Resources deployed with SQL Server Big Data Clusters
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
This article describes the resources a SQL Server Big Data Cluster deploys.
A big data cluster deploys pods based on the deployment profile. For details see Default configurations.
This article describes the pods deployed with aks-dev-test-ha profile and includes a Spark pool. Query Kubernetes to see the pods deployed in your cluster. The following example returns a list of pods under a specific namespace.
kubectl get pods -n <namespace>
Replace <namespace> with the name of your big data cluster.
For more information, see How to deploy SQL Server Big Data Clusters on Kubernetes.
The following diagram displays the components deployed in a Big Data Cluster:
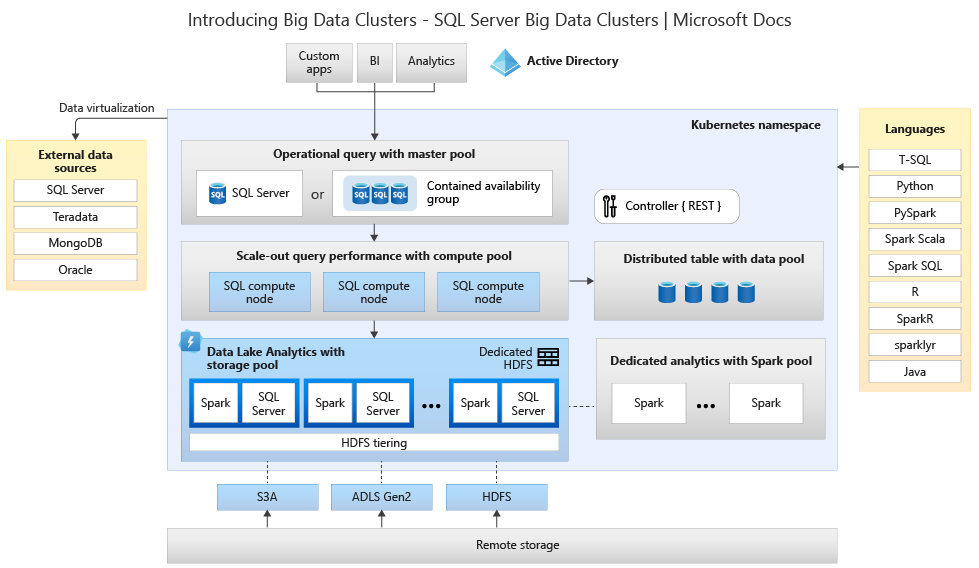
For information about the architecture, see Introducing SQL Server Big Data Clusters.
Deployed pods
The following table lists pods deployed in a Big Data Cluster.
| Name | Area |
|---|---|
control-<nnnn> |
Control |
controldb-<#> |
Control |
controlwd-<nnnn> |
Control |
logsdb-<#> |
Control |
logsui-<nnnn> |
Control |
metricsdb-<#> |
Control |
metricsdc-<nnnn> |
Control |
metricsui-<nnnn> |
Control |
mgmtproxy-<nnnn> |
Control |
zookeeper-<#> |
Control |
dns-<nnnn> |
Control |
master-<#n> |
Master instance |
operator-<nnnn> |
Master instance |
compute-<#n>-<#m> |
Compute pool |
data-<#>-<#> |
Data pool |
storage-<#>-<#> |
Storage pool |
nmnode-<#>-<#> |
Storage pool |
sparkhead-<#> |
Storage pool |
appproxy-<#m> |
Application pool |
gateway-<#> |
Gateway service |
Not all pods are included in every big data cluster. Deployments with high availability, or active directory integration include specific pods.
High availability specific pods:
operator-<nnnn>zookeeper-<#>
Active directory specific pods:
dns-<nnnn>
The following sections describe the pods and list the containers in each pod.
Control
Control pods provide the control service.
| Pod name | Count | Kubernetes controller type | Containers |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 per Kubernetes node. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 or 1 for Active Directory integration | ReplicaSet | - dns- fluentbit |
Master instance
master-<#n> is the SQL Server master instance.
- Manages the data pool via DDL
- Manipulates data in the data pool via DML
- Off-loads analytic query execution to the data pool
| Pod name | Count | Kubernetes controller type | Containers |
|---|---|---|---|
master-<#n> |
1 or more for high availability. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 or 1 for high availability | ReplicaSet | - mssql-ha-operator |
* Only high availability deployments. The operator implements and registers the custom resource definition for SQL Server and the Availability Group resources. When the operator is deployed, it registers itself as a listener for notifications about SQL Server resources being deployed in the Kubernetes cluster. mssql-ha-supervisor supports the availability group.
Each master pod contains one instance of SQL Server. A high-availability deployment includes 3 pods. Each pod includes a SQL Server instance with databases in a SQL Server Always On Availability Group.
Include additional pods at deployment time, depending on your workload.
Compute pool
Compute pool provides a SQL Server instance for computation.
| Pod name | Count | Kubernetes controller type | Containers |
|---|---|---|---|
compute-<#n>-<#m> |
1 or more. | StatefulSet | - mssql-server- fluentbit- collectd |
#nidentifies the compute pool.#midentifies the instance ID within the pool.
The compute pool SQL Server instances are stateless. They only require storage for tempdb.
Include additional pods at deployment time, depending on your workload.
Data pool
The data pool provides SQL Server instances for storage and compute.
| Pod name | Count | Kubernetes controller type | Containers |
|---|---|---|---|
data-<#n>-<#m> |
0 or more | StatefulSet | - mssql-server - fluentbit- collectd |
#nidentifies the data pool.#midentifies the instance ID within the pool.
Include additional pods at deployment time, depending on workload.
Storage pool
Storage pool provides data ingestion through Spark, storage in HDFS, data access through HDFS and SQL Server endpoints.
| Pod name | Count | Kubernetes controller type | Containers |
|---|---|---|---|
storage-0-# |
1 or more. Include additional pods at deployment time, depending on workload. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 or more for high availability | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 or more for high availability | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 or 3 for high availability. | StatefulSet | - zookeeper- fluentbit |
Application pool
The application pool is included in some of the test configuration profiles. The application pool hosts application service proxies that you define when you deploy your applications for Big Data Clusters.
appproxy is a web API that sits in front of the application pool applications. It authenticates users and then routes the requests through to the applications.
| Pod name | Kubernetes controller type | Containers |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
For more information, see Introducing Application Deployment on a Big Data Cluster.
Include additional pods at deployment time, depending on workload.
Gateway service
Gateway services provides the Knox gateway to Spark, HDFS, Yarn, Yarn UI, and Spark UI.
| Pod name | Kubernetes controller type | Containers |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Only one gateway is supported.
Open-source container references
For for specific open-source projects and versions, see Open-source software reference.
Next steps
To learn more about the SQL Server Big Data Clusters, see the following resources:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor