Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Data Science | Beveiliging en vertrouwen van klanten |
| Microsoft | Microsoft |
Abstract: het identificeren van beveiligingsfoutrapporten (SBR's) is een essentiële stap in de levenscyclus van softwareontwikkeling. Bij benaderingen op basis van machine learning onder supervisie is het gebruikelijk om ervan uit te gaan dat volledige foutrapporten beschikbaar zijn voor training en dat hun labels ruisvrij zijn. Naar onze beste kennis is dit de eerste studie om te laten zien dat nauwkeurige labelvoorspelling mogelijk is voor SDR's, zelfs wanneer alleen de titel beschikbaar is en in aanwezigheid van labelruis.
Indextermen: Machine Learning, onjuiste etikettering, ruis, beveiligingsfoutrapport, foutenopslagplaatsen
Ik. INTRODUCTIE
Het identificeren van beveiligingsproblemen tussen gerapporteerde bugs is een dringende behoefte aan softwareontwikkelingsteams, zoals problemen, vragen om snellere oplossingen om te voldoen aan de nalevingsvereisten en de integriteit van de software- en klantgegevens te waarborgen.
Machine learning en hulpprogramma's voor kunstmatige intelligentie beloven de softwareontwikkeling sneller, flexibel en correct te maken. Verschillende onderzoekers hebben machine learning toegepast op het probleem van het identificeren van beveiligingsfouten [2], [7], [8], [18]. Uit eerdere gepubliceerde studies is ervan uitgegaan dat het hele bugrapport beschikbaar is voor het trainen en scoren van een machine learning-model. Dit is niet noodzakelijkerwijs het geval. Er zijn situaties waarin het hele foutenrapport niet beschikbaar kan worden gesteld. Het foutenrapport kan bijvoorbeeld wachtwoorden bevatten, persoonlijke identificatiegegevens (PII) of andere soorten gevoelige gegevens. Dit is een geval dat we momenteel bij Microsoft tegenkomen. Het is daarom belangrijk om vast te stellen hoe goed de identificatie van beveiligingsfouten kan worden uitgevoerd met minder informatie, bijvoorbeeld wanneer alleen de titel van het foutenrapport beschikbaar is.
Daarnaast bevatten foutopslagplaatsen vaak verkeerd gelabelde vermeldingen [7]: niet-beveiligingsfoutrapporten die zijn geclassificeerd als beveiligingsgerelateerd en omgekeerd. Er zijn verschillende redenen voor het optreden van verkeerd labelen, variërend van het gebrek aan expertise van het ontwikkelingsteam op het gebied van beveiliging, tot de scherpte van bepaalde problemen, bijvoorbeeld dat er niet-beveiligingsfouten op een indirecte manier worden misbruikt om een beveiligingsimplicatie te veroorzaken. Dit is een ernstig probleem omdat het verkeerd labelen van SBR's resulteert in beveiligingsexperts die handmatig een foutdatabase moeten controleren in een dure en tijdrovende inspanning. Begrijpen hoe ruis van invloed is op verschillende classificaties en hoe robuuste (of kwetsbare) verschillende machine learning-technieken aanwezig zijn in aanwezigheid van gegevenssets die besmet zijn met verschillende soorten ruis, is een probleem dat moet worden aangepakt om automatische classificatie toe te passen aan de praktijk van software-engineering.
Voorlopig werk betoogt dat foutopslagplaatsen intrinsiek luidruchtig zijn en dat de ruis een nadelig effect kan hebben op de prestatie-machine learning-classificaties [7]. Er ontbreekt echter een systematische en kwantitatieve studie van de manier waarop verschillende niveaus en soorten ruis van invloed zijn op de prestaties van verschillende machine learning-algoritmen onder supervisie voor het probleem van het identificeren van beveiligingsfoutrapporten (SRB's).
In deze studie laten we zien dat de classificatie van foutrapporten kan worden uitgevoerd, zelfs wanneer alleen de titel beschikbaar is voor training en scoren. Voor zover wij weten, is dit het allereerste werk dat dit doet. Daarnaast bieden we de eerste systematische studie van het effect van ruis in de classificatie van foutenrapporten. We maken een vergelijkende studie van de robuustheid van drie machine learning-technieken (logistieke regressie, naïve Bayes en AdaBoost) tegen klasse-onafhankelijke ruis.
Hoewel er enkele analytische modellen zijn die de algemene invloed van ruis voor enkele eenvoudige classificaties vastleggen [5], [6], bieden deze resultaten geen strikte grenzen aan het effect van de ruis op precisie en zijn ze alleen geldig voor een bepaalde machine learning-techniek. Een nauwkeurige analyse van het effect van ruis in machine learning-modellen wordt meestal uitgevoerd door rekenkundige experimenten uit te voeren. Dergelijke analyses zijn uitgevoerd voor verschillende scenario's, variërend van softwaremetingsgegevens [4], tot satellietbeeldclassificatie [13] en medische gegevens [12]. Deze resultaten kunnen echter niet worden vertaald naar ons specifieke probleem, vanwege de hoge afhankelijkheid van de aard van de gegevenssets en het onderliggende classificatieprobleem. Voor zover wij weten, zijn er geen gepubliceerde resultaten over het effect van gegevenssets met ruis op de classificatie van rapporten over beveiligingsfouten in het bijzonder.
