Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Door Andrew Marshall, Jugal Parikh, Emre Kiciman en Ram Shankar Siva Kumar
Speciale dank aan Raul Rojas en de AETHER Security Engineering Workstream
November 2019
Dit document is een product van de AETHER Engineering Practices for AI Working Group en vormt een aanvulling op bestaande SDL-bedreigingsmodelleringsprocedures door nieuwe richtlijnen te bieden voor opsomming van bedreigingen en risicobeperking die specifiek zijn voor de AI- en Machine Learning-ruimte. Het is bedoeld om te worden gebruikt als referentie tijdens beveiligingsontwerpbeoordelingen van het volgende:
Producten/services die interactie hebben met of afhankelijkheden nemen van AI/ML-services
Producten/services die worden gebouwd met AI/ML in hun kern
Traditionele risicobeperking voor beveiligingsrisico's is belangrijker dan ooit. De vereisten die door de levenscyclus van security development zijn vastgesteld, zijn essentieel voor het opzetten van een basis voor productbeveiliging waarop deze richtlijnen zijn gebaseerd. Het nalaten van het aanpakken van traditionele beveiligingsrisico's helpt de AI/ML-specifieke aanvallen die in dit document worden behandeld mogelijk maken, zowel in de software- als fysieke domeinen, evenals de integriteit van lager gelegen onderdelen van de softwarestack triviaal in gevaar brengen. Zie De toekomst van AI en ML bij Microsoft beveiligen voor een inleiding tot nieuwe beveiligingsrisico's in deze ruimte.
De vaardighedensets van beveiligingstechnici en gegevenswetenschappers overlappen doorgaans niet. Deze richtlijnen bieden een manier voor beide disciplines om gestructureerde gesprekken te voeren over deze nieuwe bedreigingen/oplossingen zonder dat beveiligingstechnici gegevenswetenschappers hoeven te worden of omgekeerd.
Dit document is onderverdeeld in twee secties:
- 'Belangrijke nieuwe overwegingen bij bedreigingsmodellering' zijn gericht op nieuwe manieren van denken en nieuwe vragen die moeten worden gesteld bij het modelleren van AI/ML-systemen voor bedreigingen. Zowel gegevenswetenschappers als beveiligingstechnici moeten dit beoordelen, omdat dit hun playbook is voor discussie over bedreigingsmodellering en prioriteitstelling voor risicobeperking.
- 'AI/ML-specifieke bedreigingen en hun risicobeperking' bevat details over specifieke aanvallen en specifieke risicobeperkingsstappen die momenteel worden gebruikt om Microsoft-producten en -services te beschermen tegen deze bedreigingen. Deze sectie is voornamelijk gericht op gegevenswetenschappers die mogelijk specifieke bedreigingsbeperkende maatregelen moeten implementeren als uitvoer van het proces voor bedreigingsmodellering/beveiligingsbeoordeling.
Deze richtlijnen zijn georganiseerd rond een Adversarial Machine Learning Threat Taxonomy gemaakt door Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen en Jeffrey Snover getiteld "Failure Modes in Machine Learning." Richtlijnen voor het triëren van beveiligingsrisico's zoals beschreven in dit document zijn te vinden in de SDL-bugbalk voor AI/ML-bedreigingen, waarbij al deze levende documenten zich in de loop van de tijd zullen ontwikkelen met het veranderende bedreigingslandschap.
Belangrijke nieuwe overwegingen bij threat modeling: de manier wijzigen waarop u vertrouwensgrenzen bekijkt
Stel dat zowel de gegevens waarvan u traint als de gegevensprovider in gevaar zijn of vergiftigd zijn geraakt. Meer informatie over het detecteren van afwijkende en schadelijke gegevensvermeldingen en het kunnen onderscheiden en herstellen van gegevens
Samenvatting
Trainingsgegevensarchieven en de systemen die deze hosten, maken deel uit van uw bereik voor threat modeling. De grootste beveiligingsrisico in machine learning is tegenwoordig gegevensvergiftiging vanwege het gebrek aan standaarddetecties en risicobeperking in deze ruimte, gecombineerd met afhankelijkheid van niet-vertrouwde/niet-gecureerde openbare gegevenssets als bronnen van trainingsgegevens. Het bijhouden van de herkomst en afstamming van uw gegevens is essentieel om de betrouwbaarheid ervan te waarborgen en een 'rommel erin, rommel eruit' trainingscyclus te voorkomen.
Vragen om te stellen in een beveiligingsbeoordeling
Als uw gegevens zijn vergiftigd of gemanipuleerd, hoe zou u dat weten?
-Welke telemetrie heeft u om een afwijking in de kwaliteit van uw trainingsgegevens te detecteren?
Traint u van door de gebruiker geleverde invoer?
-Wat voor soort invoervalidatie/opschoning doet u op die inhoud?
-Is de structuur van deze gegevens vergelijkbaar met gegevensbladen voor gegevenssets?
Welke stappen moet u uitvoeren om de beveiliging van de verbinding tussen uw model en de gegevens te waarborgen als u traint op basis van onlinegegevensarchieven?
-Hebben ze een manier om compromissen te melden aan consumenten van hun feeds?
Zijn ze daar zelfs in staat voor?
Hoe gevoelig zijn de gegevens waaruit u traint?
-Catalogiseer u het of bepaalt u het toevoegen/bijwerken/verwijderen van gegevensvermeldingen?
Kan uw model gevoelige gegevens uitvoeren?
-Zijn deze gegevens verkregen met toestemming van de bron?
Levert het model alleen resultaten op die nodig zijn om het doel ervan te bereiken?
Retourneert uw model onbewerkte betrouwbaarheidsscores of andere directe uitvoer die kan worden vastgelegd en gedupliceerd?
