Voorbeeld: Een aangepaste vaardigheid bouwen en implementeren met Azure Machine Learning (gearchiveerd)
Dit voorbeeld is gearchiveerd en wordt niet ondersteund. Hierin werd uitgelegd hoe u een aangepaste vaardigheid kunt maken met behulp van Azure Machine Learning om op aspect gebaseerde sentimenten uit de beoordelingen te extraheren. Hierdoor kon de toewijzing van positief en negatief gevoel binnen dezelfde beoordeling correct worden toegewezen aan geïdentificeerde entiteiten zoals personeel, ruimte, lobby of zwembad.
Om het model voor aspectgebaseerd sentiment te trainen in Azure Machine Learning, gebruikt u de opslagplaats met NLP-recepten. Het model wordt vervolgens als een eindpunt geïmplementeerd in een Azure Kubernetes-cluster. Na implementatie wordt het eindpunt als een AML-vaardigheid aan de verrijkingspijplijn toegevoegd voor gebruik door de Cognitive Search-service.
Er worden twee gegevenssets geboden. Als u het model zelf wilt trainen, hebt u het bestand hotel_reviews_1000.csv nodig. Slaat u de trainingsstap liever over? Download dan het bestand hotel_reviews_100.csv.
- Een Azure Cognitive Search-exemplaar maken
- Een Azure Machine Learning-werkruimte maken (de zoekservice en werkruimte dienen in hetzelfde abonnement te zitten)
- Een model trainen en implementeren in een Azure Kubernetes-cluster
- Een AI-verrijkingspijplijn koppelen aan het geïmplementeerde model
- Uitvoer van het geïmplementeerde model als een aangepaste vaardigheid opnemen
Belangrijk
Deze vaardigheid is beschikbaar in de openbare preview onder aanvullende gebruiksvoorwaarden. De preview-REST API ondersteunt deze vaardigheid.
Vereisten
- Azure-abonnement – krijg een gratis abonnement.
- Cognitive Search-service
- Cognitive Services-resource
- Azure Storage-account)
- Azure Machine Learning-werkruimte
Instellen
- Kloon of download de inhoud van de voorbeeldopslagplaats.
- Extraheer de inhoud als de download een ZIP-bestand is. Zorg ervoor dat de bestanden lezen-schrijven zijn.
- Terwijl u de Azure-accounts en -services instelt, kopieert u de namen en sleutels naar een gemakkelijk toegankelijk tekstbestand. De namen en sleutels worden toegevoegd aan de eerste cel in het notebook waar variabelen voor toegang tot de Azure-services zijn gedefinieerd.
- Als u niet bekend bent met Azure Machine Learning en de vereisten daarvan, is het raadzaam deze documenten te bekijken voordat u aan de slag gaat:
- Een ontwikkelingsomgeving voor Azure Machine Learning configureren
- Azure Machine Learning-werkruimten maken en beheren in de Azure-portal
- Wanneer u de ontwikkelingsomgeving voor Azure Machine Learning configureert, overweeg dan het cloudgebaseerd rekenproces te gebruiken om snel en gemakkelijk aan de slag te gaan.
- Upload het gegevenssetbestand naar een container in het opslagaccount. Het grotere bestand is nodig als u de trainingsstap in het notebook wilt uitvoeren. Als u de trainingsstap liever overslaat, wordt het kleinere bestand aanbevolen.
Notebook openen en verbinding maken met Azure-services
- Zet alle benodigde informatie voor de variabelen die toegang tot de Azure-services zullen geven in de eerste cel en voer de cel uit.
- Als u de tweede cel uitvoert, wordt bevestigd dat u verbinding hebt gemaakt met de zoekservice voor uw abonnement.
- In sectie 1.1 t/m 1.5 worden het gegevensarchief, de vaardighedenset, de index en de indexeerfunctie van de zoekservice gemaakt.
Op dit punt kunt u ervoor kiezen de stappen voor het maken van de trainingsgegevensset en het experiment in Azure Machine Learning over te slaan en direct door te gaan met het registreren van de twee modellen die in de map Modellen van de GitHub-opslagplaats staan. Als u deze stappen overslaat, gaat u in het notebook door naar sectie 3.5, Een scorescript schrijven. Dit zal tijd besparen; de stappen voor gegevensdownload en -upload kunnen wel 30 minuten duren.
De modellen maken en trainen
Sectie 2 bevat zes cellen waarmee het GloVe Embeddings-bestand wordt gedownload uit de opslagplaats met NLP-recepten. Nadat het bestand is gedownload, wordt het geüpload naar het Azure Machine Learning-gegevensarchief. Het ZIP-bestand is ongeveer 2 GB en het zal wat tijd kosten om deze taken uit te voeren. Zodra het bestand is geüpload, worden de trainingsgegevens geëxtraheerd, waarna u door kunt gaan naar sectie 3.
