Jupyter Notebooks gebruiken in Azure Data Studio
Van toepassing op: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook is een opensource-webtoepassing waarmee u documenten met live code, vergelijkingen, visualisaties en verhaaltekst kunt maken en delen. Gebruik omvat het opschonen en transformeren van gegevens, numerieke simulatie, statistische modellering, gegevensvisualisatie en machine learning.
In dit artikel wordt beschreven hoe u een nieuw notebook maakt in de nieuwste versie van Azure Data Studio en hoe u uw eigen notebooks ontwerpt met behulp van verschillende kernels.
Bekijk deze korte video van 5 minuten voor een inleiding tot notebooks in Azure Data Studio:
Een notebook maken
Er zijn meerdere manieren om een nieuw notitieblok te maken. In elk geval wordt een nieuw bestand geopend met de naam Notebook-1.ipynb .
Ga naar het menu Bestand in Azure Data Studio en selecteer Nieuw notitieblok.
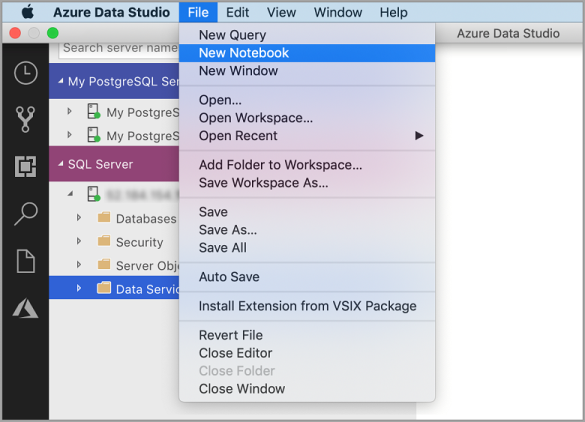
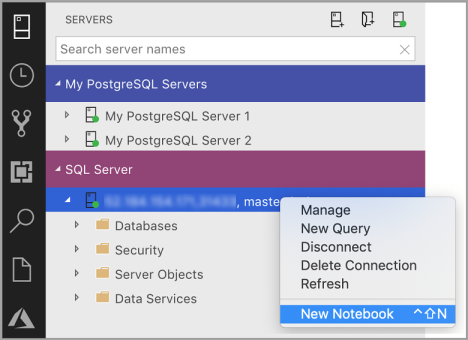
Klik met de rechtermuisknop op een SQL Server-verbinding en selecteer Nieuw notitieblok.
Open het opdrachtenpalet (Ctrl+Shift+P), typ 'nieuw notitieblok' en selecteer de opdracht Nieuw notitieblok .

Verbinding maken met een kernel
Azure Data Studio-notebooks ondersteunen een aantal verschillende kernels, waaronder SQL Server, Python, PySpark en andere. Elke kernel ondersteunt een andere taal in de codecellen van uw notebook. Wanneer u bijvoorbeeld verbinding hebt gemaakt met de SQL Server-kernel, kunt u T-SQL-instructies invoeren en uitvoeren in een notebookcodecel.
Koppelen aan biedt de context voor de kernel. Als u bijvoorbeeld SQL Kernel gebruikt, kunt u deze koppelen aan een van uw SQL Server-exemplaren. Als u Python3 Kernel gebruikt, koppelt u deze kernel aan localhost en kunt u deze kernel gebruiken voor uw lokale Python-ontwikkeling.
SQL Kernel kan ook worden gebruikt om verbinding te maken met PostgreSQL-serverexemplaren. Als u een PostgreSQL-ontwikkelaar bent en de notebooks wilt verbinden met uw PostgreSQL-server, downloadt u de PostgreSQL-extensie in de Azure Data Studio-extensie Marketplace en maakt u verbinding met de PostgreSQL-server.