Wat is de impact van uw trainingsgegevens die worden hersteld door uw model aan te vallen/om te keren?
Als de betrouwbaarheidsniveaus van de modeluitvoer plotseling afnemen, kunt u achterhalen hoe/waarom en welke gegevens dit hebben veroorzaakt?
Hebt u een goed opgemaakte invoer voor uw model gedefinieerd? Wat doet u om ervoor te zorgen dat de invoer voldoet aan deze indeling en wat doet u als dat niet zo is?
Als uw uitvoer onjuist is, maar er geen fouten worden gerapporteerd, hoe weet u dat?
Weet u of uw trainingsalgoritmen bestendig zijn tegen tegendraadse invoer op een wiskundig niveau?
Hoe herstelt u zich van kwaadaardige beïnvloeding van uw trainingsgegevens?
-Kunt u tegenstrijdige inhoud isoleren/in quarantaine plaatsen en getroffen modellen opnieuw trainen?
-Kunt u terugdraaien naar een model van een eerdere versie voor hertraining?
Gebruikt u Reinforcement Learning voor niet-gecureerde openbare inhoud?
Begin na te denken over de herkomst van uw gegevens. Mocht u een probleem vinden, kunt u het terugvoeren naar het moment van introductie in de dataset? Zo niet, is dat een probleem?
Weet waar uw trainingsgegevens vandaan komen en identificeer statistische normen om te begrijpen hoe afwijkingen eruitzien
-Welke elementen van uw trainingsgegevens zijn kwetsbaar voor externe invloed?
-Wie kan bijdragen aan de gegevenssets waaruit u traint?
-Hoe zou u uw bronnen van trainingsgegevens aanvallen om een concurrent schade te berokkenen?
Verwante bedreigingen en oplossingen in dit document
Adversarial Perturbation (alle varianten)
Gegevensvergiftiging (alle varianten)
Voorbeeldaanvallen
Het afdwingen dat goedaardige e-mailberichten worden geclassificeerd als spam of dat een schadelijk voorbeeld onopgemerkt blijft
Door aanvallers gemaakte invoer die het betrouwbaarheidsniveau van de juiste classificatie verminderen, met name in scenario's met hoge gevolgen
Aanvaller injecteert willekeurig ruis in de brongegevens die worden geclassificeerd om de kans te verminderen dat de juiste classificatie wordt gebruikt in de toekomst, waardoor het model effectief wordt verdarmd
Verontreiniging van trainingsgegevens om de onjuiste classificatie van bepaalde gegevenspunten af te dwingen, wat resulteert in specifieke acties die door een systeem worden uitgevoerd of weggelaten
Identificeer acties die uw model(len) of product/dienst kan uitvoeren, waardoor klanten online of in de fysieke wereld schade kunnen oplopen.
Samenvatting
Als ze niet worden beperkt, kunnen aanvallen op AI/ML-systemen hun weg vinden naar de fysieke wereld. Elk scenario dat kan worden verdraaid om gebruikers psychologisch of fysiek schade toe te brengen, is een catastrofaal risico voor uw product/service. Dit geldt ook voor gevoelige gegevens over uw klanten die worden gebruikt voor het trainen en ontwerpkeuzes die deze privégegevens kunnen lekken.
Vragen om te stellen in een beveiligingsbeoordeling
Traint u met tegenstrijdige voorbeelden? Welke invloed hebben ze op de modeluitvoer in het fysieke domein?
Hoe ziet trolling eruit voor uw product/service? Hoe kunt u deze detecteren en erop reageren?
Wat zou er nodig zijn zodat uw model een resultaat oplevert dat uw dienst ertoe brengt de toegang van legitieme gebruikers te ontzeggen?
Wat is de impact als uw model wordt gekopieerd of gestolen?
Kan uw model worden gebruikt om het lidmaatschap van een individuele persoon in een bepaalde groep af te stellen, of gewoon in de trainingsgegevens?
Kan een aanvaller reputatieschade of PR-backlash naar uw product veroorzaken door deze te dwingen om specifieke acties uit te voeren?
Hoe kunt u correct opgemaakte maar overbevooroorde gegevens verwerken, zoals van trollen?
Voor elke manier waarop u met uw model kunt communiceren of er query's op kunt uitvoeren, kan die methode worden ondervraagd om trainingsgegevens of modelfunctionaliteit te onthullen?
Verwante bedreigingen en oplossingen in dit document
Lidmaatschapsdeductie
Modelinversion
Modeldiefstal
Voorbeeldaanvallen
Reconstructie en extractie van trainingsgegevens door herhaaldelijk een query uit te voeren op het model voor maximale betrouwbaarheidsresultaten
Duplicatie van het model zelf door volledige query-/responskoppeling
Query's uitvoeren op het model op een manier die een specifiek element van persoonlijke gegevens laat zien, is opgenomen in de trainingsset
Zelfrijdende auto wordt bedrogen om stopborden/verkeerslichten te negeren
Gespreksbots gemanipuleerd om goedaardige gebruikers te trollen
Alle bronnen van AI/ML-afhankelijkheden en front-endpresentatielagen in uw gegevens-/modeltoeleveringsketen identificeren
Samenvatting
Veel aanvallen in AI en Machine Learning beginnen met legitieme toegang tot API's die worden weergegeven om querytoegang tot een model te bieden. Vanwege de rijke gegevensbronnen en rijke gebruikerservaringen die hierbij betrokken zijn, vormt geverifieerde maar 'ongepaste' (er is hier een grijs gebied) 3rd-party-toegang tot uw modellen een risico vanwege de mogelijkheid om te dienen als een presentatielaag boven een door Microsoft aangeboden dienst.
