Wat is de opslagstructuur voor analytische gegevensstromen?
Analytische gegevensstromen slaan zowel gegevens als metagegevens op in Azure Data Lake Storage. Gegevensstromen maken gebruik van een standaardstructuur om gegevens op te slaan en te beschrijven die zijn gemaakt in de lake. Dit wordt Common Data Model-mappen genoemd. In dit artikel vindt u meer informatie over de opslagstandaard die gegevensstromen achter de schermen gebruiken.
Opslag heeft een structuur nodig voor een analytische gegevensstroom
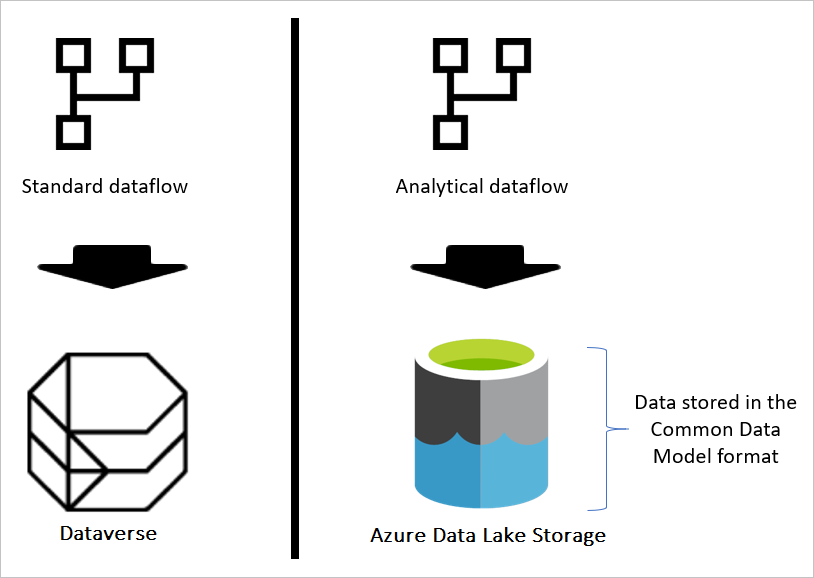
Als de gegevensstroom standaard is, worden de gegevens opgeslagen in Dataverse. Dataverse lijkt op een databasesysteem; het heeft het concept van tabellen, weergaven, enzovoort. Dataverse is een gestructureerde optie voor gegevensopslag die wordt gebruikt door standaardgegevensstromen.
Wanneer de gegevensstroom echter analytisch is, worden de gegevens opgeslagen in Azure Data Lake Storage. De gegevens en metagegevens van een gegevensstroom worden opgeslagen in een map Common Data Model. Omdat een opslagaccount mogelijk meerdere gegevensstromen bevat die erin zijn opgeslagen, is er een hiërarchie van mappen en submappen geïntroduceerd om de gegevens te organiseren. Afhankelijk van het product waarin de gegevensstroom is gemaakt, kunnen de mappen en submappen werkruimten (of omgevingen) vertegenwoordigen en vervolgens de map Common Data Model van de gegevensstroom. In de map Common Data Model worden zowel het schema als de gegevens van de gegevensstroomtabellen opgeslagen. Deze structuur volgt de standaarden die zijn gedefinieerd voor Common Data Model.
Wat is de opslagstructuur van Common Data Model?
Common Data Model is een metagegevensstructuur die is gedefinieerd om overeenstemming en consistentie te bieden voor het gebruik van gegevens op meerdere platforms. Common Data Model is geen gegevensopslag, het is de manier waarop gegevens worden opgeslagen en gedefinieerd.
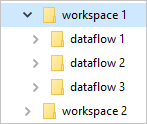
Common Data Model-mappen definiëren hoe het schema en de bijbehorende gegevens van een tabel moeten worden opgeslagen. In Azure Data Lake Storage worden gegevens geordend in mappen. Mappen kunnen een werkruimte of omgeving vertegenwoordigen. Onder deze mappen worden submappen voor elke gegevensstroom gemaakt.
Wat bevindt zich in een gegevensstroommap?
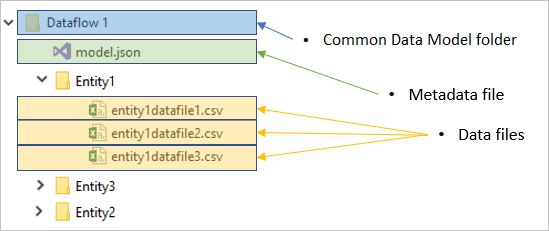
Elke gegevensstroommap bevat een submap voor elke tabel en een metagegevensbestand met de naam model.json.
Het metagegevensbestand: model.json
Het model.json bestand is de metagegevensdefinitie van de gegevensstroom. Dit is het ene bestand dat alle metagegevens van de gegevensstroom bevat. Het bevat een lijst met tabellen, de kolommen en de bijbehorende gegevenstypen in elke tabel, de relatie tussen tabellen, enzovoort. U kunt dit bestand eenvoudig exporteren vanuit een gegevensstroom, zelfs als u geen toegang hebt tot de mapstructuur Common Data Model.
U kunt dit JSON-bestand gebruiken om uw gegevensstroom te migreren (of te importeren) naar een andere werkruimte of omgeving.
Als u precies wilt weten wat het model.json metagegevensbestand bevat, gaat u naar het metagegevensbestand (model.json) voor Common Data Model.
Gegevensbestanden
Naast het metagegevensbestand bevat de gegevensstroommap ook andere submappen. In een gegevensstroom worden de gegevens voor elke tabel opgeslagen in een submap met de naam van de tabel. Gegevens voor een tabel kunnen worden gesplitst in meerdere gegevenspartities, opgeslagen in CSV-indeling.
Common Data Model-mappen bekijken of openen
Als u gegevensstromen gebruikt die gebruikmaken van opslag die is geleverd door het product waarin ze zijn gemaakt, hebt u geen rechtstreeks toegang tot deze mappen. In dergelijke gevallen vereist het ophalen van gegevens uit de gegevensstromen de Microsoft Power Platform-gegevensstroomconnector die beschikbaar is in de ervaring Gegevens ophalen in de producten Power BI-service, Power Apps en Dynamics 35 Customer Insights, of in Power BI Desktop.
Als u wilt weten hoe gegevensstromen en de interne Integratie van Data Lake Storage werken, gaat u naar Gegevensstromen en Azure Data Lake-integratie (preview).
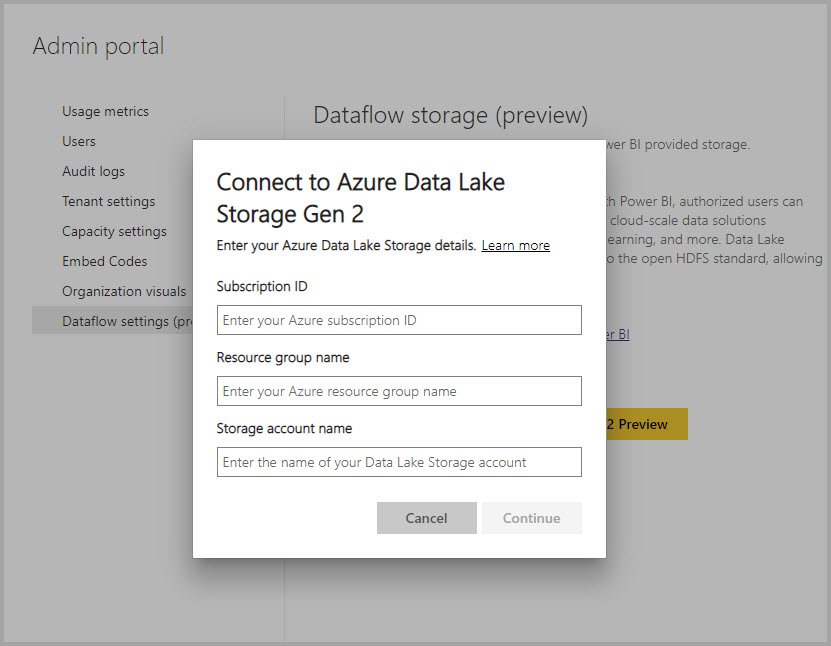
Als uw organisatie gegevensstromen heeft ingeschakeld om te profiteren van het Data Lake Storage-account en is geselecteerd als een taakdoel voor gegevensstromen, kunt u nog steeds gegevens ophalen uit de gegevensstroom met behulp van de Power Platform-gegevensstroomconnector zoals hierboven vermeld. Maar u kunt ook rechtstreeks via de lake toegang krijgen tot de map Common Data Model van de gegevensstroom, zelfs buiten de hulpprogramma's en services van Power Platform. Toegang tot het meer is mogelijk via Azure Portal, Microsoft Azure Storage Explorer of een andere service of ervaring die ondersteuning biedt voor Azure Data Lake Storage. Meer informatie vindt u in Verbinding maken met Azure Data Lake Storage Gen2 voor gegevensstroomopslag
Volgende stappen
Common Data Model gebruiken om Azure Data Lake Storage Gen2 te optimaliseren
Het metagegevensbestand (model.json) voor het Common Data Model
Een CDM-map toevoegen aan Power BI als een gegevensstroom (preview)
Verbinding maken met Azure Data Lake Storage Gen2 voor gegevensstroomopslag
Gegevensstroominstellingen voor werkruimten configureren (preview)