ONZE ONDERZOEKSBIJDRAGEN:
We trainen classificaties voor de identificatie van beveiligingsfoutrapporten (SBR's) uitsluitend op basis van de titel van de rapporten. Voor zover wij weten is dit de eerste keer dat dit wordt gedaan. Eerdere werken gebruikten het volledige foutrapport of verbeterden het foutrapport met aanvullende functies. Het classificeren van bugs op basis van de tegel is met name relevant wanneer de volledige foutrapporten niet beschikbaar kunnen worden gesteld vanwege privacyproblemen. Het is bijvoorbeeld berucht dat foutenrapporten wachtwoorden en andere gevoelige gegevens bevatten.
We bieden ook de eerste systematische studie van de labelruistolerantie van verschillende machine learning-modellen en technieken die worden gebruikt voor de automatische classificatie van SBR's. We maken een vergelijkende studie van robuustheid van drie afzonderlijke machine learning-technieken (logistieke regressie, naïve Bayes en AdaBoost) tegen klasseafhankelijke en klasse-onafhankelijke ruis.
De rest van het document wordt als volgt gepresenteerd: in sectie II presenteren we enkele van de vorige werken in de literatuur. In sectie III beschrijven we de gegevensset en hoe gegevens vooraf worden verwerkt. De methodologie wordt beschreven in sectie IV en de resultaten van onze experimenten die in sectie V worden geanalyseerd. Ten slotte worden onze conclusies en toekomstige werken gepresenteerd in VI.
II. VORIGE WERKEN
Toepassingen van machine learning voor bugrepositories.
Er bestaat uitgebreide literatuur over het toepassen van tekstanalyse, verwerking van natuurlijke taal en machine learning op foutopslagplaatsen in een poging om arbeidsintensische taken zoals detectie van beveiligingsfouten [2], [7], [8], [18], dubbele identificatie van fouten [3], foutsorteerd [1], [11] te automatiseren om een paar toepassingen te noemen. Idealiter vermindert het huwelijk van machine learning (ML) en verwerking van natuurlijke taal mogelijk het handmatige werk dat nodig is voor het cureren van foutdatabases, verkort de vereiste tijd voor het uitvoeren van deze taken en kan de betrouwbaarheid van de resultaten verhogen.
In [7] stellen de auteurs een model voor natuurlijke taal voor om de classificatie van SBR's te automatiseren op basis van de beschrijving van de fout. De auteurs halen een woordenlijst op uit alle foutbeschrijvingen in de trainingsgegevensset en cureren deze handmatig in drie lijsten met woorden: relevante woorden, stopwoorden (veelvoorkomende woorden die niet relevant lijken voor classificatie) en synoniemen. Ze vergelijken de prestaties van beveiligingsfoutclassificatie die is getraind op gegevens die allemaal worden geëvalueerd door beveiligingstechnici en een classificatie die is getraind op gegevens die zijn gelabeld door foutrapporteurs in het algemeen. Hoewel hun model duidelijk effectiever is bij het trainen van gegevens die door beveiligingstechnici worden beoordeeld, is het voorgestelde model gebaseerd op een handmatig afgeleide vocabulaire, waardoor het afhankelijk is van menselijke curatie. Bovendien is er geen analyse van hoe verschillende niveaus van ruis van invloed zijn op hun model, hoe verschillende classificaties reageren op ruis en of ruis in beide klassen de prestaties verschillend beïnvloedt.
Zou et. al [18] maken gebruik van meerdere soorten informatie in een foutrapport waarbij de niet-tekstuele velden van een bugrapport worden betrokken (metafuncties, bijvoorbeeld tijd, ernst en prioriteit) en de tekstuele inhoud van een foutrapport (tekstuele functies, de tekst in samenvattingsvelden). Op basis van deze functies bouwen ze een model om de SBR's automatisch te identificeren via verwerking van natuurlijke taal en machine learning-technieken. In [8] voeren de auteurs een vergelijkbare analyse uit, maar daarnaast vergelijken ze de prestaties van machine learning-technieken onder supervisie en zonder supervisie en bestuderen ze hoeveel gegevens er nodig zijn om hun modellen te trainen.
