Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Er zijn voordelen voor het gebruik van berekende tabellen in een gegevensstroom. In dit artikel worden gebruiksvoorbeelden voor berekende tabellen beschreven en wordt beschreven hoe ze achter de schermen werken.
Wat is een berekende tabel?
Een tabel vertegenwoordigt de gegevensuitvoer van een query die is gemaakt in een gegevensstroom, nadat de gegevensstroom is vernieuwd. Het vertegenwoordigt gegevens uit een bron en, optioneel, de transformaties die erop zijn toegepast. Soms wilt u mogelijk nieuwe tabellen maken die een functie zijn van een eerder opgenomen tabel.
Hoewel het mogelijk is om de query's te herhalen die een tabel hebben gemaakt en nieuwe transformaties hierop toe te passen, heeft deze benadering nadelen: gegevens worden tweemaal opgenomen en de belasting van de gegevensbron wordt verdubbeld.
Berekende tabellen lossen beide problemen op. Berekende tabellen zijn vergelijkbaar met andere tabellen omdat ze gegevens ophalen uit een bron en u verdere transformaties kunt toepassen om ze te maken. Maar hun gegevens zijn afkomstig van de gebruikte opslaggegevensstroom en niet van de oorspronkelijke gegevensbron. Dat wil gezegd, ze zijn eerder gemaakt door een gegevensstroom en vervolgens opnieuw gebruikt.
Berekende tabellen kunnen worden gemaakt door te verwijzen naar een tabel in dezelfde gegevensstroom of door te verwijzen naar een tabel die in een andere gegevensstroom is gemaakt.

Waarom een berekende tabel gebruiken?
Het uitvoeren van alle transformatiestappen in één tabel kan traag zijn. Er kunnen veel redenen zijn voor deze vertraging: de gegevensbron kan traag zijn of de transformaties die u uitvoert, moeten mogelijk worden gerepliceerd in twee of meer query's. Het kan handig zijn om eerst de gegevens uit de bron op te nemen en deze vervolgens opnieuw te gebruiken in een of meer tabellen. In dergelijke gevallen kunt u ervoor kiezen om twee tabellen te maken: een die gegevens ophaalt uit de gegevensbron en een andere, een berekende tabel, die meer transformaties toepast op gegevens die al zijn geschreven in de data lake die door een gegevensstroom wordt gebruikt. Deze wijziging kan de prestaties en herbruikbaarheid van gegevens verbeteren, waardoor tijd en resources worden bespaard.
Als twee tabellen bijvoorbeeld zelfs een deel van hun transformatielogica delen, zonder een berekende tabel, moet de transformatie twee keer worden uitgevoerd.
Als er echter een berekende tabel wordt gebruikt, wordt het gemeenschappelijke (gedeelde) deel van de transformatie eenmaal verwerkt en opgeslagen in Azure Data Lake Storage. De resterende transformaties worden vervolgens verwerkt vanuit de uitvoer van de algemene transformatie. Over het algemeen is deze verwerking veel sneller.
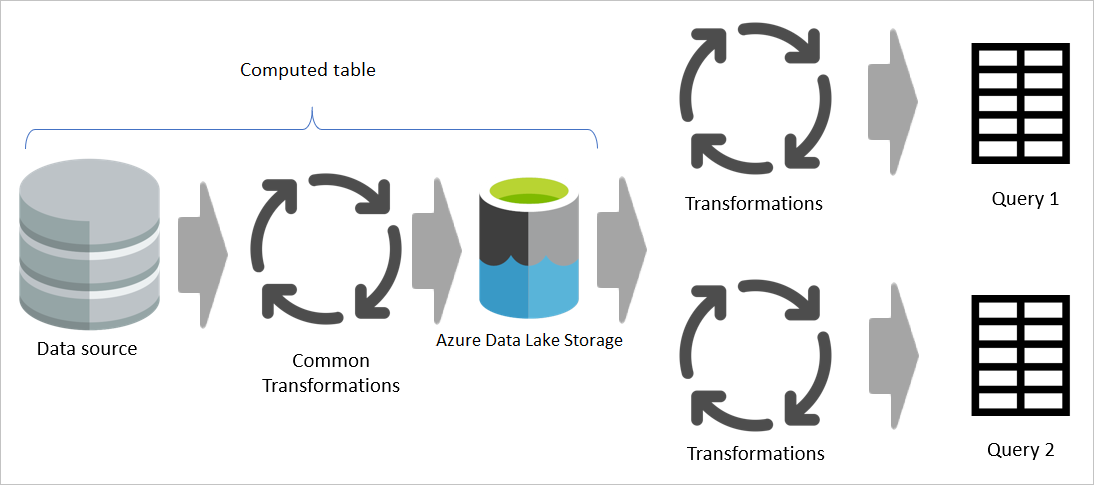
Een berekende tabel biedt één plaats als de broncode voor de transformatie en versnelt de transformatie, omdat deze slechts eenmaal hoeft te worden uitgevoerd in plaats van meerdere keren. De belasting van de gegevensbron wordt ook verminderd.
Voorbeeldscenario voor het gebruik van een berekende tabel
Als u een samengevoegde tabel in Power BI bouwt om het gegevensmodel te versnellen, kunt u de samengevoegde tabel maken door te verwijzen naar de oorspronkelijke tabel en er meer transformaties op toe te passen. Door deze methode te gebruiken, hoeft u uw transformatie niet te repliceren van de bron (het deel dat afkomstig is van de oorspronkelijke tabel).
In de volgende afbeelding ziet u bijvoorbeeld een tabel Orders.

Met behulp van een verwijzing uit deze tabel kunt u een berekende tabel maken.
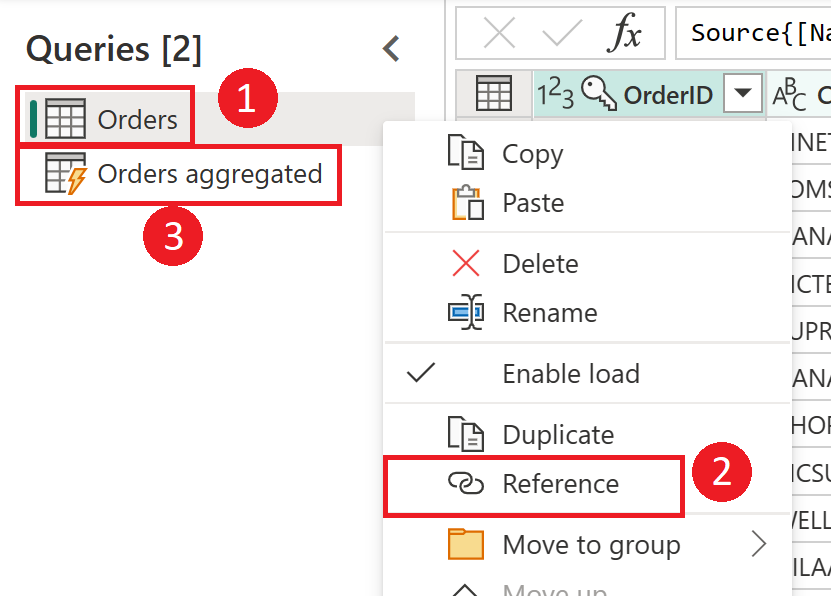
Schermopname die laat zien hoe u een berekende tabel maakt vanuit de tabel Orders. Klik eerst met de rechtermuisknop op de tabel Orders in het deelvenster Query's en selecteer de optie Verwijzing in de vervolgkeuzelijst. Met deze actie maakt u de berekende tabel, waarvan de naam hier wordt gewijzigd in Geaggregeerde orders.
De berekende tabel kan verdere transformaties hebben. U kunt bijvoorbeeld Group By gebruiken om de gegevens op klantniveau samen te voegen.
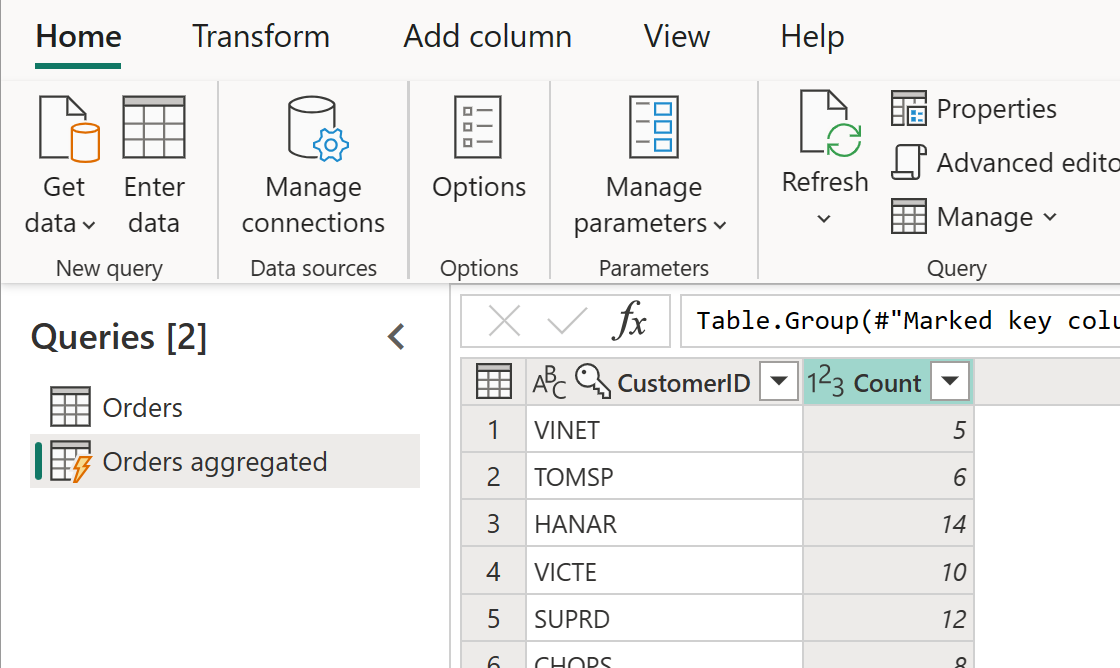
Dit betekent dat de samengevoegde tabel Orders gegevens ophaalt uit de tabel Orders en niet opnieuw uit de gegevensbron. Omdat sommige transformaties die moeten worden uitgevoerd, al in de tabel Orders zijn uitgevoerd, zijn de prestaties beter en is gegevenstransformatie sneller.
Berekende tabel in andere gegevensstromen
U kunt ook een berekende tabel maken in andere gegevensstromen. Het kan worden gemaakt door gegevens op te halen uit een gegevensstroom met de Microsoft Power Platform-gegevensstroomconnector.
Afbeelding benadrukt de Connector voor Power Platform-gegevensstromen in het venster Gegevensbron kiezen in Power Query. Ook opgenomen is een beschrijving waarin wordt aangegeven dat één gegevensstroomtabel kan worden gebouwd op basis van de gegevens uit een andere gegevensstroomtabel, die al in de opslag is opgeslagen.
Het concept van de berekende tabel is dat er een tabel in de opslag wordt bewaard en andere tabellen uit de tabel worden opgeslagen, zodat u de leestijd van de gegevensbron kunt verminderen en enkele algemene transformaties kunt delen. Deze reductie kan worden bereikt door gegevens op te halen uit andere gegevensstromen via de gegevensstroomconnector of door te verwijzen naar een andere query in dezelfde gegevensstroom.
Berekende tabel: Met transformaties of zonder?
Nu u weet dat berekende tabellen geweldig zijn voor het verbeteren van de prestaties van de gegevenstransformatie, is een goede vraag om te stellen of transformaties altijd moeten worden uitgesteld naar de berekende tabel of dat ze moeten worden toegepast op de brontabel. Dat wil zeggen, moeten gegevens altijd worden opgenomen in één tabel en vervolgens worden getransformeerd in een berekende tabel? Wat zijn de voor- en nadelen?
Gegevens laden zonder transformatie voor tekst-/CSV-bestanden
Wanneer een gegevensbron geen ondersteuning biedt voor het vouwen van query's (zoals Tekst-/CSV-bestanden), is er weinig voordeel bij het toepassen van transformaties bij het ophalen van gegevens uit de bron, met name als gegevensvolumes groot zijn. De brontabel moet alleen gegevens uit het tekstbestand/CSV-bestand laden zonder transformaties toe te passen. Vervolgens kunnen berekende tabellen gegevens ophalen uit de brontabel en de transformatie uitvoeren boven op de opgenomen gegevens.
U kunt vragen wat de waarde is van het maken van een brontabel die alleen gegevens opneemt? Een dergelijke tabel kan nog steeds nuttig zijn, omdat als de gegevens uit de bron in meer dan één tabel worden gebruikt, de belasting van de gegevensbron wordt verminderd. Daarnaast kunnen gegevens nu opnieuw worden gebruikt door andere personen en gegevensstromen. Berekende tabellen zijn vooral handig in scenario's waarin het gegevensvolume groot is of wanneer een gegevensbron wordt geopend via een on-premises gegevensgateway, omdat ze het verkeer van de gateway en de belasting van gegevensbronnen daarachter verminderen.
Enkele algemene transformaties uitvoeren voor een SQL-tabel
Als uw gegevensbron ondersteuning biedt voor het vouwen van query's, kunt u een aantal transformaties in de brontabel uitvoeren omdat de query is gevouwen naar de gegevensbron en alleen de getransformeerde gegevens worden opgehaald. Deze wijzigingen verbeteren de algehele prestaties. De set transformaties die gebruikelijk zijn in downstream berekende tabellen moeten worden toegepast in de brontabel, zodat ze kunnen worden gevouwen naar de bron. Andere transformaties die alleen van toepassing zijn op downstreamtabellen, moeten worden uitgevoerd in berekende tabellen.