Functie-hashing
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning.
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
Converteert tekstgegevens naar met gehele getallen gecodeerde functies met behulp van de Vowpal Wabbit-bibliotheek
Categorie: Text Analytics
Notitie
Van toepassing op: alleen Machine Learning Studio (klassiek)
Vergelijkbare modules voor slepen en neerzetten zijn beschikbaar in Azure Machine Learning designer.
Moduleoverzicht
In dit artikel wordt beschreven hoe u de module Functie-hashing in Machine Learning Studio (klassiek) gebruikt om een stroom Engelse tekst te transformeren naar een set functies die worden weergegeven als gehele getallen. U kunt deze gehashte functie vervolgens doorgeven aan een machine learning-algoritme om een tekstanalysemodel te trainen.
De functie-hashfunctionaliteit die in deze module wordt geboden, is gebaseerd op het Vowpal Wabbit-framework. Zie Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model voor meer informatie.
Meer informatie over functie-hashing
Functie-hashing werkt door unieke tokens te converteren naar gehele getallen. Het werkt op de exacte tekenreeksen die u als invoer opgeeft en voert geen taalkundige analyse of voorverwerking uit.
Neem bijvoorbeeld een set eenvoudige zinnen zoals deze, gevolgd door een gevoelsscore. Stel dat u deze tekst wilt gebruiken om een model te maken.
| USERTEXT | SENTIMENT |
|---|---|
| Ik hield van dit boek | 3 |
| Ik haatte dit boek | 1 |
| Dit boek was geweldig | 3 |
| Ik hou van boeken | 2 |
Intern maakt de module Functie-hashing een woordenlijst van n-grammen. De lijst met bigrams voor deze gegevensset is bijvoorbeeld ongeveer als volgt:
| TERM (bigrams) | FREQUENTIE |
|---|---|
| Dit boek | 3 |
| Ik hield van | 1 |
| Ik haatte | 1 |
| Ik hou van | 1 |
U kunt de grootte van de n-gram beheren met behulp van de eigenschap N-gram . Als u bigrams kiest, worden ook unigrammen berekend. De woordenlijst bevat dus ook enkele termen als deze:
| Term (unigrammen) | FREQUENTIE |
|---|---|
| boek | 3 |
| I | 3 |
| boeken | 1 |
| Was | 1 |
Nadat de woordenlijst is gemaakt, converteert de module Functie-hashing de woordenlijsttermen naar hashwaarden en wordt berekend of er in elk geval een functie is gebruikt. Voor elke rij met tekstgegevens voert de module een set kolommen uit, één kolom voor elke gehashte functie.
Na hashing kunnen de functiekolommen er bijvoorbeeld ongeveer als volgt uitzien:
| Waardering | Hashfunctie 1 | Hashfunctie 2 | Hashfunctie 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Als de waarde in de kolom 0 is, bevat de rij de hashfunctie niet.
- Als de waarde 1 is, bevat de rij de functie.
Het voordeel van het gebruik van functie-hashing is dat u tekstdocumenten van variabele lengte kunt weergeven als numerieke functievectoren van gelijke lengte en dimensionaliteitsvermindering kunt bereiken. Als u daarentegen de tekstkolom voor de training probeert te gebruiken, wordt deze beschouwd als een categorische functiekolom, met veel, veel afzonderlijke waarden.
Als u de uitvoer als numeriek hebt, kunt u ook veel verschillende machine learning-methoden gebruiken met de gegevens, waaronder classificatie, clustering of het ophalen van gegevens. Omdat opzoekbewerkingen gehele hashes kunnen gebruiken in plaats van tekenreeksvergelijkingen, is het ophalen van de functiegewichten ook veel sneller.
Functie-hashing configureren
Voeg de module Feature Hashing toe aan uw experiment in Studio (klassiek).
Verbinding maken de gegevensset met de tekst die u wilt analyseren.
Tip
Omdat functie-hashing geen lexicale bewerkingen uitvoert, zoals stemming of afkapping, kunt u soms betere resultaten krijgen door tekstvoorverwerking uit te voeren voordat u functie-hashing toepast. Zie de secties Aanbevolen procedures en technische notities voor suggesties.
Selecteer voor doelkolommen de tekstkolommen die u wilt converteren naar gehashte functies.
De kolommen moeten het gegevenstype tekenreeks zijn en moeten worden gemarkeerd als een functiekolom .
Als u meerdere tekstkolommen kiest die als invoer moeten worden gebruikt, kan dit een enorm effect hebben op de functiedimensionaliteit. Als er bijvoorbeeld een 10-bits hash wordt gebruikt voor één tekstkolom, bevat de uitvoer 1024 kolommen. Als er een 10-bits hash wordt gebruikt voor twee tekstkolommen, bevat de uitvoer 2048 kolommen.
Notitie
Standaard markeert Studio (klassiek) de meeste tekstkolommen als functies, dus als u alle tekstkolommen selecteert, krijgt u mogelijk te veel kolommen, inclusief veel kolommen die niet daadwerkelijk vrije tekst zijn. Gebruik de optie Wissen in Metagegevens bewerken om te voorkomen dat andere tekstkolommen worden gehasht.
Gebruik Hashing bitsize om het aantal bits op te geven dat moet worden gebruikt bij het maken van de hash-tabel.
De standaardbitgrootte is 10. Voor veel problemen is deze waarde meer dan voldoende, maar of voldoende is voor uw gegevens, is afhankelijk van de grootte van de n-gram woordenlijst in de trainingstekst. Met een grote woordenschat is er mogelijk meer ruimte nodig om conflicten te voorkomen.
We raden u aan om een ander aantal bits voor deze parameter te gebruiken en de prestaties van de machine learning-oplossing te evalueren.
Typ voor N-grammen een getal dat de maximale lengte van de n-grammen definieert die aan de trainingswoordenlijst moet worden toegevoegd. Een n-gram is een reeks n woorden, behandeld als een unieke eenheid.
N-gram = 1: Unigrammen of enkele woorden.
N-gram = 2: Bigrams of reeksen met twee woorden, plus unigrammen.
N-gram = 3: Trigrammen, of drie woordenreeksen, plus bigrams en unigrammen.
Voer het experiment uit.
Resultaten
Nadat de verwerking is voltooid, voert de module een getransformeerde gegevensset uit waarin de oorspronkelijke tekstkolom is geconverteerd naar meerdere kolommen, die elk een functie in de tekst vertegenwoordigen. Afhankelijk van hoe groot de woordenlijst is, kan de resulterende gegevensset extreem groot zijn:
| Kolomnaam 1 | Kolomtype 2 |
|---|---|
| USERTEXT | Oorspronkelijke gegevenskolom |
| SENTIMENT | Oorspronkelijke gegevenskolom |
| USERTEXT - Hashing-functie 1 | Gehashte functiekolom |
| USERTEXT - Hashfunctie 2 | Gehashte functiekolom |
| USERTEXT - Hashfunctie n | Gehashte functiekolom |
| USERTEXT - Hashfunctie 1024 | Gehashte functiekolom |
Nadat u de getransformeerde gegevensset hebt gemaakt, kunt u deze gebruiken als invoer voor de module Train Model , samen met een goed classificatiemodel, zoals Ondersteuningsvectormachine met twee klassen.
Aanbevolen procedures
Enkele aanbevolen procedures die u kunt gebruiken tijdens het modelleren van tekstgegevens, worden gedemonstreerd in het volgende diagram dat een experiment vertegenwoordigt
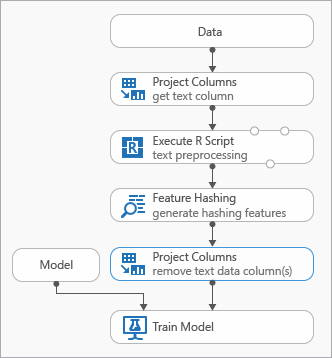
Mogelijk moet u een Execute R Script-module toevoegen voordat u functie-hashing gebruikt om de invoertekst vooraf te verwerken. Met R-script hebt u ook de flexibiliteit om aangepaste woordenlijsten of aangepaste transformaties te gebruiken.
Voeg een module Select Columns in Dataset toe na de module Functie-hashing om de tekstkolommen uit de uitvoergegevensset te verwijderen. U hebt de tekstkolommen niet nodig nadat de hashfuncties zijn gegenereerd.
U kunt ook de module Metagegevens bewerken gebruiken om het kenmerk van de functie uit de tekstkolom te wissen.
Overweeg ook om deze opties voor tekstvoorverwerking te gebruiken om de resultaten te vereenvoudigen en de nauwkeurigheid te verbeteren:
- woordbreking
- woordverwijdering stoppen
- normalisering van case
- verwijdering van leestekens en speciale tekens
- stemming.
De optimale set voorverwerkingsmethoden die in elke afzonderlijke oplossing moeten worden toegepast, is afhankelijk van domein, vocabulaire en bedrijfsbehoefte. We raden u aan te experimenteren met uw gegevens om te zien welke aangepaste tekstverwerkingsmethoden het meest effectief zijn.
Voorbeelden
Zie de Azure AI Gallery voor voorbeelden van hoe functie-hashing wordt gebruikt voor tekstanalyse:
Nieuwscategorisatie: maakt gebruik van functie-hashing om artikelen te classificeren in een vooraf gedefinieerde lijst met categorieën.
Vergelijkbare bedrijven: gebruikt de tekst van Wikipedia-artikelen om bedrijven te categoriseren.