In [2] verkennen de auteurs ook verschillende machine learning-technieken om bugs te classificeren als SBR's of NSBRs (Non-Security Bug Report) op basis van hun beschrijvingen. Ze stellen een pijplijn voor gegevensverwerking en modeltraining voor op basis van TFIDF. Ze vergelijken de voorgestelde pijplijn met een model op basis van bag-of-words en naïef Bayes. Wijayasekara et al. [16] gebruikte ook tekstanalysetechnieken om de functievector van elk bugrapport te genereren op basis van frequente woorden om Verborgen impact bugs (HIBs) te identificeren. Yang et al. [17] beweerde dat ze foutenrapporten met hoge impact (bijvoorbeeld SDR's) met behulp van Term Frequency (TF) en naïve Bayes identificeerden. In [9] stellen de auteurs een model voor om de ernst van een bug te voorspellen.
LABELGELUID
Het probleem van het omgaan met gegevenssets met labelruis is uitgebreid bestudeerd. Frenay en Verleysen stellen in [6] een labelruistaxonomie voor om verschillende soorten ruislabels te onderscheiden. De auteurs stellen drie verschillende soorten ruis voor: labelruis die onafhankelijk van de werkelijke klasse plaatsvindt en van de waarden van de instantiefuncties; labelruis die alleen afhankelijk is van het ware label; en labelruis waarbij de kans op verkeerd labelen ook afhankelijk is van de functiewaarden. In ons werk bestuderen we de eerste twee soorten ruis. Vanuit theoretisch oogpunt vermindert labelruis meestal de prestaties van een model [10], behalve in sommige specifieke gevallen [14]. Over het algemeen zijn robuuste methoden afhankelijk van het vermijden van overfitting om labelgeluid te verwerken [15]. De studie van geluidseffecten in classificatie is eerder gedaan op veel gebieden zoals satellietafbeeldingsclassificatie [13], classificatie van softwarekwaliteit [4] en classificatie van medische domeinen [12]. Naar onze beste kennis zijn er geen gepubliceerde werken die de precieze kwantificering bestuderen van de effecten van ruislabels in het probleem van classificatie van SBR's. In dit scenario is de precieze relatie tussen ruisniveaus, ruistypen en prestatievermindering niet vastgesteld. Bovendien is het de moeite waard om te begrijpen hoe verschillende classificaties zich gedragen in aanwezigheid van ruis. Over het algemeen zijn we niet op de hoogte van werk dat systematisch het effect van ruisgegevenssets onderzoekt op de prestaties van verschillende machine learning-algoritmen in de context van softwarefoutrapporten.
III. BESCHRIJVING VAN DATASET
Onze gegevensset bestaat uit 1.073.149 fouttitels, waarvan 552.073 overeenkomen met SBR's en 521.076 aan NSBR's. De gegevens zijn verzameld van verschillende teams in Microsoft in de jaren 2015, 2016, 2017 en 2018. Alle labels zijn verkregen door bugs te verifiëren met systemen op basis van handtekeningen of zijn door mensen gelabeld. Fouttitels in onze gegevensset zijn zeer korte teksten, met ongeveer 10 woorden, met een overzicht van het probleem.
Een. Gegevens vooraf verwerken We parseren elke bugtitel door de lege spaties, wat resulteert in een lijst met tokens. We verwerken elke lijst met tokens als volgt:
Alle tokens verwijderen die bestandspaden zijn
Gesplitste tokens waarin de volgende symbolen aanwezig zijn: { , (, ), -, }, {, [, ], }
Verwijder stopwoorden, tokens die bestaan uit alleen numerieke tekens en tokens die minder dan 5 keer voorkomen in het hele corpus.
IV. METHODOLOGIE
Het proces van het trainen van onze machine learning-modellen bestaat uit twee hoofdstappen: het coderen van de gegevens in functievectoren en het trainen van machine learning-classificaties onder supervisie.
Een. Functievectoren en Machine Learning-technieken
Het eerste deel omvat het coderen van gegevens in functievectoren met behulp van het term frequencyinverse documentfrequentie-algoritme (TF-IDF), zoals gebruikt in [2]. TF-IDF is een techniek voor het ophalen van gegevens die een termenfrequentie (TF) en de inverse documentfrequentie (IDF) wegen. Elk woord of elke term heeft zijn respectieve TF- en IDF-score. Het TF-IDF algoritme wijst het belang van dat woord toe op basis van het aantal keren dat het in het document wordt weergegeven, en belangrijker nog, het controleert hoe relevant het trefwoord is in de verzameling titels in de gegevensset. We hebben drie classificatietechnieken getraind en vergeleken: naïve Bayes (NB), versterkte beslissingsstructuren (AdaBoost) en logistieke regressie (LR). We hebben deze technieken gekozen omdat ze goed zijn gebleken voor de gerelateerde taak om beveiligingsfoutrapporten te identificeren op basis van het hele rapport in de literatuur. Deze resultaten werden bevestigd in een voorlopige analyse waarbij deze drie classificaties beter presteerden dan ondersteuningsvectormachines en willekeurige forests. In onze experimenten gebruiken we de scikit-learn-bibliotheek voor codering en modeltraining.
B. Soorten ruis
Het geluid dat in dit werk wordt bestudeerd, verwijst naar ruis in het klasselabel in de trainingsgegevens. In de aanwezigheid van zulk geluid worden als gevolg daarvan het leerproces en het resulterende model aangetast door verkeerd gelabelde voorbeelden. We analyseren de impact van verschillende ruisniveaus die zijn toegepast op de klasse-informatie. Typen labelruis zijn eerder in de literatuur besproken met behulp van verschillende terminologie. In ons werk analyseren we de effecten van twee verschillende labelruis in onze classificaties: klasse-onafhankelijke labelruis, die wordt geïntroduceerd door willekeurig exemplaren te kiezen en hun label te spiegelen; en klasseafhankelijke ruis, waarbij klassen een andere kans hebben om lawaaierig te zijn.
a) klasse-onafhankelijke ruis: klasse-onafhankelijke ruis verwijst naar de ruis die onafhankelijk van de werkelijke klasse van de exemplaren plaatsvindt. In dit type ruis is de kans op verkeerd labelen pbr hetzelfde voor alle exemplaren in de gegevensset. We introduceren klasse-onafhankelijke ruis in onze databestanden door elk label in ons databestand willekeurig om te draaien met waarschijnlijkheid pbr.
b) klasseafhankelijke ruis: klasseafhankelijke ruis verwijst naar de ruis die afhankelijk is van de werkelijke klasse van de exemplaren. In dit type ruis is de kans op verkeerd labelen in klasse SBR, psbr, en de kans op verkeerd labelen in klasse NSBR pnsbr. We introduceren klasseafhankelijke ruis in onze gegevensset door elke invoer in de gegevensset te veranderen waarvoor het werkelijke label SBR is met waarschijnlijkheid psbr. Op een vergelijkbare manier spiegelen wij het klasselabel van NSBR-exemplaren met waarschijnlijkheid pnsbr.
c) Single-class ruis: Single-class ruis is een specifiek geval van klasseafhankelijke ruis, waarbij pnsbr = 0 en psbr> 0. Let op: voor klasse-onafhankelijke ruis hebben we psbr = pnsbr = pbr.
C. Ruis genereren
Onze experimenten onderzoeken de impact van verschillende ruistypen en niveaus bij de training van SBR-classificatoren. In onze experimenten stellen we 25% van de gegevensset in als testgegevens, 10% als validatie en 65% als trainingsgegevens.
We voegen ruis toe aan de trainings- en validatiegegevenssets voor verschillende niveaus pbr, psbr en pnsbr . We brengen geen wijzigingen aan in de testgegevensset. De verschillende gebruikte ruisniveaus zijn P = {0,05 × i|0 < i < 10}.
In klasse-onafhankelijke ruisexperimenten, voor pbr ∈ P doen we het volgende:
Ruis toevoegen aan trainings- en validatiedatasets.
Train de logistieke regressie, naïef Bayes- en AdaBoost-modellen met behulp van de trainingsgegevensset (met ruis). Stem de modellen af met de validatiegegevensset (met ruis).
Test modellen met behulp van een testgegevensset (ruisloos).
In klasseafhankelijke ruisexperimenten, voor psbr ∈ P en pnsbr ∈ P doen we het volgende voor alle combinaties van psbr en pnsbr:
Ruis toevoegen aan trainings- en validatiedatasets.
Trainen van logistische regressie-, naïeve Bayes- en AdaBoost-modellen met behulp van trainingsdataset (met ruis);
Modellen afstemmen met behulp van validatiegegevensset (met ruis);
Test modellen met behulp van een testgegevensset (ruisloos).
V. EXPERIMENTELE RESULTATEN
In deze sectie analyseert u de resultaten van experimenten die worden uitgevoerd volgens de methodologie die in sectie IV is beschreven.
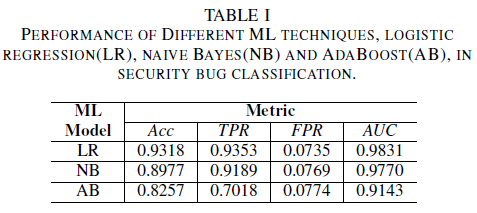
a) Modelprestaties zonder ruis in de trainingsgegevensset: een van de bijdragen van dit document is het voorstel van een machine learning-model om beveiligingsfouten te identificeren door alleen de titel van de bug te gebruiken als gegevens voor besluitvorming. Dit maakt het mogelijk om machine learning-modellen te trainen, zelfs als ontwikkelteams geen foutenrapporten volledig willen delen vanwege aanwezigheid van gevoelige gegevens. We vergelijken de prestaties van drie machine learning-modellen wanneer ze worden getraind met alleen fouttitels.