Het model voor aspectgebaseerd sentiment trainen en uw eindpunt implementeren
In sectie 3 van het notebook worden de modellen getraind die in sectie 2 zijn gemaakt, worden die modellen geregistreerd en worden ze als een eindpunt geïmplementeerd in een Azure Kubernetes-cluster. Als u niet bekend bent met Azure Kubernetes, is het zeer raadzaam de volgende artikelen te bekijken voordat u een deductiecluster probeert te maken:
- Overzicht van Azure Kubernetes Service
- Kubernetes-kernconcepten voor Azure Kubernetes Service (AKS)
- Quota’s, groottebeperkingen voor virtuele machines, en beschikbaarheid in regio’s in Azure Kubernetes Service (AKS)
Het maken en implementeren van de deductiecluster kan wel 30 minuten duren. Het wordt aanbevolen de webservice te testen voordat u doorgaat met de laatste stappen, uw vaardighedenset bij te werken en de indexeerfunctie uit te voeren.
De vaardighedenset bijwerken
Sectie 4 in het notebook heeft vier cellen waarmee de vaardighedenset en indexeerfunctie worden bijgewerkt. U kunt ook de portal gebruiken om de nieuwe vaardigheid te selecteren en op de vaardighedenset toe te passen en vervolgens de indexeerfunctie uitvoeren om de zoekservice bij te werken.
Ga in de portal naar ‘Vaardighedenset’ en selecteer de koppeling ‘Definitie van vaardighedenset (JSON)’. De portal toont de JSON van uw vaardighedenset die in de eerste cellen van het notebook is gemaakt. Rechts daarvan staat een vervolgkeuzemenu waarin u het sjabloon voor definitie van vaardighedenset kunt selecteren. Selecteer het sjabloon ‘Azure Machine Learning (AML)’. Geef de naam op van de Azure ML-werkruimte en het eindpunt voor het model dat in de deductiecluster wordt geïmplementeerd. Het sjabloon wordt bijgewerkt met de eindpunt-URI en -sleutel.
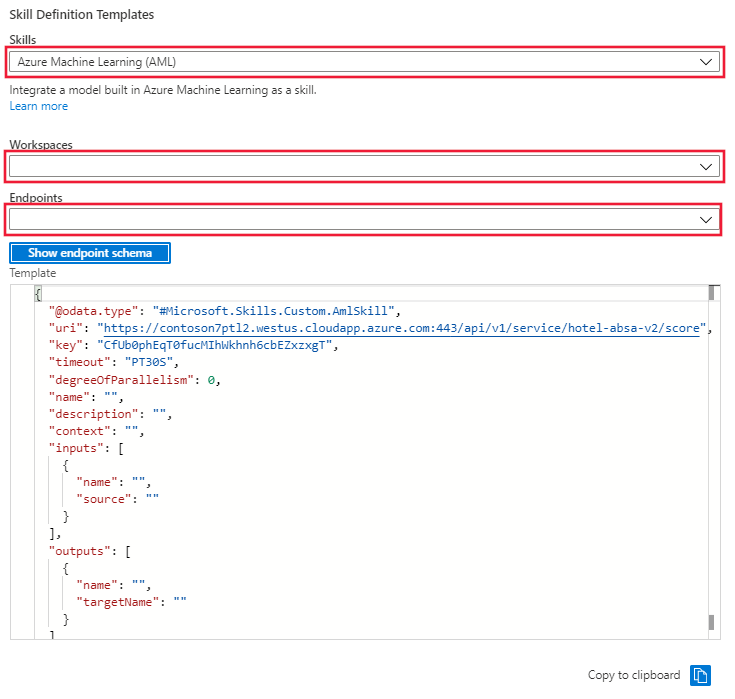
Kopieer het vaardighedensetsjabloon uit het venster en plak het in de vaardighedensetdefinitie aan de linkerkant. Bewerk het sjabloon om de ontbrekende waarden op te geven voor:
- Naam
- Beschrijving
- Context
- 'invoer' naam en bron
- 'uitvoer' naam en TargetName
Sla de vaardighedenset op.
Nadat u de vaardighedenset hebt opgeslagen, gaat u naar de indexeerfunctie en selecteert u de koppeling ‘Definitie van de indexeerfunctie (JSON)’. De portal toont de JSON van de indexeerfunctie die in de eerste cellen van het notebook is gemaakt. De uitvoerveldtoewijzingen moeten worden bijgewerkt met aanvullende veldtoewijzingen om te verzekeren dat de indexeerfunctie ze correct kan verwerken en doorgeven. Sla de wijzigingen op en selecteer vervolgens ‘Uitvoeren’.
Resources opschonen
Wanneer u in uw eigen abonnement werkt, is het een goed idee om aan het einde van een project te bepalen of u de gemaakte resources nog steeds nodig hebt. Resources die actief blijven, kunnen u geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in de portal via de koppeling Alle resources of Resourcegroepen in het navigatiedeelvenster aan de linkerkant.
Als u een gratis service gebruikt, moet u er rekening mee houden dat u bent beperkt tot drie indexen, indexeerfuncties en gegevensbronnen. U kunt afzonderlijke items in de portal verwijderen om onder de limiet te blijven.