Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Semantische kernel biedt veel verschillende onderdelen, die afzonderlijk of samen kunnen worden gebruikt. In dit artikel vindt u een overzicht van de verschillende onderdelen en wordt de relatie tussen deze onderdelen uitgelegd.
AI-serviceconnectoren
De Semantische Kernel AI-serviceconnectors bieden een abstractielaag die meerdere AI-servicetypen van verschillende providers beschikbaar maakt via een gemeenschappelijke interface. Ondersteunde services zijn onder andere chatcompletie, tekstgeneratie, embedding-generatie, tekst naar afbeelding, tekst naar audio en audio naar tekst.
Wanneer een implementatie is geregistreerd bij de kernel, worden chatvoltooiings- of tekstgeneratieservices standaard gebruikt door methodeaanroepen naar de kernel. Geen van de andere ondersteunde services wordt automatisch gebruikt.
Tip
Zie AI-services toevoegen aan Semantic Kernelvoor meer informatie over het gebruik van AI-services.
Vector Store (geheugen) connectors
De Semantische Kernel Vector Store-connectors bieden een abstractielaag die vectorarchieven van verschillende providers beschikbaar maakt via een gemeenschappelijke interface. De kernel gebruikt geen geregistreerde vectoropslag automatisch, maar Vector Search kan eenvoudig worden weergegeven als een invoegtoepassing voor de kernel in welk geval de invoegtoepassing beschikbaar wordt gesteld voor promptsjablonen en het AI-model voor voltooiing van chatgesprekken.
Fooi
Zie AI-services toevoegen aan Semantic Kernelvoor meer informatie over het gebruik van geheugenconnectors.
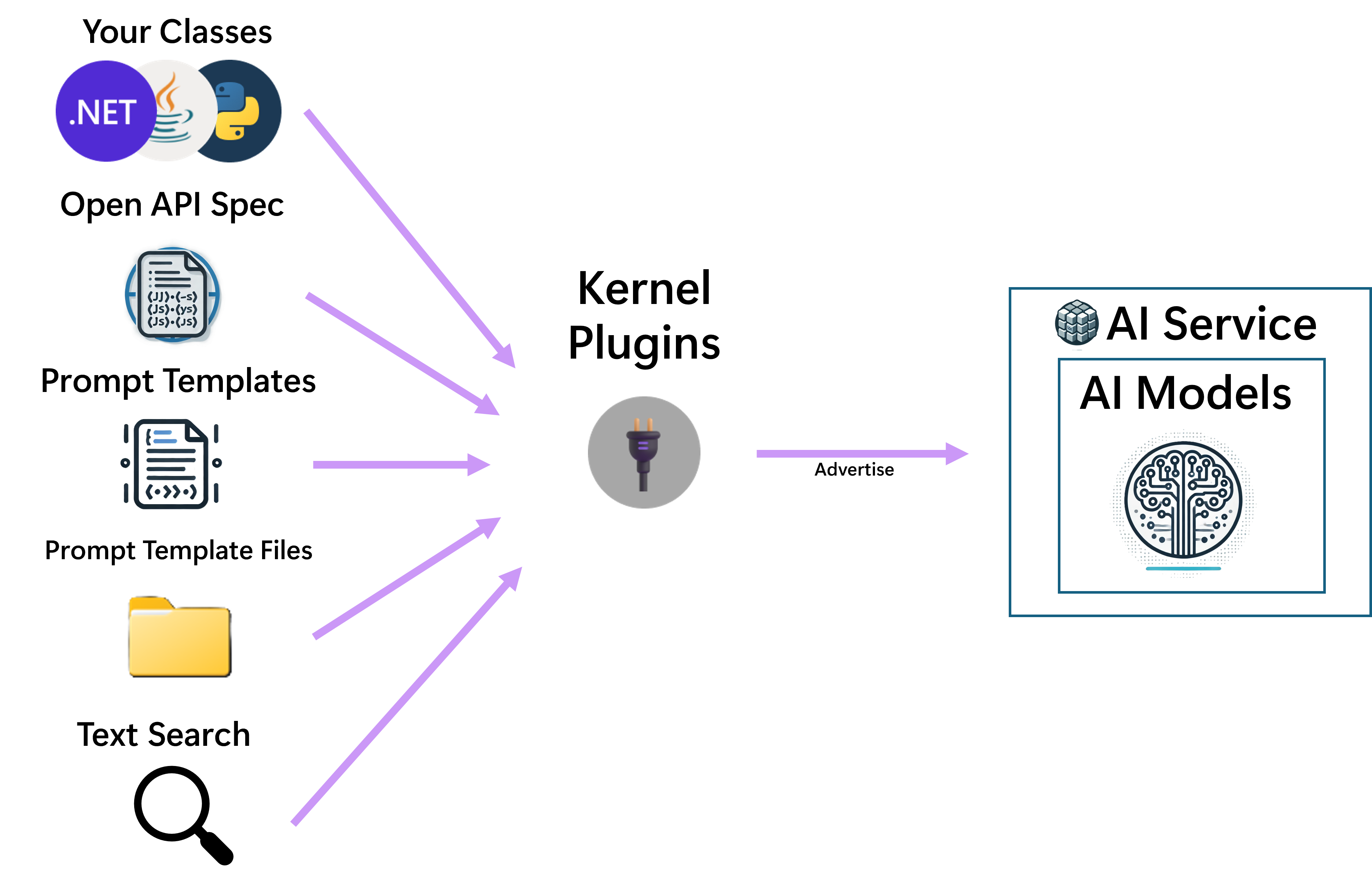
Functies en invoegtoepassingen
Invoegtoepassingen worden functiecontainers genoemd. Elk kan een of meer functies bevatten. Invoegtoepassingen kunnen worden geregistreerd bij de kernel, waardoor de kernel deze op twee manieren kan gebruiken:
- Promoot ze aan de chat-afrondings-AI, zodat de AI ze kan kiezen voor oproep.