Als u bent verbonden met een big data-cluster van SQL Server 2019, is de standaardkoppeling het eindpunt van het cluster. U kunt Python-, Scala- en R-code verzenden met behulp van de Spark-berekening van het cluster.
| Kernel | Beschrijving |
|---|---|
| SQL-kernel | Schrijf SQL Code die is gericht op uw relationele database. |
| PySpark3- en PySpark-kernel | Python-code schrijven met Behulp van Spark Compute vanuit het cluster. |
| Spark-kernel | Schrijf Scala- en R-code met behulp van Spark-rekenkracht vanuit het cluster. |
| Python-kernel | Python-code schrijven voor lokale ontwikkeling. |
Zie voor meer informatie over specifieke kernels:
- Een SQL Server-notebook maken en uitvoeren
- Een Python-notebook maken en uitvoeren
- Kqlmagic-extensie in Azure Data Studio : dit breidt de mogelijkheden van de Python-kernel uit
Een codecel toevoegen
Met codecellen kunt u code interactief uitvoeren in het notebook.
Voeg een nieuwe codecel toe door op de opdracht +Cel in de werkbalk te klikken en Codecel te selecteren. Er wordt een nieuwe codecel toegevoegd na de geselecteerde cel.
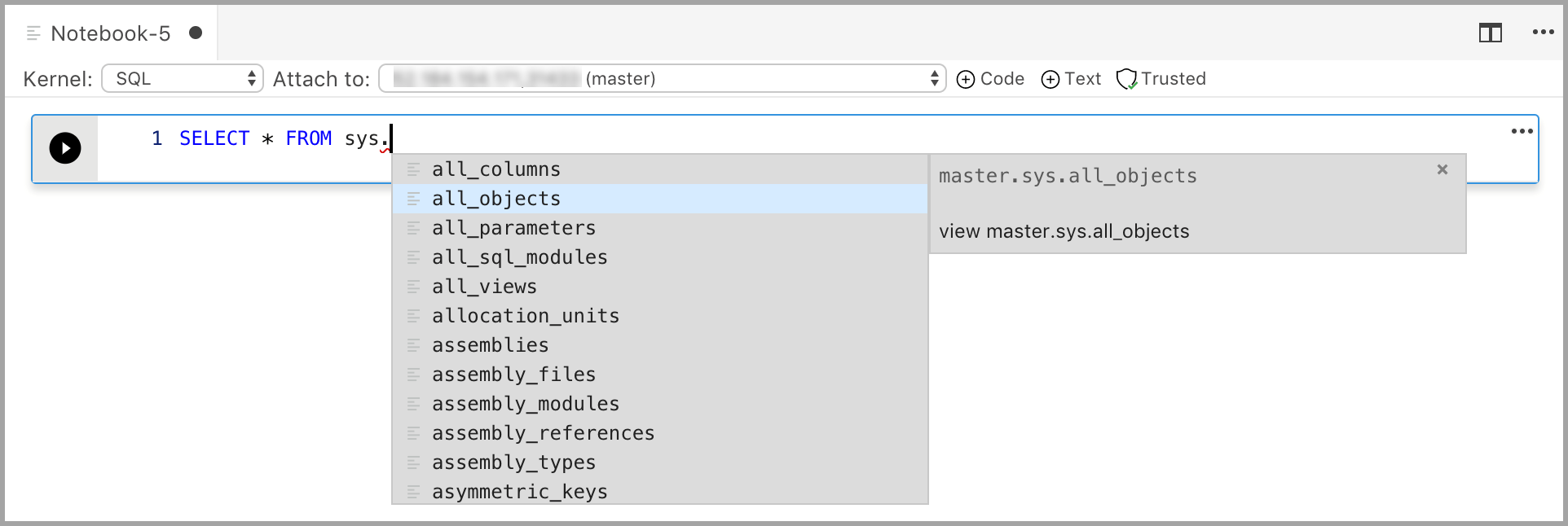
Voer code in de cel voor de geselecteerde kernel in. Als u bijvoorbeeld de SQL-kernel gebruikt, kunt u T-SQL-opdrachten invoeren in de codecel.