Tekstclassificatie: In dit vijfdelige voorbeeld wordt tekst uit Twitter-berichten gebruikt om sentimentanalyse uit te voeren.
Technische opmerkingen
Deze sectie bevat implementatiedetails, tips en antwoorden op veelgestelde vragen.
Tip
Naast het gebruik van functie-hashing wilt u misschien andere methoden gebruiken om functies uit tekst te extraheren. Bijvoorbeeld:
- Gebruik de module Preprocess Text om artefacten, zoals spelfouten, te verwijderen of om tekstvoorbereiding voor hashing te vereenvoudigen.
- Gebruik Sleuteltermen extraheren om natuurlijke taalverwerking te gebruiken om woordgroepen te extraheren.
- Gebruik Herkenning van benoemde entiteiten om belangrijke entiteiten te identificeren.
Machine Learning Studio (klassiek) biedt een sjabloon voor tekstclassificatie die u begeleidt bij het gebruik van de module Functie-hashing voor functieextractie.
Implementatiegegevens
De module Functie-hashing maakt gebruik van een snel machine learning-framework met de naam Vowpal Wabbit dat woorden in geheugenindexen hashes bevat, met behulp van een populaire open source hash-functie genaamd murmurhash3. Deze hash-functie is een niet-cryptografisch hash-algoritme dat tekstinvoer toewijst aan gehele getallen en populair is omdat deze goed presteert in een willekeurige verdeling van sleutels. In tegenstelling tot cryptografische hashfuncties kan deze eenvoudig worden omgekeerd door een kwaadwillende persoon, zodat deze niet geschikt is voor cryptografische doeleinden.
Het doel van hashing is om documenten met variabele lengte te converteren naar numerieke functievectoren met gelijke lengte, om dimensionaliteitsvermindering te ondersteunen en het opzoeken van functiegewichten sneller te maken.
Elke hashfunctie vertegenwoordigt een of meer n-gram tekstfuncties (unigrammen of afzonderlijke woorden, bi-gram, tri-gram, enzovoort), afhankelijk van het aantal bits (weergegeven als k) en het aantal n-gram dat is opgegeven als parameters. Het projecteert functienamen voor het niet-ondertekende woord van de machinearchitectuur met behulp van het murmurhash v3-algoritme (alleen 32-bits) dat vervolgens AND-ed is met (2^k)-1. Dat wil gezegd, de hash-waarde wordt geprojecteerd naar de eerste k-bits in lagere volgorde en de resterende bits zijn nul. Als het opgegeven aantal bits 14 is, kan de hashtabel 214-1 (of 16.383) vermeldingen bevatten.
Voor veel problemen is de standaardhashtabel (bitsize = 10) meer dan voldoende; Afhankelijk van de grootte van de n-gram woordenlijst in de trainingstekst kan er echter meer ruimte nodig zijn om conflicten te voorkomen. We raden u aan om een ander aantal bits te gebruiken voor de parameter Hashing-bitsize en de prestaties van de machine learning-oplossing te evalueren.
Verwachte invoer
| Naam | Type | Beschrijving |
|---|---|---|
| Gegevensset | Gegevenstabel | Invoergegevensset |
Moduleparameters
| Name | Bereik | Type | Standaard | Beschrijving |
|---|---|---|---|---|
| Doelkolommen | Alle | ColumnSelection | StringFeature | Kies de kolommen waarop hashing wordt toegepast. |
| Hashing bitsize | [1;31] | Geheel getal | 10 | Typ het aantal bits dat moet worden gebruikt bij het hashen van de geselecteerde kolommen |
| N-gram | [0;10] | Geheel getal | 2 | Geef het aantal N-grammen op dat is gegenereerd tijdens hashing. Standaard worden zowel unigrammen als bigrams geëxtraheerd |
Uitvoerwaarden
| Naam | Type | Beschrijving |
|---|---|---|
| Getransformeerde gegevensset | Gegevenstabel | Uitvoergegevensset met gehashte kolommen |
Uitzonderingen
| Uitzondering | Beschrijving |
|---|---|
| Fout 0001 | Er treedt een uitzondering op als een of meer opgegeven kolommen met gegevensset niet kunnen worden gevonden. |
| Fout 0003 | Er treedt een uitzondering op als een of meer invoerwaarden null of leeg zijn. |
| Fout 0004 | Uitzondering treedt op als de parameter kleiner is dan of gelijk is aan een specifieke waarde. |
| Fout 0017 | Uitzondering treedt op als een of meer opgegeven kolommen een type hebben dat niet wordt ondersteund door de huidige module. |
Zie Machine Learning Foutcodes voor een lijst met fouten die specifiek zijn voor Studio-modules (klassiek).
Zie Machine Learning REST API-foutcodes voor een lijst met API-uitzonderingen.