- Maak ze beschikbaar om te worden aangeroepen vanuit een sjabloon tijdens het weergeven van sjablonen.
Functies kunnen eenvoudig worden gemaakt op basis van veel bronnen, waaronder systeemeigen code, OpenAPI-specificaties, ITextSearch implementaties voor RAG-scenario's, maar ook vanuit promptsjablonen.
Tip
Voor meer informatie over verschillende invoegtoepassing bronnen zie Wat is een invoegtoepassing?.
Tip
Zie Functie-aanroepen met voltooiing van chatsvoor meer informatie over advertentieinvoegtoepassingen voor de voltooiing van chats.
Promptsjablonen
Met promptsjablonen kan een ontwikkelaar of prompt-engineer een sjabloon maken die context en instructies voor de AI combineert met gebruikersinvoer en functie-uitvoer. De sjabloon kan bijvoorbeeld instructies bevatten voor het AI-model voor chatvoltooiing en tijdelijke aanduidingen voor gebruikersinvoer, plus vastgelegde aanroepen naar invoegtoepassingen die altijd moeten worden uitgevoerd voordat het AI-model voor chatvoltooiing wordt aangeroepen.
Promptsjablonen kunnen op twee manieren worden gebruikt:
- Als het beginpunt van een voltooiingsstroom van een chat door de kernel te vragen de sjabloon weer te geven en het AI-model voor chatvoltooiing aan te roepen met het gerenderde resultaat.
- Als invoegtoepassingsfunctie, zodat deze op dezelfde manier kan worden aangeroepen als elke andere functie.
Wanneer een promptsjabloon wordt gebruikt, wordt deze eerst weergegeven, plus eventuele in code vastgelegde functieverwijzingen die deze bevat, worden uitgevoerd. De weergegeven prompt wordt vervolgens doorgegeven aan het AI-model voor chatvoltooiing. Het resultaat dat door de AI wordt gegenereerd, wordt geretourneerd naar de aanroeper. Als de promptsjabloon was geregistreerd als een pluginfunctie, zou de functie gekozen kunnen zijn voor uitvoering door het AI-model voor chatvoltooiing, en in dit geval is de aanroeper Semantic Kernel namens het AI-model.
Het inzetten van promptsjablonen als invoegtoepassingsfuncties kan zo leiden tot nogal complexe werkstromen. Denk bijvoorbeeld aan het scenario waarin een promptsjabloon A is geregistreerd als een invoegtoepassing.
Tegelijkertijd kan een ander prompt-sjabloon B worden doorgegeven aan de kernel om het voltooiingsproces van de chat te starten.
B kan een in code vastgelegde aanroep naar Ahebben.
Dit leidt tot de volgende stappen:
-
Brendering wordt gestart en de promptuitvoering vindt een verwijzing naarA -
Awordt weergegeven. - De weergegeven uitvoer van
Awordt doorgegeven aan het AI-model voor chatvoltooiing. - Het resultaat van het AI-model voor chatvoltooiing wordt geretourneerd naar
B. - Weergave van
Bvoltooid. - De weergegeven uitvoer van
Bwordt doorgegeven aan het AI-model voor voltooiing van chats. - Het resultaat van het AI-model voor chatvoltooiing wordt geretourneerd naar de beller.
Houd ook rekening met het scenario waarin er geen in code vastgelegde aanroep van B naar Ais.
Als functie-aanroepen is ingeschakeld, kan het AI-model voor chatvoltooiing nog steeds besluiten dat A moet worden aangeroepen, omdat hiervoor gegevens of functionaliteit zijn vereist die A kan bieden.
Het registreren van promptsjablonen als invoegtoepassingsfuncties maakt het mogelijk om functionaliteit te maken die wordt beschreven met behulp van menselijke taal in plaats van echte code. Door de functionaliteit op deze manier in een invoegtoepassing te scheiden, kan het AI-model hier los van de hoofd-uitvoeringsstroom over nadenken, wat kan leiden tot hogere slagingspercentages van het AI-model, omdat het zich op één probleem tegelijk kan richten.
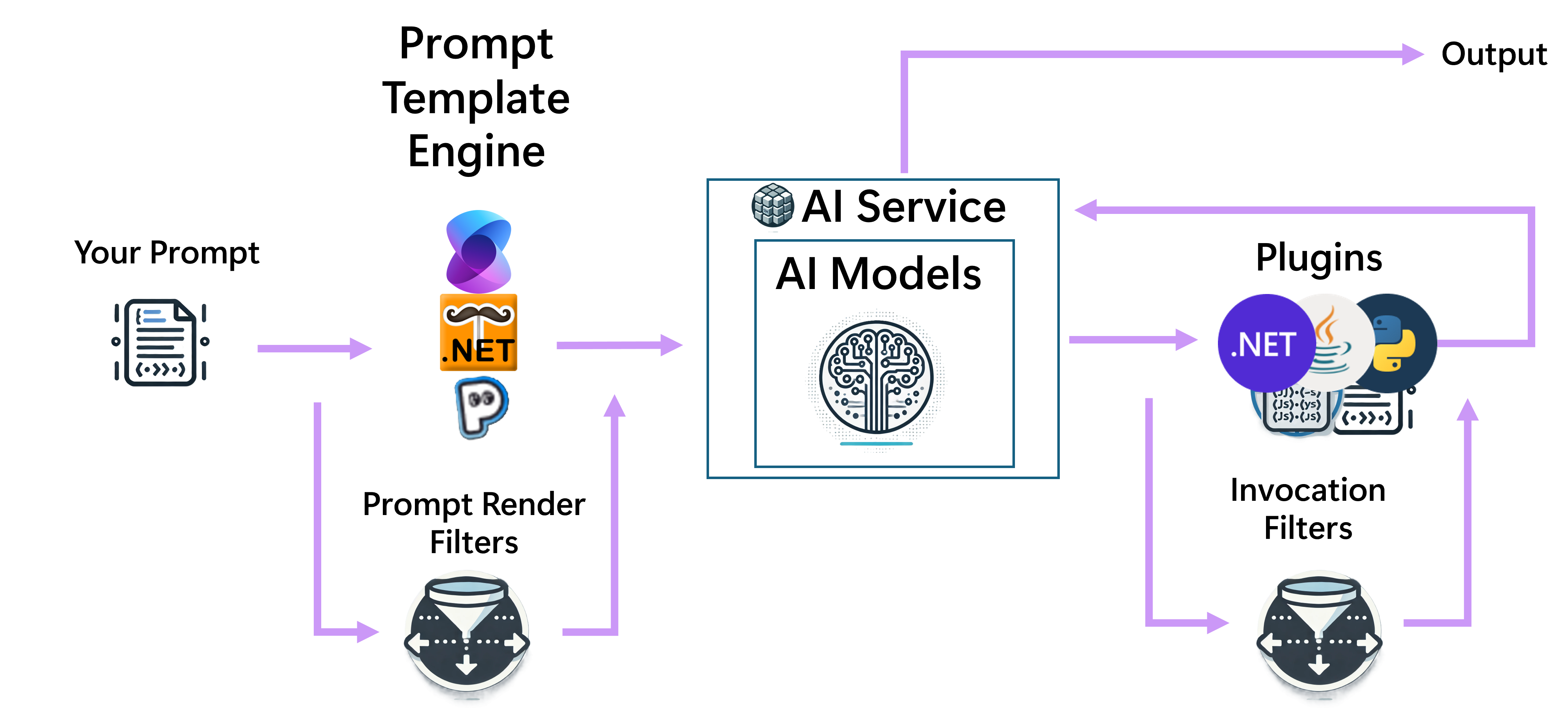
Zie het volgende diagram voor een eenvoudig proces dat wordt gestart vanuit een promptsjabloon.

Filters
Filters bieden een manier om aangepaste actie te ondernemen voor en na specifieke gebeurtenissen tijdens de voltooiingsstroom van de chat. Deze gebeurtenissen zijn onder andere:
- Voor het en na het aanroepen van de functie.
- Voor en na het renderen van prompts.
Filters moeten worden geregistreerd bij de kernel om te worden opgeroepen tijdens de stroom voor voltooiing van de chat.
Aangezien promptsjablonen altijd vóór de uitvoering worden geconverteerd naar KernelFunctions, worden zowel functie- als promptfilters aangeroepen voor een promptsjabloon. Omdat filters zijn genest wanneer er meer dan één beschikbaar is, zijn functiefilters de buitenste filters en promptfilters de binnenste filters.
Fooi / Tip / Aanwijzing / Advies (depending on context)
Voor meer informatie over filters, zie Wat zijn filters?.