Het invoeren van code met de SQL-kernel is vergelijkbaar met een SQL-queryeditor. De codecel ondersteunt een moderne SQL-coderingservaring met ingebouwde functies zoals een uitgebreide SQL-editor, IntelliSense en ingebouwde codefragmenten. Met codefragmenten kunt u de juiste SQL-syntaxis genereren om databases, tabellen, weergaven, opgeslagen procedures te maken en bestaande databaseobjecten bij te werken. Gebruik codefragmenten om snel kopieën van uw database te maken voor ontwikkelings- of testdoeleinden en om scripts te genereren en uit te voeren.
Een tekstcel toevoegen
Met tekstcellen kunt u uw code documenteren door Markdown-tekstblokken toe te voegen tussen codecellen.
Voeg een nieuwe tekstcel toe door op de opdracht +Cel in de werkbalk te klikken en tekstcel te selecteren.
De cel wordt gestart in de bewerkingsmodus waarin u Markdown-tekst kunt typen. Terwijl u typt, wordt hieronder een voorbeeld weergegeven.
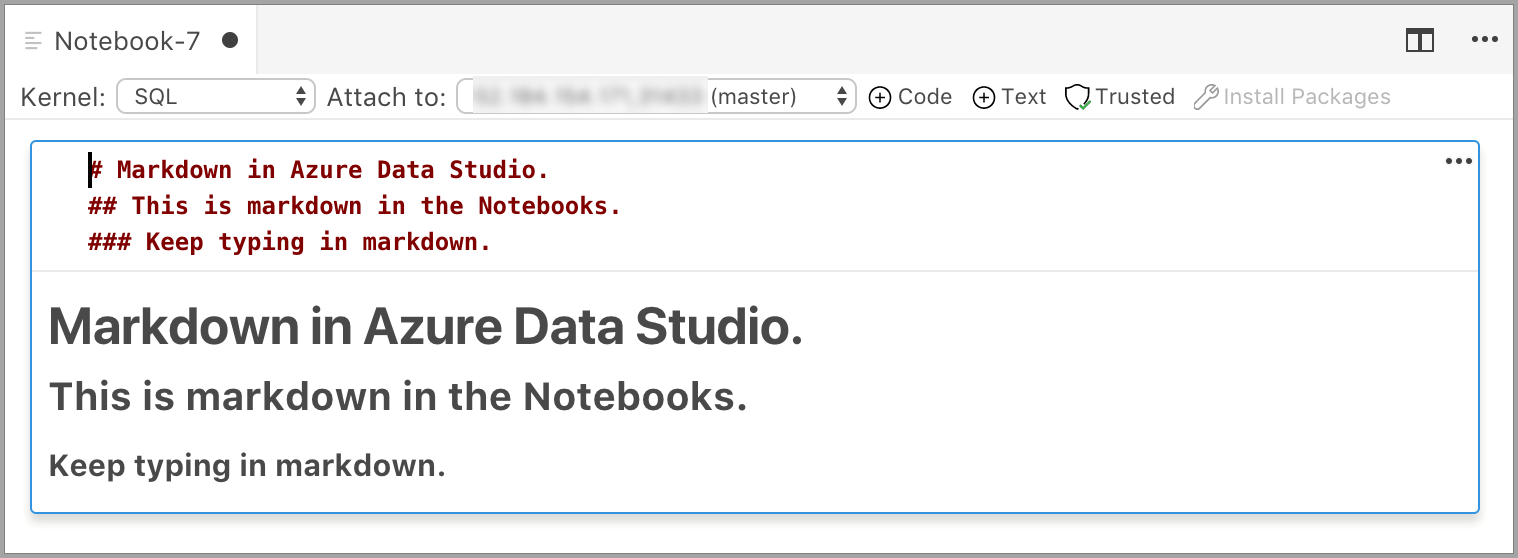
Als u buiten de tekstcel selecteert, wordt de Markdown-tekst weergegeven.