Vragen om te stellen in een beveiligingsbeoordeling
Welke klanten/partners worden geverifieerd voor toegang tot uw model- of service-API's?
-Kunnen ze fungeren als een presentatielaag boven op uw service?
-Kunt u de toegang onmiddellijk intrekken in geval van inbreuk?
-Wat is uw herstelstrategie in het geval van kwaadwillend gebruik van uw service of afhankelijkheden?
Kan een 3rd party een gevel rond uw model bouwen om het opnieuw te gebruiken en Microsoft of haar klanten schade te berokkenen?
Bieden klanten rechtstreeks trainingsgegevens aan u?
-Hoe beveiligt u die gegevens?
-Wat als het kwaadaardig is en uw service het doel is?
Hoe ziet een vals-positief er hier uit? Wat is de impact van een vals-negatief?
Kunt u de afwijking van True Positive versus False Positive rates in meerdere modellen bijhouden en meten?
Wat voor soort telemetrie moet u de betrouwbaarheid van uw modeluitvoer bewijzen aan uw klanten?
Identificeer alle 3externe afhankelijkheden in de toeleveringsketen voor ML/Training-gegevens, niet alleen opensourcesoftware, maar ook gegevensproviders
-Waarom gebruikt u ze en hoe verifieert u hun betrouwbaarheid?
Gebruikt u vooraf gebouwde modellen van 3rd party's of verzendt u trainingsgegevens naar MLaaS-providers van 3rd party's?
Inventaris van nieuwsberichten over aanvallen op vergelijkbare producten/services. Begrijpend dat veel AI/ML-bedreigingen worden overgedragen tussen modeltypen, welke impact zouden deze aanvallen hebben op uw eigen producten?
Verwante bedreigingen en oplossingen in dit document
Neurale netwerken herprogrammering
Voorbeelden van adversarial in het fysieke domein
Kwaadwillende ML-aanbieders die trainingsgegevens terughalen
Aanval van de ML-toeleveringsketen
Model met achterdeur
Aangetaste ML-specifieke afhankelijkheden
Voorbeeldaanvallen
Schadelijke MLaaS-provider trojans uw model met een specifieke bypass
Kwaadwillende klant vindt kwetsbaarheid in een veelvoorkomende OSS-afhankelijkheid die u gebruikt en uploadt een geprepareerde gegevensbelasting om uw service te compromitteren.
Unscrupulous partner maakt gebruik van API's voor gezichtsherkenning en maakt een presentatielaag over uw service om Deep Fakes te produceren.
AI/ML-specifieke bedreigingen en hun oplossingen
#1: Tegenstrijdige Verstoring
Beschrijving
Bij perturbation-aanvallen wijzigt de aanvaller op onopvallende wijze de query om een gewenste reactie te krijgen van een in productie geïmplementeerd model[1]. Dit is een schending van modelinvoerintegriteit die leidt tot fuzzing-style aanvallen waarbij het eindresultaat niet noodzakelijkerwijs een toegangsschending of EOP is, maar in plaats daarvan de classificatieprestaties van het model in gevaar brengt. Dit kan ook worden gemanifesteerd door trollen die bepaalde doelwoorden gebruiken op een manier die door de AI wordt verboden, waardoor de service effectief wordt geweigerd aan legitieme gebruikers met een naam die overeenkomt met een 'verboden' woord.
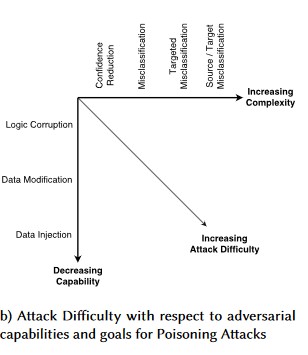 [24]
[24]
Variant #1a: Gerichte misclassificatie
In dit geval genereren aanvallers een voorbeeld dat zich niet in de invoerklasse van de doelclassificatie bevindt, maar wordt geclassificeerd door het model als die specifieke invoerklasse. Het adversariale voorbeeld kan lijken op willekeurige ruis voor menselijke ogen, maar aanvallers hebben enige kennis van het doelmachinelearningsysteem om een white noise te genereren die niet willekeurig is, maar een aantal specifieke aspecten van het doelmodel exploiteert. De kwaadwillende gebruiker geeft een invoervoorbeeld dat geen legitieme steekproef is, maar het doelsysteem classificeert het als een legitieme klasse.
Voorbeelden
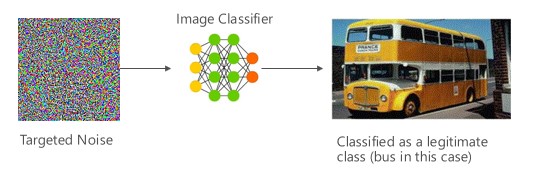 [6]
[6]
Maatregelen
Versterking van de tegenstander-robuustheid met behulp van modelvertrouwen geïnduceerd door tegenstandertraining [19]: De auteurs stellen HCNN (Highly Confident Near Neighbor) voor, een raamwerk dat betrouwbaarheidsinformatie en dichtstbijzijnde buurzoekmethode combineert om de tegenstander-robuustheid van een basismodel te versterken. Dit kan helpen om onderscheid te maken tussen juiste en verkeerde modelvoorspellingen in een buurt van een punt dat is bemonsterd uit de onderliggende trainingsdistributie.
Toeschrijvingsgestuurde causale analyse [20]: de auteurs bestuderen de verbinding tussen de tolerantie voor adversarial perturbaties en de uitleg op basis van toeschrijving van afzonderlijke beslissingen die worden gegenereerd door machine learning-modellen. Ze melden dat adversarial invoer niet robuust is in de attributieruimte. Het maskeren van enkele kenmerken met een hoge toeschrijving leidt tot een verandering in de besluitvorming van het machine learning-model bij de adversariale voorbeelden. De natuurlijke invoer is daarentegen robuust in de toeschrijvingsomgeving.
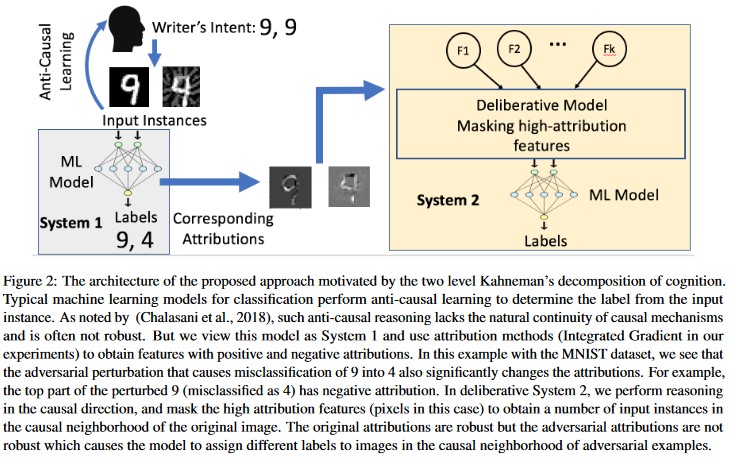 [20]
[20]
Deze benaderingen kunnen machine learning-modellen veerkrachtiger maken tegen tegenwerkende aanvallen, omdat het misleiden van dit tweelaags cognitiesysteem niet alleen vereist dat het oorspronkelijke model aangevallen moet worden, maar ook dat de gegenereerde toewijzing voor het tegenwerkend voorbeeld vergelijkbaar is met de oorspronkelijke voorbeelden. Beide systemen moeten tegelijkertijd worden gecompromitteerd voor een geslaagde adversarial aanval.
Traditionele parallellen
Externe uitbreiding van bevoegdheden omdat aanvaller nu de controle over uw model heeft
Ernstigheid
Kritisch
Variant #1b: misclassificatie van bron/doel
Dit wordt gekenmerkt als een poging van een aanvaller om een model te krijgen om het gewenste label voor een bepaalde invoer te retourneren. Dit dwingt meestal een model om een vals-positief of vals-negatief te retourneren. Het eindresultaat is een subtiele overname van de nauwkeurigheid van de classificatie van het model, waardoor een aanvaller specifieke omleidingen kan veroorzaken.
Hoewel deze aanval een aanzienlijke nadelige invloed heeft op de nauwkeurigheid van de classificatie, kan het ook tijdrovender zijn om uit te voeren, gezien het feit dat een kwaadwillende persoon niet alleen de brongegevens mag manipuleren, zodat deze niet meer correct wordt gelabeld, maar ook specifiek met het gewenste frauduleuze label wordt gelabeld. Deze aanvallen omvatten vaak meerdere stappen/pogingen om misclassificatie af te dwingen [3]. Als het model vatbaar is voor het overdragen van leeraanvallen die gerichte misclassificatie afdwingen, is er mogelijk geen merkbare footprint voor het verkeer van aanvallers omdat de testaanvallen offline kunnen worden uitgevoerd.
Voorbeelden
Het afdwingen dat goedaardige e-mailberichten worden geclassificeerd als spam of waardoor een schadelijk voorbeeld onopgemerkt blijft. Deze worden ook wel modelontduiking of nabootsingsaanvallen genoemd.
Maatregelen
Reactieve/defensieve detectieacties
- Implementeer een minimale tijdsdrempel tussen aanroepen naar de API die classificatieresultaten biedt. Dit vertraagt het testen van aanvallen met meerdere stappen door de totale hoeveelheid tijd te verhogen die nodig is om een geslaagde verstoring te vinden.
Proactieve/beschermende acties
Kenmerkdenoising voor het verbeteren van tegengestelde robuustheid [22]: De auteurs ontwikkelen een nieuwe netwerkarchitectuur die de robuustheid tegen aanvallen verhoogt door het uitvoeren van kenmerkdenoising. De netwerken bevatten met name blokken die de kenmerken met behulp van niet-lokale middelen of andere filters denoiseen; de volledige netwerken worden end-to-end getraind. In combinatie met adversarial training verbeteren functiedenoisingnetwerken aanzienlijk de nieuwste technieken in de adversarial robuustheid in zowel white-box- als black-box-aanvalsscenario's.
Adversarial Training en Regularization: Train met bekende adversarial samples om tolerantie en robuustheid te bouwen tegen schadelijke invoer. Dit kan ook worden gezien als een vorm van regularisatie, die de norm van invoerovergangen bestraft en de voorspellingsfunctie van de classificatie soepeler maakt (waardoor de invoermarge wordt verhoogd). Dit omvat juiste classificaties met lagere betrouwbaarheidspercentages.
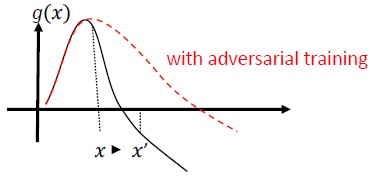
Investeer in het ontwikkelen van monotone classificatie met selectie van monotone functies. Dit zorgt ervoor dat de tegenstander de classificatie niet kan omzeilen door simpelweg kenmerken van de negatieve klasse toe te voegen [13].
Eigenschapcompressie [18] kan worden gebruikt om DNN-modellen te versterken door adversariële voorbeelden te detecteren. Het vermindert de zoekruimte die beschikbaar is voor een kwaadwillende persoon door steekproeven te samenvoegen die overeenkomen met veel verschillende functievectoren in de oorspronkelijke ruimte in één steekproef. Door de voorspelling van een DNN-model op de oorspronkelijke invoer te vergelijken met die op de geperste invoer, kan feature squeezing helpen bij het detecteren van adversarial voorbeelden. Als de oorspronkelijke en geperste voorbeelden aanzienlijk verschillende uitvoer van het model produceren, is de invoer waarschijnlijk oppositioneel. Door het verschil tussen voorspellingen te meten en een drempelwaarde te selecteren, kan het systeem de juiste voorspelling uitvoeren voor legitieme voorbeelden en adversarial invoer weigeren.

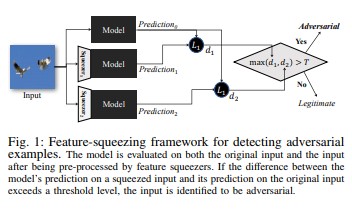 [18]
[18]Certified Defenses against Adversarial Examples [22]: De auteurs stellen een methode voor op basis van een semi-definitieve ontspanning die een certificaat uitvoert dat voor een bepaald netwerk en testinvoer geen aanval kan afdwingen dat de fout een bepaalde waarde overschrijdt. Ten tweede, omdat dit certificaat differentieerbaar is, optimaliseren auteurs het gezamenlijk met de netwerkparameters en bieden ze een adaptieve regularizer die robuustheid tegen alle aanvallen stimuleert.
Antwoordacties
- Waarschuwingen geven voor classificatieresultaten met een hoge variantie tussen classificaties, met name als ze afkomstig zijn van één gebruiker of een kleine groep gebruikers.
Traditionele parallellen
Op afstand verhoging van rechten
Ernstigheid
Kritisch
Variant #1c: Willekeurige misclassificatie
Dit is een speciale variatie waarbij de doelclassificatie van de aanvaller iets anders kan zijn dan de legitieme bronclassificatie. De aanval omvat over het algemeen het willekeurig injecteren van ruis in de brongegevens die worden geclassificeerd om de kans te verminderen dat de juiste classificatie in de toekomst wordt gebruikt [3].
Voorbeelden
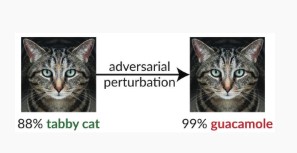
Maatregelen
Hetzelfde als variant 1a.
Traditionele parallellen
Tijdelijke weigering van service
Ernstigheid
Belangrijk
Variant #1d: Betrouwbaarheidsvermindering
Een aanvaller kan invoer maken om het betrouwbaarheidsniveau van de juiste classificatie te verminderen, met name in scenario's met hoge gevolgen. Dit kan ook de vorm aannemen van een groot aantal false positives die bedoeld zijn om beheerders of monitoringsystemen te overbelasten met frauduleuze waarschuwingen die niet te onderscheiden zijn van legitieme waarschuwingen [3].
Voorbeelden

Maatregelen
- Naast de acties die in variant #1a worden behandeld, kan gebeurtenisbeperking worden gebruikt om het aantal waarschuwingen van één bron te verminderen.
Traditionele parallellen
Tijdelijke weigering van service
Ernstigheid
Belangrijk
#2a Gerichte gegevensvergiftiging
Beschrijving
Het doel van de aanvaller is om het machinemodel dat is gegenereerd in de trainingsfase te besmetten, zodat voorspellingen over nieuwe gegevens worden gewijzigd in de testfase[1]. Bij gerichte vergiftigingsaanvallen wil de aanvaller specifieke voorbeelden verkeerd classificeren om ervoor te zorgen dat specifieke acties worden uitgevoerd of weggelaten.
Voorbeelden
Av-software indienen als malware om de misclassificatie als schadelijk af te dwingen en het gebruik van gerichte AV-software op clientsystemen te elimineren.
Maatregelen
Anomaliesensoren instellen om dagelijks de gegevensdistributie te monitoren en waarschuwen bij variaties.
-Meet trainingsgegevensvariatie dagelijks, telemetrie voor scheefheid/drift
Invoervalidatie, zowel opschoning als integriteitscontrole
Vergiftiging beïnvloedt afwijkende trainingsvoorbeelden. Twee belangrijke strategieën voor het counteren van deze bedreiging:
-Gegevens opschonen/valideren: vergiftigingsmonsters verwijderen uit trainingsgegevens -Bagging voor het bestrijden van vergiftigingsaanvallen [14]
-Weigeren-op-Negative-Impact (RONI) bescherming [15]
-Robuust leren: Kies leeralgoritmen die robuust zijn in aanwezigheid van vergiftigingsmonsters.
-Een dergelijke benadering wordt beschreven in [21] waarbij auteurs het probleem van gegevensvergiftiging in twee stappen aanpakken: 1) een nieuwe robuuste matrixfactorisatiemethode introduceren om de echte subruimte te herstellen, en 2) nieuwe robuuste principecomponentregressie om adversarial instanties te verwijderen op basis van de basis die in stap (1) is hersteld. Ze beschrijven de noodzakelijke en voldoende voorwaarden voor het succesvol herstellen van de ware subruimte en presenteren een grens voor het verwachte voorspellingsverlies in vergelijking met de grondwaarheid.
Traditionele parallellen
Trojaned host waarbij aanvaller zich op het netwerk blijft bevinden. Training- of configuratiegegevens zijn gecompromitteerd en worden gebruikt/vertrouwd voor het maken van modellen.
Ernstigheid
Kritisch
#2b Gegevensvergiftiging ondiscrimineren
Beschrijving
Het doel is om de kwaliteit/integriteit van de gegevensset die wordt aangevallen te ruïneren. Veel gegevenssets zijn openbaar/niet-vertrouwd/niet-gecureerd, dus dit zorgt voor extra zorgen over de mogelijkheid om dergelijke schendingen van gegevensintegriteit in de eerste plaats te herkennen. Training van onbewust gecompromitteerde gegevens is een rommel erin, rommel eruit situatie. Zodra dit is gedetecteerd, moet de prioritering de omvang bepalen van gegevens die zijn geschonden en deze in quarantaine plaatsen en opnieuw trainen.
Voorbeelden
Een bedrijf scant een bekende en gerenommeerde website om olietermijncontractgegevens te verkrijgen voor het trainen van hun modellen. De website van de gegevensprovider wordt vervolgens gecompromitteerd via EEN SQL-injectieaanval. De aanvaller kan de gegevensset op elk gewenst moment vergiftigen en het model dat wordt getraind, heeft geen idee dat de gegevens zijn besmet.
Maatregelen
Hetzelfde als variant 2a.
Traditionele parallellen
Geverifieerde authenticatie van een denial-of-service-aanval tegen een waardevol systeem
Ernstigheid
Belangrijk
#3 Modelinversie-aanvallen
Beschrijving
De persoonlijke functies die worden gebruikt in machine learning-modellen kunnen worden hersteld [1]. Dit omvat het reconstrueren van persoonlijke trainingsgegevens waartoe de aanvaller geen toegang heeft. Dit wordt ook wel hill climbing-aanvallen genoemd in de biometrische community [16, 17]. Dit wordt bereikt door de invoer te vinden die het geretourneerde betrouwbaarheidsniveau maximaliseert, waarbij de classificatie moet overeenkomen met het doel [4].
Voorbeelden
 [4]
[4]
Maatregelen
Interfaces voor modellen die zijn getraind op basis van gevoelige gegevens hebben sterk toegangsbeheer nodig.
Frequentielimietquery's die zijn toegestaan per model
Implementeer poorten tussen gebruikers/bellers en het werkelijke model door invoervalidatie uit te voeren voor alle voorgestelde query's, waarbij niets wordt geweigerd dat niet voldoet aan de definitie van de invoer correctheid van het model en alleen de minimale hoeveelheid informatie die nodig is om nuttig te zijn.
Traditionele parallellen
Gerichte, geheime openbaarmaking van informatie
Ernstigheid
Dit is standaard belangrijk volgens de SDL-standaard bugbar, maar gevoelige of persoonlijk identificeerbare gegevens die worden geëxtraheerd, zouden dit tot een kritisch niveau verhogen.
#4 Lidmaatschapsdeductieaanval
Beschrijving
De aanvaller kan bepalen of een bepaalde gegevensrecord deel uitmaakt van de trainingsgegevensset van het model of niet[1]. Onderzoekers konden de belangrijkste procedure van een patiënt voorspellen (bijvoorbeeld operatie die de patiënt doormaakte) op basis van de kenmerken (bijvoorbeeld leeftijd, geslacht, ziekenhuis) [1].
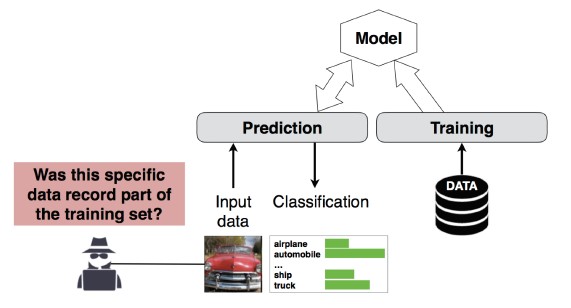 [12]
[12]
Maatregelen
Onderzoeksdocumenten die aantonen dat deze aanval levensvatbaar is, geven aan dat Differentiële privacy [4, 9] een effectieve beperking zou zijn. Dit is nog steeds een opkomende plek bij Microsoft en AETHER Security Engineering raadt het bouwen van expertise aan met onderzoeksinvesteringen in deze ruimte. Dit onderzoek moet differentiële privacymogelijkheden opsommen en hun praktische effectiviteit evalueren als oplossingen, en vervolgens manieren ontwerpen om deze verdedigingsmechanismen transparant over te nemen op onze platformen voor onlineservices, vergelijkbaar met hoe het compileren van code in Visual Studio u on-by-standaardbeveiligingsbeveiligingen biedt die transparant zijn voor de ontwikkelaar en gebruikers.
Het gebruik van neuron dropout en model stacking kan tot op zekere hoogte effectieve mitigaties vormen. Het gebruik van neuron dropout verhoogt niet alleen de tolerantie van een neuraal net voor deze aanval, maar verhoogt ook de modelprestaties [4].
Traditionele parallellen
Gegevensprivacy. Er worden deducties gemaakt over de opname van een gegevenspunt in de trainingsset, maar de trainingsgegevens zelf worden niet openbaar gemaakt
Ernstigheid
Dit is een privacyprobleem, geen beveiligingsprobleem. Het wordt behandeld in richtlijnen voor bedreigingsmodellering omdat de domeinen overlappen, maar elk antwoord hier wordt aangestuurd door privacy, niet door beveiliging.
#5 Model stelen
Beschrijving
De aanvallers maken het onderliggende model opnieuw door legitieme query's uit te voeren op het model. De functionaliteit van het nieuwe model is hetzelfde als die van het onderliggende model[1]. Zodra het model opnieuw is gemaakt, kan het worden omgekeerd om functiegegevens te herstellen of deducties te maken op trainingsgegevens.
Vergelijking oplossen: voor een model dat klassekansen retourneert via API-uitvoer, kan een aanvaller query's maken om onbekende variabelen in een model te bepalen.
Padzoeken: een aanval die gebruikmaakt van API-bijzonderheden om de 'beslissingen' te extraheren die door een boom zijn genomen bij het classificeren van een invoer [7].