Het logistieke regressiemodel is de best presterende classificatie. Het is de classifier met de hoogste AUC-waarde van 0,9826, en een recall van 0,9353 voor een FPR-waarde van 0,0735. De naïve Bayes-classificatie presenteert iets lagere prestaties dan de logistieke regressieclassificatie, met een AUC van 0,9779 en een terugroeping van 0,9189 voor een FPR van 0,0769. De AdaBoost-classificator heeft een inferieure prestatie in vergelijking met de twee eerder genoemde classificatoren. Het bereikt een AUC van 0,9143 en een recallwaarde van 0,7018 bij een FPR van 0,0774. Het gebied onder de ROC-curve (AUC) is een goede meetwaarde voor het vergelijken van de prestaties van verschillende modellen, zoals deze samenvat in één waarde de TPR versus FPR-relatie. In de volgende analyse beperken we onze vergelijkende analyse tot AUC-waarden.
Een. Ruis: één klasse
U kunt zich een scenario voorstellen waarin alle fouten standaard worden toegewezen aan klasse NSBR en een fout alleen wordt toegewezen aan klasse SBR als er een beveiligingsexpert is die de foutopslagplaats controleert. Dit scenario wordt weergegeven in de experimentele instelling van een enkele klasse, waarbij we ervan uitgaan dat pnsbr = 0 en 0 < psbr< 0,5.
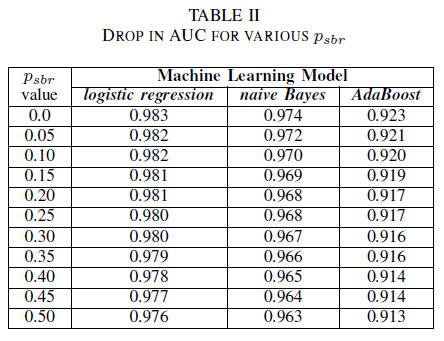
In tabel II zien we een zeer kleine impact in de AUC voor alle drie de classificaties. De AUC-ROC van een model dat is getraind op psbr = 0 in vergelijking met een AUC-ROC van het model waarbij psbr = 0,25 verschilt met 0,003 voor logistieke regressie, 0,006 voor naïve Bayes en 0,006 voor AdaBoost. In het geval van psbr = 0,50 verschilt de AUC voor elk van de modellen van het model dat is getraind met psbr = 0 bij 0,007 voor logistieke regressie, 0,011 voor naïve Bayes en 0,010 voor AdaBoost. Logistieke regressieclassificatie die is getraind in aanwezigheid van ruis van één klasse geeft de kleinste variatie in de AUC-meetwaarde, d.w.z. een robuuster gedrag, in vergelijking met onze naïve Bayes- en AdaBoost-classificaties.
B. Klasseruis: klasse-onafhankelijk
We vergelijken de prestaties van onze drie classificatoren voor het geval dat de trainingsset beschadigd is door klasse-onafhankelijke ruis. We meten de AUC voor elk model dat is getraind met verschillende niveaus pbr in de trainingsgegevens.
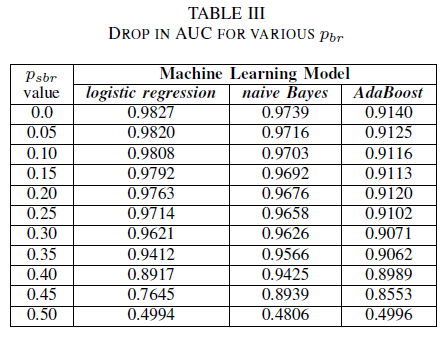
In tabel III zien we een afname in de AUC-ROC voor elke toename van ruis in het experiment. De AUC-ROC gemeten van een model dat is getraind op ruisloze gegevens vergeleken met een AUC-ROC van het model dat is getraind met klasse-onafhankelijke ruis met pbr = 0,25 verschilt met 0,011 voor logistieke regressie, 0,008 voor naïve Bayes en 0,0038 voor AdaBoost. We zien dat labelruis geen invloed heeft op de AUC van naïve Bayes- en AdaBoost-classificaties wanneer de ruisniveaus lager zijn dan 40%. Aan de andere kant ondervindt de logistieke regressieclassificator een impact op de AUC-meting bij labelruisniveaus boven de 30%.
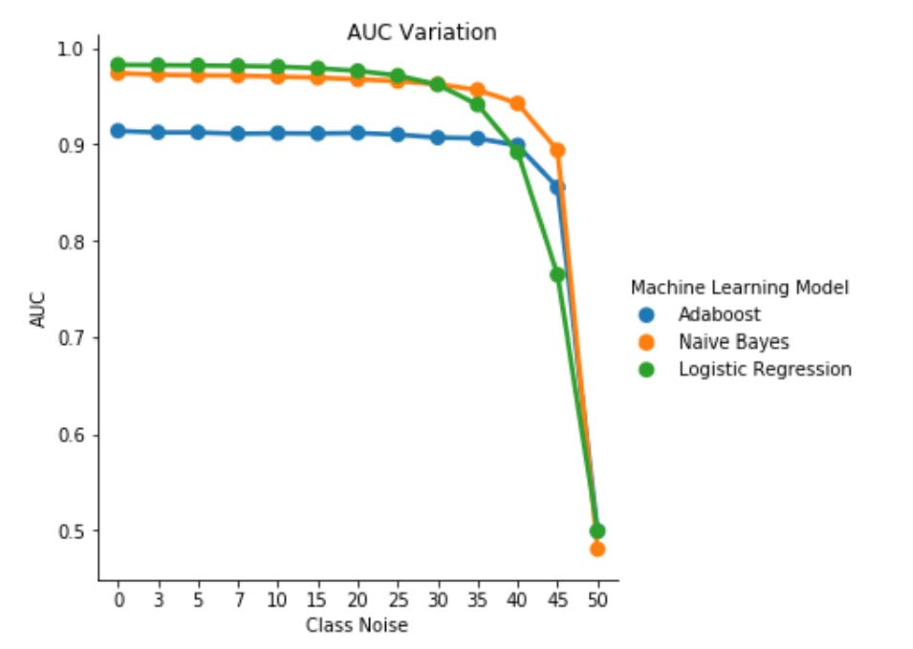
Afb. 1. Variatie van AUC-ROC in klasse-onafhankelijke ruis. Voor een ruisniveau pbr =0,5 fungeert de classificatie als een willekeurige classificatie, d.w.w.v. AUC≈0,5. We kunnen echter zien dat voor lagere ruisniveaus (pbr ≤0,30) de logistieke regressie-leerling beter presteert in vergelijking met de andere twee modellen. Voor 0,35≤ pbr ≤0,45 presenteert het naïve Bayes-model echter betere AUCROC-metrieken.
C. Geluidsstoring per klasse: klasse-afhankelijk
In de laatste reeks experimenten beschouwen we een scenario waarin verschillende klassen verschillende ruisniveaus bevatten, d.w.z. psbr ≠ pnsbr-. We verhogen psbr en pnsbr onafhankelijk met 0,05 in de trainingsgegevens en observeren de verandering in het gedrag van de drie classificatoren.
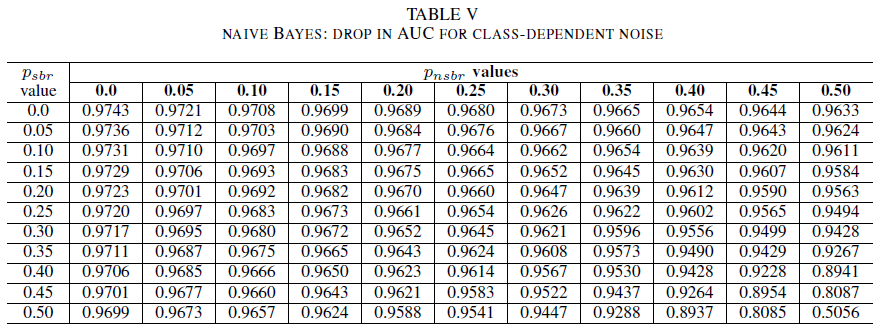
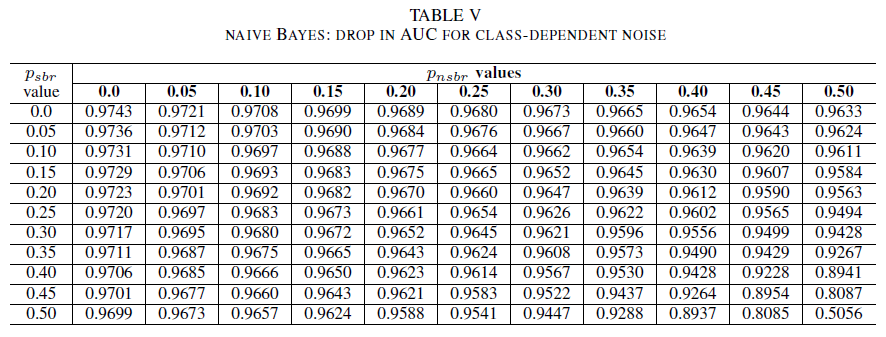
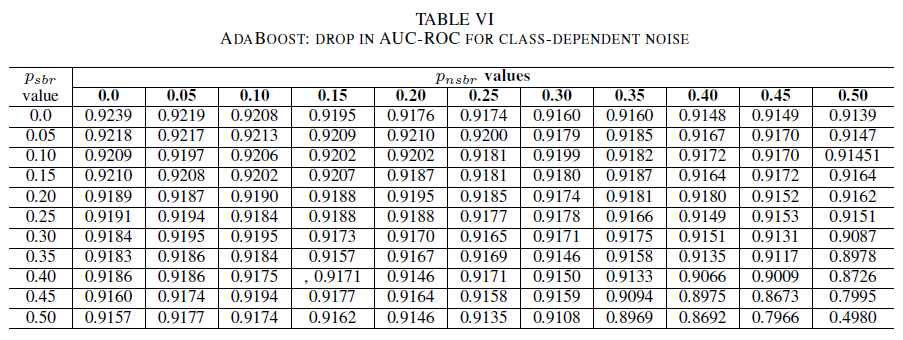
Tabellen IV, V en VI tonen de variatie van de AUC naarmate ruis in verschillende niveaus in elke klasse wordt verhoogd: in Tabel IV voor logistieke regressie, in Tabel V voor naïeve Bayes en in Tabel VI voor AdaBoost. Voor alle classificaties zien we een impact in de AUC-meetwaarde wanneer beide klassen een ruisniveau van meer dan 30%bevatten. Naïve Bayes gedraagt zich het meest robuust. De impact op AUC is erg klein, zelfs wanneer de 50% van het label in de positieve klasse worden gespiegeld, mits de negatieve klasse 30% van ruislabels of minder bevat. In dit geval is de daling in AUC 0,03. AdaBoost heeft het meest robuuste gedrag van alle drie de classificaties gepresenteerd. Een aanzienlijke wijziging in AUC vindt alleen plaats voor ruisniveaus die groter zijn dan 45% in beide klassen. In dat geval beginnen we met het observeren van een AUC-verval groter dan 0,02.
D. Over de aanwezigheid van restruis in de oorspronkelijke gegevensset
Onze gegevensset is gelabeld door geautomatiseerde systemen op basis van handtekeningen en door menselijke experts. Bovendien zijn alle bugsrapporten verder beoordeeld en gesloten door menselijke experts. Hoewel we verwachten dat de hoeveelheid ruis in onze gegevensset minimaal en niet statistisch significant is, maakt de aanwezigheid van restruis onze conclusies niet ongeldig. Inderdaad, ter illustratie gaan we ervan uit dat de oorspronkelijke gegevensset is beschadigd door klasse-onafhankelijke ruis, die gelijk is aan 0 < p < 1/2 en onafhankelijk en identiek verdeeld (i.i.d) is voor elke invoer.
Als we boven op de oorspronkelijke ruis een klasse-onafhankelijke ruis met waarschijnlijkheid pbr i.i.d toevoegen, zal de resulterende ruis per vermelding zijn p∗ = p(1 − pbr )+(1 − p)pbr . Voor 0 < p,pbr< 1/2 hebben we dat de werkelijke ruis per label p∗ strikt groter is dan de ruis die we kunstmatig toevoegen aan de gegevensset pbr . De prestaties van onze classificaties zouden dus nog beter zijn als ze werden getraind met een volledig ruisloze gegevensset (p = 0) in de eerste plaats. Samengevat betekent het bestaan van restruis in de gegevensset dat de tolerantie tegen ruis van onze classificaties beter is dan de resultaten die hier worden gepresenteerd. Als de restruis in onze gegevensset statistisch relevant was, zou de AUC van onze classificaties bovendien 0,5 (een willekeurige schatting) worden voor een niveau van ruis dat strikt minder dan 0,5 is. We observeren dit gedrag niet in onze resultaten.
VI. CONCLUSIES EN TOEKOMSTIGE WERKEN
Onze bijdrage in dit document is tweeledig.
Eerst hebben we de haalbaarheid van classificatie van beveiligingsfoutenrapporten laten zien op basis van de titel van het foutrapport. Dit is met name relevant in scenario's waarin het hele bugrapport niet beschikbaar is vanwege privacybeperkingen. In ons geval bevatten de foutrapporten bijvoorbeeld persoonlijke gegevens, zoals wachtwoorden en cryptografische sleutels, en waren ze niet beschikbaar voor het trainen van de classificaties. Ons resultaat laat zien dat SBR-identificatie met hoge nauwkeurigheid kan worden uitgevoerd, zelfs wanneer alleen rapporttitels beschikbaar zijn. Ons classificatiemodel dat gebruikmaakt van een combinatie van TF-IDF en logistieke regressie voert uit op een AUC van 0,9831.
Ten tweede hebben we het effect van verkeerd gelabelde training en validatiegegevens geanalyseerd. We hebben drie bekende machine learning-classificatietechnieken (naïve Bayes, logistieke regressie en AdaBoost) vergeleken in termen van hun robuustheid tegen verschillende geluidstypen en ruisniveaus. Alle drie de classificaties zijn robuust voor ruis van één klasse. Ruis in de trainingsgegevens heeft geen significant effect in de resulterende classificatie. De afname in AUC is zeer klein (0,01) voor een niveau van ruis van 50%. Voor ruis die in beide klassen aanwezig is en klasse-onafhankelijk is, tonen naïve Bayes- en AdaBoost-modellen alleen significante variaties in de AUC wanneer ze zijn getraind met een dataverzameling met niveaus van ruis die groter zijn dan 40%.
Ten slotte heeft klasseafhankelijke ruis een aanzienlijke invloed op de AUC alleen als er meer dan 35% ruis in beide klassen is. AdaBoost liet de meest robuustheid zien. De impact op de AUC is zeer klein, zelfs wanneer de positieve klasse 50% van zijn labels vervuild heeft, op voorwaarde dat de negatieve klasse 45% vervuilde labels of minder bevat. In dit geval is de daling in AUC kleiner dan 0,03. Naar onze beste kennis is dit de eerste systematische studie over het effect van lawaaierige gegevenssets voor identificatie van beveiligingsfoutenrapporten.
TOEKOMSTIGE WERKEN
In dit document zijn we begonnen met de systematische studie van de effecten van ruis in de prestaties van machine learning-classificaties voor de identificatie van beveiligingsfouten. Er zijn verschillende interessante vervolgen op dit werk, waaronder: het onderzoeken van het effect van ruisgegevenssets bij het bepalen van het ernstniveau van een beveiligingsfout; inzicht krijgen in het effect van klasseonbalans op de tolerantie van de getrainde modellen tegen ruis; inzicht krijgen in het effect van ruis dat adversarial in de gegevensset wordt geïntroduceerd.
VERWIJZINGEN
John Anvik, Lyndon Hiew en Gail C Murphy. Wie moet deze fout oplossen? In de Proceedings van de 28e internationale conferentie over Software Engineering, pagina's 361-370. ACM, 2006.
[2] Diksha Behl, Sahil Handa en Anuja Arora. Een hulpmiddel voor het opsporen en analyseren van beveiligingsfouten met behulp van naïeve bayes en tf-idf. In Optimalisatie, Betrouwbaarheid en Informatietechnologie (ICROIT), Internationale Conferentie van 2014 over, pagina's 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Opgegevenmann en Sunghun Kim. Dubbele foutrapporten beschouwd als schadelijk echt? In Softwareonderhoud, 2008. ICSM 2008. Internationale IEEE-conferentie over, pagina's 337-345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse en Lofton Bullard. Het identificeren van cursisten die robuust zijn voor gegevens van lage kwaliteit. In Gegevens hergebruik en integratie, 2008. IRI 2008. IEEE International Conference on, pagina's 190-195. IEEE, 2008.
[5] Benoît Frenay. Onzekerheid en labelruis in machine learning. PhD-scriptie, Katholieke Universiteit van Leuven, Leuven-la-Neuve, België, 2013.
[6] Benoˆıt Frenay en Michel Verleysen. Classificatie in aanwezigheid van labelruis: een enquête. IEEE-transacties op neurale netwerken en leersystemen, 25(5):845-869, 2014.
[7] Michael Gegick, Pete Rotella en Tao Xie. Beveiligingsfoutrapporten identificeren via tekstanalyse: een industriële casestudy. In Mining softwarearchieven (MSR), tijdens de 7e IEEE-werkconferentie van 2010 over, pagina's 11–20. IEEE, 2010.
Katerina Goseva-Popstojanova en Jacob Tyo. Identificatie van beveiligingsgerelateerde foutrapporten via tekstanalyse met behulp van classificatie onder supervisie en zonder supervisie. Tijdens de 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), pagina's 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger en Bart Goethals. De ernst van een gerapporteerde fout voorspellen. In Mining Software Repositorys (MSR), 2010 7e IEEE Working Conference on, pagina's 1-10. IEEE, 2010.
[10] Naresh Manwani en PS Sastry. Ruistolerantie onder risicominimalisatie. IEEE-transacties over cybernetica, 43(3):1146–1151, 2013.
[11] G Murphy en D Cubranic. Automatische foutortering met behulp van tekstcategorisatie. In De Zestiende Internationale Conferentie over Software Engineering & Kennisengineering. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen en Oleksandr Pechenizkiy. Klasruis en leren onder supervisie in medische domeinen: Het effect van functieextractie. In null, pagina's 708-713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre en Gerard Dedieu. Effect van ruis in trainingsklasselabels op de classificatieprestaties voor het karteriseren van landbedekking met behulp van tijdreeksen van satellietbeelden. Remote Sensing, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra en Naresh Manwani. Een team van continuousaction learning automata voor ruistolerant leren van halve ruimten. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 40(1):19–28, 2010.
[15] Choh-Man Teng. Een vergelijking van technieken voor het verwerken van ruis. In FLAIRS Conference, pagina's 269-273, 2001.
[16] Dumidu Wijayasekara, Milos Manic en Miles McQueen. Identificatie en classificatie van beveiligingsproblemen via bugdatabases voor tekstanalyse. In Industrial Electronics Society, IECON 2014-40e Jaarlijkse Conferentie van de IEEE, pagina's 3612-3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia en Jianling Sun. Geautomatiseerde identificatie van foutenrapporten met hoge impact die gebruikmaken van onevenwichtige leerstrategieën. In Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40e jaarlijkse conferentie, volume 1, pagina's 227-232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li en Hai Jin. Automatisch beveiligingsbugrapporten identificeren via analyse van multidimensionale kenmerken. In Australasian Conference on Information Security and Privacy, pagina's 619-633. Springer, 2018.