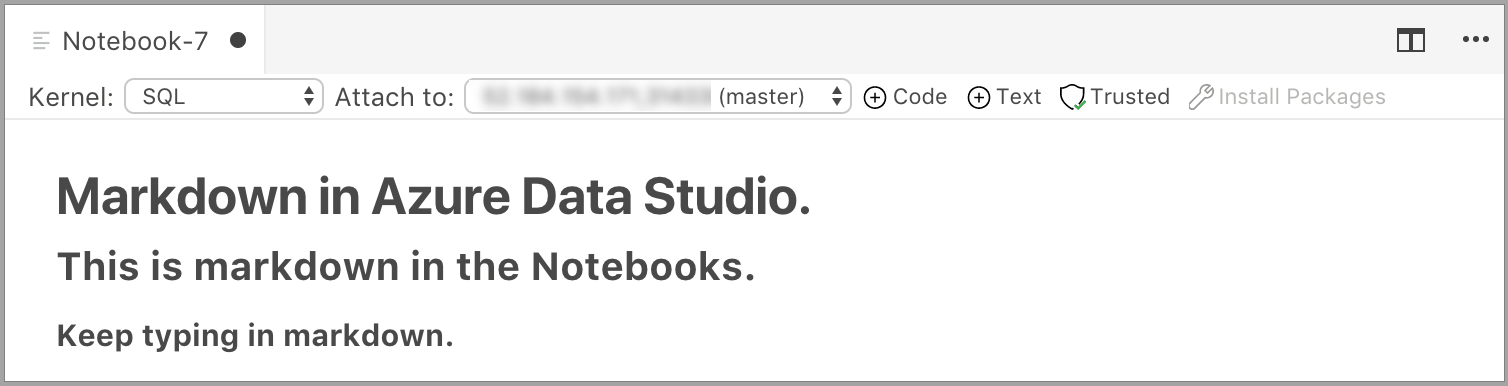
Als u nogmaals in de tekstcel klikt, verandert deze in de bewerkingsmodus.
Een cel uitvoeren
Als u één cel wilt uitvoeren, klikt u op Cel uitvoeren (de ronde zwarte pijl) links van de cel of selecteert u de cel en drukt u op F5. U kunt alle cellen in het notitieblok uitvoeren door op Alles uitvoeren op de werkbalk te klikken. De cellen worden één voor één uitgevoerd en de uitvoering stopt als er een fout optreedt in een cel.
Resultaten van de cel worden onder de cel weergegeven. U kunt de resultaten van alle uitgevoerde cellen in het notitieblok wissen door de knop Resultaten wissen op de werkbalk te selecteren.
Een notitieblok opslaan
Ga op een van de volgende manieren te werk om een notitieblok op te slaan.
- Typ Ctrl+S
- Selecteer Opslaan in het menu Bestand
- Selecteer Opslaan als... in het menu Bestand
- Selecteer Alles opslaan in het menu Bestand . Hiermee worden alle geopende notitieblokken opgeslagen
- Voer in het opdrachtpalet Bestand in: Opslaan
Notitieblokken worden opgeslagen als .ipynb bestanden.
Vertrouwd en niet-vertrouwd
De geopende notebooks in Azure Data Studio zijn standaard ingesteld op Vertrouwd.
Als u een notitieblok opent vanuit een andere bron, wordt het geopend in de modus Niet-vertrouwd en kunt u het notitieblok vertrouwd maken.