Overdrachtsaanval: Een tegenstander kan een lokaal model trainen, bijvoorbeeld door voorspellingsaanvragen te doen aan het doelmodel, en dit gebruiken om kwaadaardige voorbeelden te maken die overdragen naar het doelmodel [8]. Als uw model werd geëxtraheerd en kwetsbaar blijkt voor een soort adversarial invoer, kunnen nieuwe aanvallen op uw productiemodel volledig offline worden ontwikkeld door de aanvaller die een kopie van uw model heeft geëxtraheerd.
Voorbeelden
In instellingen waarin een ML-model dienst doet om adversarial gedrag te detecteren, zoals het identificeren van spam, malwareclassificatie en detectie van netwerkafwijkingen, kan modelextractie aanvallen mogelijk maken [7].
Maatregelen
Proactieve/beschermende acties
Minimaliseer of verdoezel de details die worden geretourneerd in voorspellings-API's, terwijl ze nog steeds nuttig blijven voor 'eerlijke' toepassingen [7].
Definieer een goed opgemaakte query voor uw modelinvoer en retourneer alleen resultaten als reactie op voltooide, goed gevormde invoer die overeenkomt met die indeling.
Geef afgeronde betrouwbaarheidswaarden terug. De meeste legitieme bellers hebben niet meerdere decimalen met precisie nodig.
Traditionele parallellen
Niet-geverifieerde, alleen-lezen manipulatie van systeemgegevens, gerichte openbaarmaking van informatie met hoge waarde?
Ernstigheid
Belangrijk in beveiligingsgevoelige modellen, anders gemiddeld
#6 Herprogrammering van Neurale Netwerken
Beschrijving
Door middel van een speciaal gemaakte query van een kwaadwillende, kunnen Machine Learning-systemen opnieuw worden geprogrammeerd naar een taak die afwijkt van de oorspronkelijke intentie van de maker [1].
Voorbeelden
Zwakke toegangscontroles van een API voor gezichtsherkenning waardoor derde partijen apps kunnen maken die zijn ontworpen om Microsoft-klanten te schaden, zoals een deepfakegenerator.
Maatregelen
Sterke client-server<> wederzijdse verificatie en toegangsbeheer voor modelinterfaces
Het verwijderen van de aanstootgevende accounts.
Een service level agreement voor uw API's identificeren en afdwingen. Bepaal de acceptabele time-to-fix voor een probleem dat eenmaal is gerapporteerd en zorg ervoor dat het probleem niet meer opnieuw wordt weergegeven zodra de SLA is verlopen.
Traditionele parallellen
Dit is een misbruikscenario. U hebt minder kans om een beveiligingsincident op dit te openen dan u gewoon het account van de dader uitschakelt.
Ernstigheid
Van belangrijk tot kritiek
#7 adversarial voorbeeld in het fysieke domein (bits->atomen)
Beschrijving
Een adversarieel voorbeeld is een invoer/query van een schadelijke entiteit, bedoeld om het machine learning systeem te misleiden [1]
Voorbeelden
Deze voorbeelden kunnen zich in het fysieke domein manifesteren, zoals een zelfrijdende auto die wordt misleid om een stopteken uit te voeren vanwege een bepaalde kleur van licht (de adversarial invoer) die op het stopteken wordt weergegeven, waardoor het systeem voor afbeeldingsherkenning het stopteken niet meer als stopteken kan zien.
Traditionele parallellen
Privilege-escalatie, externe code-uitvoering
Maatregelen
Deze aanvallen komen tot uiting omdat problemen in de machine learning-laag (de gegevens- en algoritmelaag onder ai-gestuurde besluitvorming) niet zijn verzacht. Net als bij andere software *of* fysieke systemen, kan de laag onder het doel altijd worden aangevallen via traditionele vectoren. Daarom zijn traditionele beveiligingsprocedures belangrijker dan ooit, met name met de laag van ongemitteerde beveiligingsproblemen (de gegevens/algo-laag) die worden gebruikt tussen AI en traditionele software.
Ernstigheid
Kritisch
#8 Schadelijke ML-providers die trainingsgegevens kunnen herstellen
Beschrijving
Een kwaadwillende provider presenteert een algoritme met een achterdeur, waarbij de persoonlijke trainingsgegevens worden hersteld. Ze konden gezichten en teksten reconstrueren, gezien het model alleen.
Traditionele parallellen
Gerichte openbaarmaking van informatie
Maatregelen
Onderzoeksdocumenten die de levensvatbaarheid van deze aanval demonstreren, geven aan dat homomorfe versleuteling een effectieve beperking zou zijn. Dit is een gebied met weinig huidige investeringen bij Microsoft en AETHER Security Engineering raadt het bouwen van expertise aan met onderzoeksinvesteringen in deze ruimte. Dit onderzoek moet de principes van homomorfe encryptie opsommen en hun praktische effectiviteit evalueren als maatregelen tegenover kwaadwillende ML-as-a-Service-providers.
Ernstigheid
Belangrijk als gegevens PII zijn, anders gemiddeld
#9 Aanval op de ML-toeleveringsketen
Beschrijving
Vanwege grote resources (gegevens en berekeningen) die nodig zijn voor het trainen van algoritmen, is de huidige praktijk het hergebruiken van modellen die zijn getraind door grote bedrijven en deze enigszins wijzigen voor taken (bijvoorbeeld: ResNet is een populair model voor afbeeldingsherkenning van Microsoft). Deze modellen worden samengesteld in een Model Zoo (Caffe host populaire modellen voor afbeeldingsherkenning). Bij deze aanval valt de aanvaller de modellen aan die in Caffe worden gehost, waardoor de bron voor iedereen wordt vergiftigd. [1]
Traditionele parallellen
Inbreuk op niet-beveiligingsafhankelijkheid van derden
App Store host onbewust malware.
Maatregelen
Minimaliseer waar mogelijk afhankelijkheden van derden voor modellen en gegevens.
Neem deze afhankelijkheden op in uw threat modeling-proces.
Maak gebruik van sterke verificatie, toegangsbeheer en versleuteling tussen 1st/3rd-party systemen.
Ernstigheid
Kritisch
#10 Backdoor Machine Learning
Beschrijving
Het trainingsproces wordt uitbesteed aan een kwaadwillende derde partij die knoeit met trainingsgegevens en een trojaans model levert dat gerichte misclassificaties dwingt, zoals het classificeren van een bepaald virus als niet-schadelijk[1]. Dit is een risico in ML-as-a-Service-modelgeneratiescenario's.
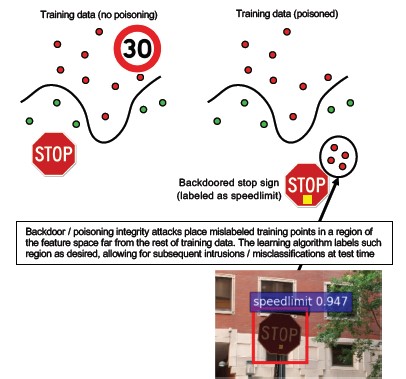 [12]
[12]
Traditionele parallellen
Inbreuk op beveiligingsafhankelijkheid van derden
Gecompromitteerd mechanisme voor software-updates
Inbreuk op certificeringsinstantie
Maatregelen
Reactieve/defensieve detectieacties
- De schade is al aangericht zodra deze bedreiging is ontdekt, dus het model en eventuele trainingsgegevens die door de kwaadwillende provider worden geleverd, zijn niet te vertrouwen.
Proactieve/beschermende acties
Alle gevoelige modellen intern trainen
Trainingsgegevens catalogiseren of ervoor zorgen dat deze afkomstig zijn van een vertrouwde derde partij met sterke beveiligingsprocedures
Bedreigingsmodel voor de interactie tussen de MLaaS-provider en uw eigen systemen
Antwoordacties
- Hetzelfde als voor inbreuk op externe afhankelijkheid
Ernstigheid
Kritisch
#11 Softwareafhankelijkheden van het ML-systeem misbruiken
Beschrijving
Bij deze aanval bewerkt de aanvaller de algoritmen NIET. In plaats daarvan misbruikt u softwareproblemen, zoals bufferoverloop of cross-site scripting[1]. Het is nog steeds eenvoudiger om softwarelagen onder AI/ML in gevaar te krijgen dan de leerlaag rechtstreeks aan te vallen, dus traditionele beveiligingsrisicobeperkingsprocedures die in de levenscyclus van beveiligingsontwikkeling worden beschreven, zijn essentieel.
Traditionele parallellen
Gecompromitteerde opensource-softwareafhankelijkheid
Beveiligingsprobleem met webservers (XSS, CSRF, API-invoervalidatiefout)
Maatregelen
Werk samen met uw beveiligingsteam om de toepasselijke best practices voor security development lifecycle/operational security assurance te volgen.
Ernstigheid
Veranderlijk; Tot kritiek, afhankelijk van het type traditionele softwareprobleem.
Bibliografie
[1] Foutenmodi in Machine Learning, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen en Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Gegevensherkomst/-afstamming v-team
[3] Adversariële Voorbeelden in Deep Learning: Characterisatie en Divergentie, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Model- & data-onafhankelijke lidmaatschapsinference-aanvallen en -verdedigingen op machine learning-modellen, Salem, et al,
[5] M. Fredrikson, S. Jha en T. Ristenpart, "Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures," in Proceedings van de 2015 ACM SIGSAC Conferentie over Computer- en Communicatiebeveiliging (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Adversariële Voorbeelden in Machinaal Leren AIWTB 2017
[7] Machine Learning-modellen stelen via voorspellings-API's, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] De ruimte van overdraagbare adversarial voorbeelden, Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh en Patrick McDaniel
[9] Begrijpen van Lidmaatschap Inferences op Well-Generalized Leer Modellen Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 en Kai Chen3,4
[10] Simon-Gabriel et al., Adversariële kwetsbaarheid van neurale netwerken neemt toe met de invoerdimensie, ArXiv 2018;
[11] Lyu et al., Een uniforme gradiënt regularisatie familie voor adversariale voorbeelden, ICDM 2015
[12] Wilde patronen: Tien jaar na de opkomst van adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarial Robuuste Malwaredetectie met Monotone Classificatie Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto, en Fabio Roli. Bagging-classificaties voor het bestrijden van vergiftigingsaanvallen in tegenstander-classificatietaken.
[15] Een Verbeterde Afwijzing van Negatieve Invloed Verdediging Hongjiang Li en Patrick P.K. Chan
[16] Adler. Beveiligingsproblemen in biometrische versleutelingssystemen. 5e Internationale Conferentie AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Op de kwetsbaarheid van gezichtsverificatiesystemen voor hill-climbing aanvallen. Patt. Aanbeveling, 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Functiesamenknijpen: Het detecteren van vijandige voorbeelden in diepe neurale netwerken. 2018 Network and Distributed System Security Symposium. 18-21 februari.
[19] Versterking van adversarial robuustheid met behulp van door adversarial training geïnduceerd modelvertrouwen - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attributiegestuurde causale analyse voor detectie van adversariële voorbeelden, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robuuste lineaire regressie tegen trainingsgegevensvergiftiging – Chang Liu et al.
[22] Kenmerkruisvervaging voor verbetering van tegenstrijdige robuustheid, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Gecertificeerde verdediging tegen Adversarial Examples - Aditi Raghunathan, Jacob Steinhardt, Percy Liang