
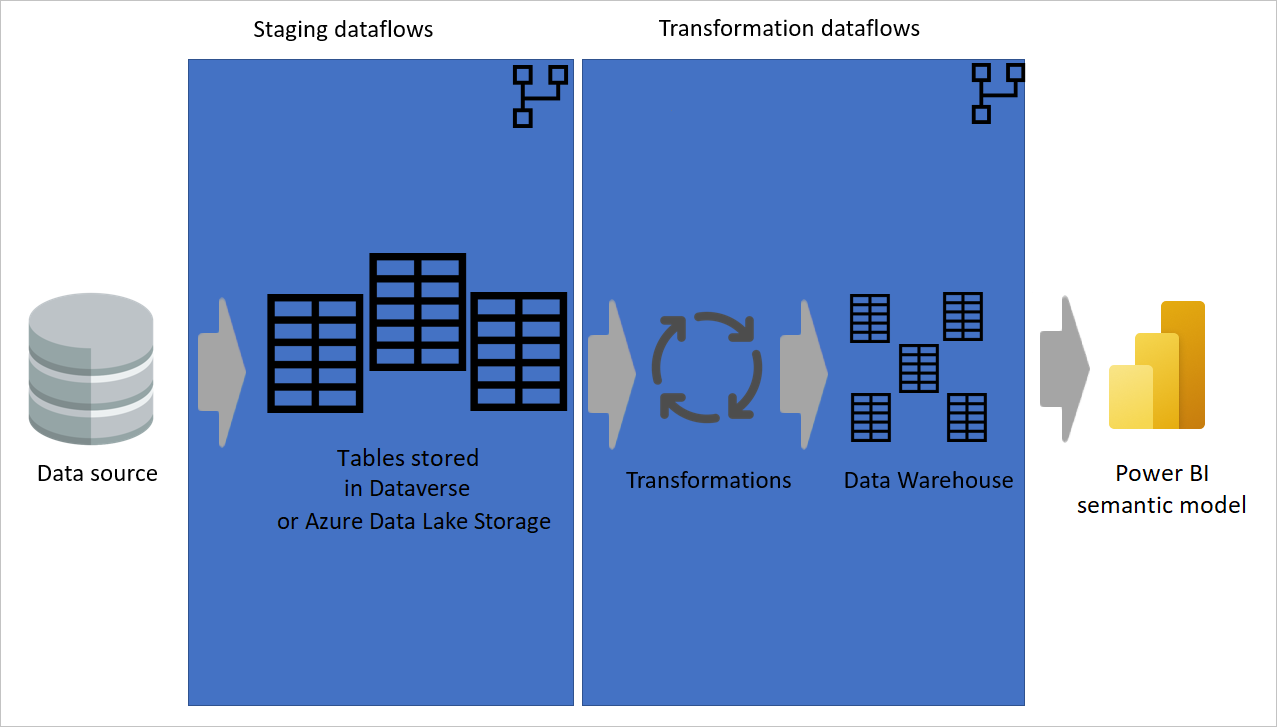
Een berekende tabel zoveel mogelijk gebruiken
Wanneer u het resultaat van een gegevensstroom in een andere gegevensstroom gebruikt, gebruikt u het concept van de berekende tabel, wat betekent dat u gegevens ophaalt uit een 'al verwerkte en opgeslagen' tabel. Hetzelfde kan gebeuren in een gegevensstroom. Wanneer u naar een tabel uit een andere tabel verwijst, kunt u de berekende tabel gebruiken. Deze methode is handig wanneer u een set transformaties hebt die moeten worden uitgevoerd in meerdere tabellen, die algemene transformaties worden genoemd.
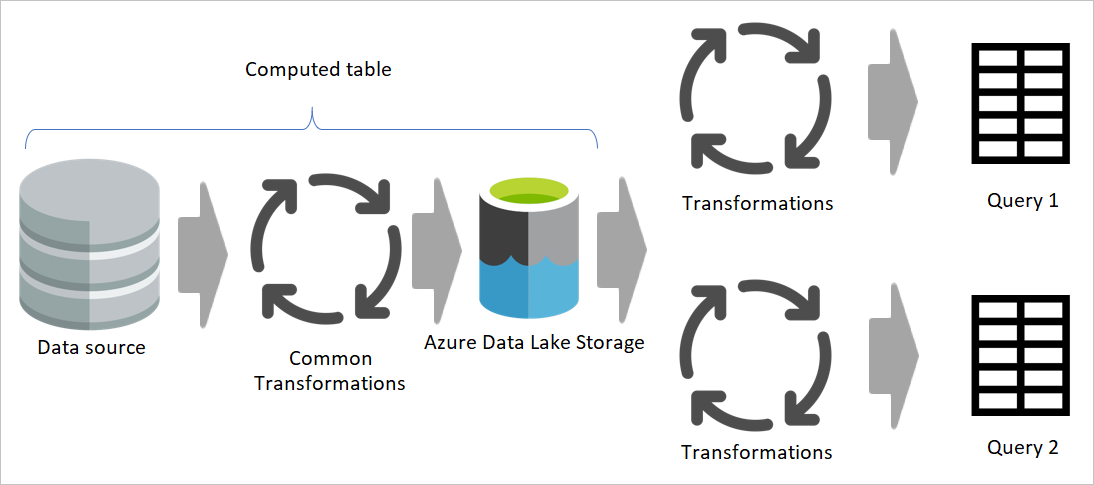
In de vorige afbeelding haalt de berekende tabel de gegevens rechtstreeks uit de bron op. In de architectuur van faserings- en transformatiegegevensstromen is het echter waarschijnlijk dat de berekende tabellen afkomstig zijn van de faseringsgegevensstromen.
Een stervormig schema maken
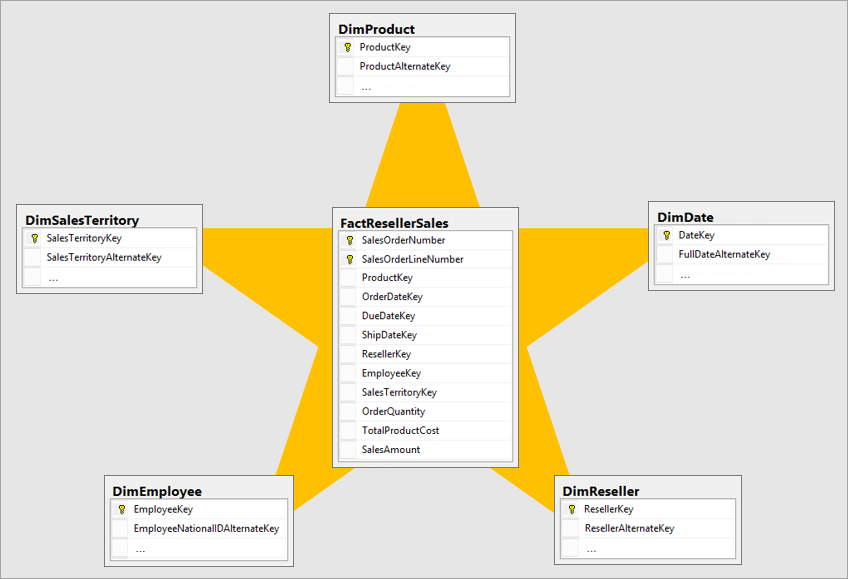
Het beste dimensionale model is een stervormig schemamodel met dimensies en feitentabellen die zijn ontworpen om de hoeveelheid tijd te minimaliseren om query's uit te voeren op de gegevens uit het model. Een stervormig schemamodel maakt het ook eenvoudig te begrijpen voor de gegevensvisualisator.
Het is niet ideaal om gegevens in dezelfde indeling van het operationele systeem in een BI-systeem te brengen. De gegevenstabellen moeten worden aangepast. Sommige tabellen moeten de vorm hebben van een dimensietabel, waarmee de beschrijvende informatie wordt bijgehouden. Sommige tabellen moeten de vorm van een feitentabel hebben om de samenvoegbare gegevens te behouden. De beste indeling voor feitentabellen en dimensietabellen om te vormen is een stervormig schema. Ga voor meer informatie naar Begrijp het stervormige schema en het belang ervan voor Power BI.
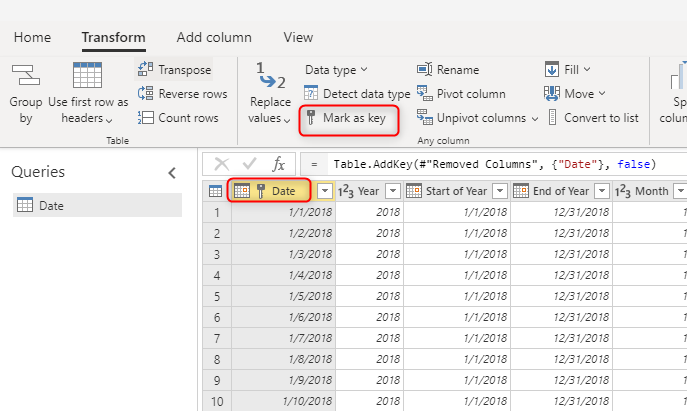
Een unieke sleutelwaarde gebruiken voor dimensies
Zorg er bij het bouwen van dimensietabellen voor dat u een sleutel voor elke tabel hebt. Deze sleutel zorgt ervoor dat er geen veel-op-veel-relaties (of met andere woorden, 'zwakke' relaties tussen dimensies zijn. U kunt de sleutel maken door een transformatie toe te passen om ervoor te zorgen dat een kolom of een combinatie van kolommen unieke rijen in de dimensie retourneert. Vervolgens kan die combinatie van kolommen worden gemarkeerd als een sleutel in de tabel in de gegevensstroom.
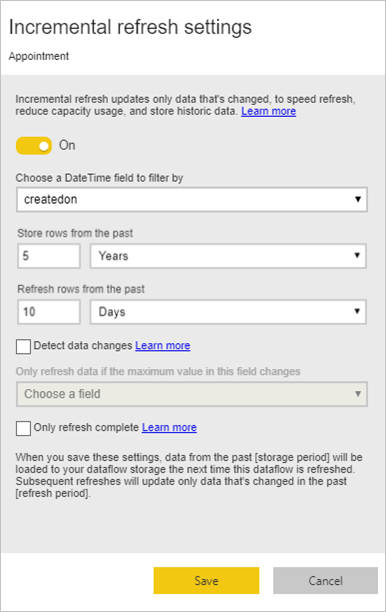
Voer een incrementele vernieuwingsactie uit voor grote feitentabellen
Feitentabellen zijn altijd de grootste tabellen in het dimensionale model. Het is raadzaam om het aantal rijen dat voor deze tabellen wordt overgedragen, te verminderen. Als u een zeer grote feitentabel hebt, moet u ervoor zorgen dat u incrementeel vernieuwen gebruikt voor die tabel. U kunt incrementeel vernieuwen in het semantische Power BI-model en ook in de gegevensstroomtabellen.
U kunt incrementeel vernieuwen gebruiken om slechts een deel van de gegevens te vernieuwen, het deel dat is gewijzigd. Er zijn meerdere opties om te kiezen welk deel van de gegevens moet worden vernieuwd en welk deel moet worden bewaard. Ga naar Incrementeel vernieuwen met Power BI-gegevensstromen voor meer informatie.
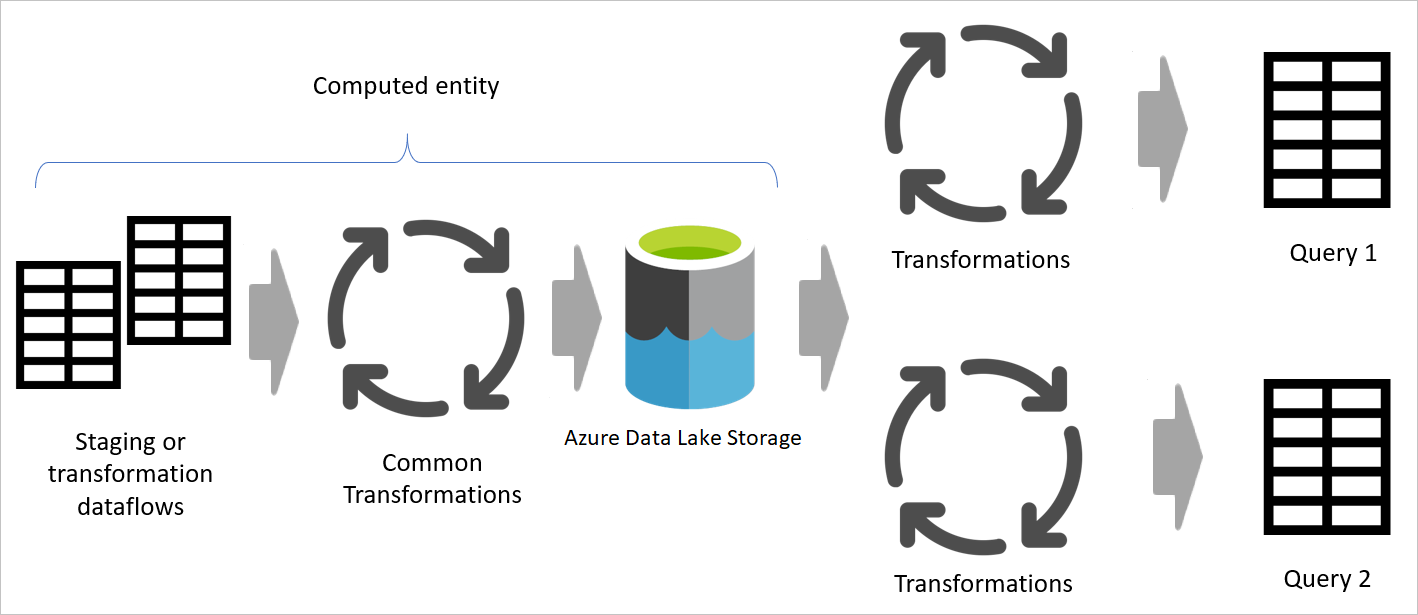
Verwijzen naar dimensies en feitentabellen maken
In het bronsysteem hebt u vaak een tabel die u gebruikt voor het genereren van feiten- en dimensietabellen in het datawarehouse. Deze tabellen zijn goede kandidaten voor berekende tabellen en ook tussenliggende gegevensstromen. Het algemene deel van het proces, zoals het opschonen van gegevens en het verwijderen van extra rijen en kolommen, kan eenmaal worden uitgevoerd. Met behulp van een verwijzing uit de uitvoer van deze acties kunt u de dimensie- en feitentabellen opstellen. Deze benadering maakt gebruik van de berekende tabel voor de algemene transformaties.