Voorbeelden
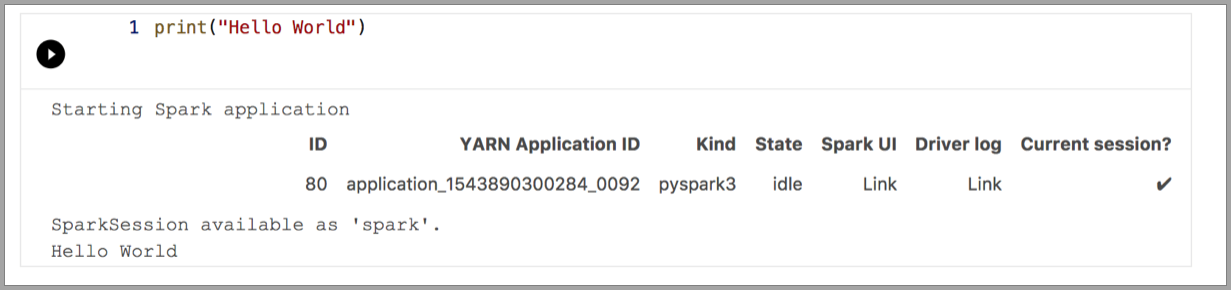
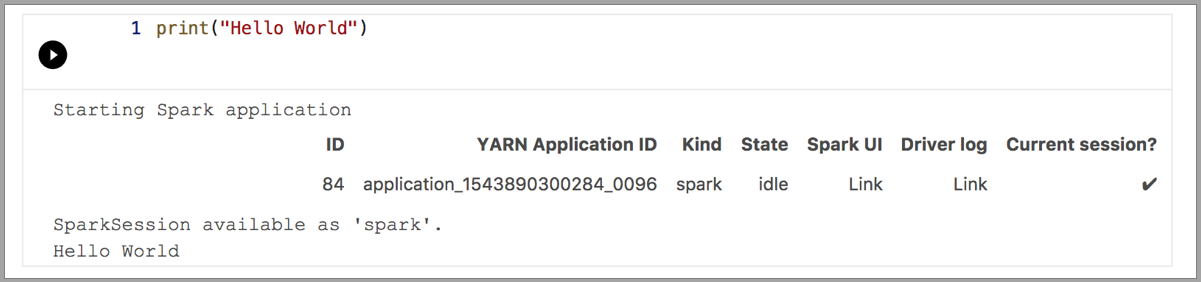
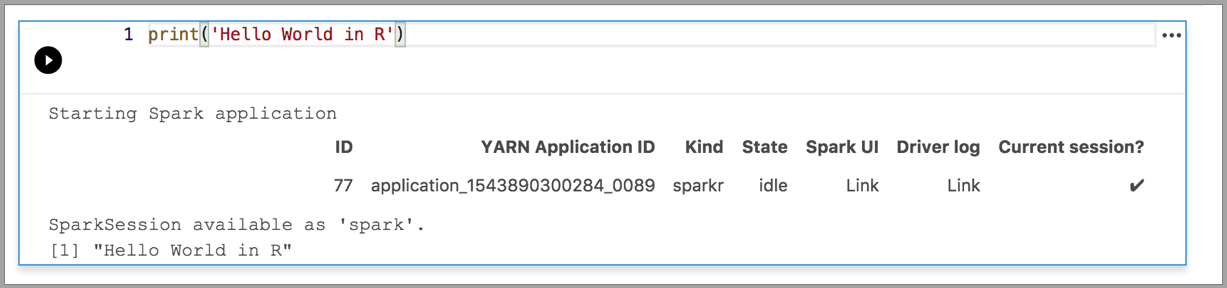
In de volgende voorbeelden ziet u hoe u verschillende kernels gebruikt om een eenvoudige opdracht 'Hallo wereld' uit te voeren. Selecteer de kernel, voer de voorbeeldcode in een cel in en klik op Cel uitvoeren.
Pyspark
Spark | Scala-taal
Spark | R-taal
Python 3

Volgende stappen
- Een SQL Server-notebook maken en uitvoeren.
- Een Python-notebook maken en uitvoeren
- Python- en R-scripts uitvoeren in Azure Data Studio-notebooks met SQL Server Machine Learning Services.
- Implementeer een BIG Data-cluster van SQL Server met Azure Data Studio-notebook.
- Big Data-clusters van SQL Server beheren met Azure Data Studio-notebooks.
- Voer een voorbeeldnotebook uit met Spark.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor