Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server
Een gedistribueerde beschikbaarheidsgroep (AG) is een speciaal type beschikbaarheidsgroep dat twee afzonderlijke beschikbaarheidsgroepen omvat. Gedistribueerde beschikbaarheidsgroepen zijn beschikbaar vanaf SQL Server 2016.
In dit artikel wordt de functie voor gedistribueerde beschikbaarheidsgroepen beschreven. Zie Gedistribueerde beschikbaarheidsgroepen configureren om een gedistribueerde beschikbaarheidsgroep te configureren.
Overzicht
Een gedistribueerde beschikbaarheidsgroep is een speciaal type beschikbaarheidsgroep dat twee afzonderlijke beschikbaarheidsgroepen omvat. De beschikbaarheidsgroepen die deelnemen aan een gedistribueerde beschikbaarheidsgroep hoeven zich niet op dezelfde locatie te bevinden. Ze kunnen fysiek, virtueel, on-premises, in de openbare cloud of overal zijn die ondersteuning bieden voor een implementatie van een beschikbaarheidsgroep. Dit omvat meerdere domeinen en zelfs platformoverschrijdend, zoals tussen een beschikbaarheidsgroep die wordt gehost op Linux en één die wordt gehost in Windows. Zolang er twee beschikbaarheidsgroepen kunnen communiceren, kunt u er een gedistribueerde beschikbaarheidsgroep mee configureren.
Een traditionele beschikbaarheidsgroep bevat resources die zijn geconfigureerd in een Windows Server Failover Cluster (WSFC) of in een Pacemaker-configuratie op Linux. Een gedistribueerde beschikbaarheidsgroep configureert niets in het onderliggende cluster (WSFC of Pacemaker). Alles over deze wordt onderhouden in SQL Server. Zie Informatie over gedistribueerde beschikbaarheidsgroepen weergeven voor informatie over het weergeven van informatie over gedistribueerde beschikbaarheidsgroepen.
Een gedistribueerde beschikbaarheidsgroep vereist dat de onderliggende beschikbaarheidsgroepen een listener hebben. In plaats van de onderliggende servernaam op te geven voor een zelfstandig exemplaar (of in het geval van een exemplaar van een SQL Server-failovercluster [FCI], de waarde die is gekoppeld aan de netwerknaamresource), zoals u zou doen met een traditionele beschikbaarheidsgroep, geeft u de geconfigureerde listener op voor de gedistribueerde beschikbaarheidsgroep met de parameter ENDPOINT_URL wanneer u deze maakt. Hoewel elke onderliggende beschikbaarheidsgroep van de gedistribueerde beschikbaarheidsgroep een listener heeft, heeft een gedistribueerde beschikbaarheidsgroep geen listener.
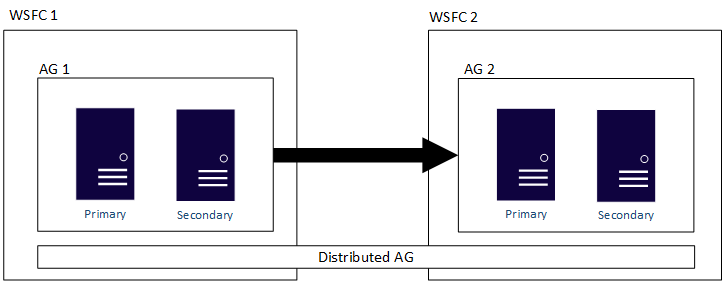
In de volgende afbeelding ziet u een weergave op hoog niveau van een gedistribueerde beschikbaarheidsgroep die twee beschikbaarheidsgroepen (AG 1 en AG 2) omvat, die elk zijn geconfigureerd op een eigen WSFC. De gedistribueerde beschikbaarheidsgroep heeft in totaal vier replica's, met twee in elke beschikbaarheidsgroep. Elke beschikbaarheidsgroep kan maximaal het maximum aantal replica's ondersteunen, zodat een gedistribueerde beschikbaarheidsgroep maximaal 18 replica's kan hebben.
U kunt de gegevensverplaatsing in gedistribueerde beschikbaarheidsgroepen configureren als synchroon of asynchroon. Gegevensverplaatsing verschilt echter enigszins binnen gedistribueerde beschikbaarheidsgroepen in vergelijking met een traditionele beschikbaarheidsgroep. Hoewel elke beschikbaarheidsgroep een primaire replica heeft, is er slechts één kopie van de databases die deelnemen aan een gedistribueerde beschikbaarheidsgroep die invoegen, updates en verwijderingen kan accepteren. Zoals in de volgende afbeelding wordt weergegeven, is AG 1 de primaire beschikbaarheidsgroep. De primaire replica verzendt transacties naar zowel de secundaire replica's van AG 1 als de primaire replica van AG 2. De primaire replica van AG 2 wordt ook wel een forwarder genoemd. Een forwarder is een primaire replica in een secundaire beschikbaarheidsgroep binnen een gedistribueerde beschikbaarheidsgroep. De doorstuurserver ontvangt transacties van de primaire replica in de primaire beschikbaarheidsgroep en stuurt deze door naar de secundaire replica's in een eigen beschikbaarheidsgroep. De verzender houdt vervolgens de secundaire replica's van AG 2 bijgewerkt.
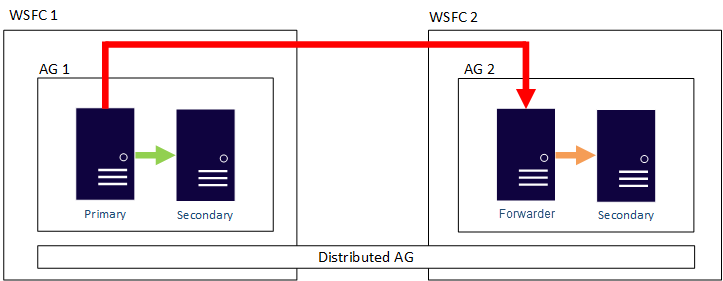
De enige manier om ervoor te zorgen dat de primaire replica van AG 2 inserts, updates en verwijderingen accepteert, is door handmatig een failover uit te voeren van de gedistribueerde beschikbaarheidsgroep van AG 1. Omdat in de voorgaande afbeelding AG 1 de beschrijfbare kopie van de database bevat, maakt het uitvoeren van een failover AG 2 de beschikbaarheidsgroep die inserts, updates en verwijderingen kan verwerken. Zie Failover naar een secundaire beschikbaarheidsgroep voor informatie over het uitvoeren van een failover van een gedistribueerde beschikbaarheidsgroep naar een andere.
Opmerking
- Gedistribueerde beschikbaarheidsgroepen in SQL Server 2016 ondersteunen failover van slechts één beschikbaarheidsgroep naar een andere met behulp van de optie
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Wanneer u transactionele replicatie met gedistribueerde beschikbaarheidsgroepen gebruikt, kan de forwarder replica niet worden geconfigureerd als uitgever.
SQL Server 2025-wijzigingen
SQL Server 2025 (17.x) introduceert de volgende wijzigingen:
Verbetering van gedistribueerde ag-synchronisatie
SQL Server 2025 (17.x) introduceert een wijziging in het interne synchronisatiemechanisme voor gedistribueerde beschikbaarheidsgroepen om de synchronisatieprestaties te verbeteren door de netwerkverzadiging te verminderen wanneer de doorstuurserverreplica zich in de asynchrone doorvoermodus bevindt. Deze wijziging is standaard ingeschakeld en vereist geen configuratie.
Opmerking
Het configureren van uw gedistribueerde beschikbaarheidsgroep met een onjuiste overeenkomst tussen de beschikbaarheidsmodi van de twee onderliggende beschikbaarheidsgroepen wordt niet aanbevolen en kan synchronisatielatentie veroorzaken. Beide beschikbaarheidsgroepen moeten worden geconfigureerd met dezelfde beschikbaarheidsmodus (synchroon of asynchroon) om optimale prestaties en synchronisatie te garanderen.
Ondersteuning voor beperkte beschikbaarheidsgroepen
SQL Server 2025 (17.x) introduceert ondersteuning voor een gedistribueerde ingesloten beschikbaarheidsgroep. Als u van plan bent om een ingesloten beschikbaarheidsgroep te gebruiken als doorstuurserver in een gedistribueerde beschikbaarheidsgroep, moet u de ingesloten beschikbaarheidsgroep maken door gebruik te maken van de AUTOSEEDING_SYSTEM_DATABASES clausule voor de WITH | CONTAINED optie in de opdracht CREATE AVAILABILITY GROUP.
Versie- en editievereisten
Gedistribueerde beschikbaarheidsgroepen in SQL Server 2017 of hoger kunnen primaire versies van SQL Server combineren in dezelfde gedistribueerde beschikbaarheidsgroep. De beschikbaarheidsgroep met primaire lees-/schrijf-bevoegdheden kan dezelfde versie of lager zijn dan de andere beschikbaarheidsgroepen die deelnemen aan de gedistribueerde beschikbaarheidsgroep. De andere AG's kunnen dezelfde versie hebben of een hogere. Dit scenario is gericht op upgrade- en migratiescenario's. Als de beschikbaarheidsgroep met de primaire replica lezen/schrijven bijvoorbeeld SQL Server 2016 is, maar u wilt upgraden/migreren naar SQL Server 2017 of hoger, kan de andere ag die deelneemt aan de gedistribueerde beschikbaarheidsgroep, worden geconfigureerd met SQL Server 2017.
Omdat de functie gedistribueerde beschikbaarheidsgroepen niet bestond in SQL Server 2012 of 2014, kunnen beschikbaarheidsgroepen die met deze versies zijn gemaakt, niet deelnemen aan gedistribueerde beschikbaarheidsgroepen.
Opmerking
Afhankelijk van de versie van SQL Server, is het mogelijk om wanneer er verbinding wordt gemaakt met Azure-services (zoals de Managed Instance-koppeling) een gedistribueerde groep voor beschikbaarheid te configureren met de Standard-editie of een combinatie van Standard- en Enterprise-editie. Bekijk KB5016729 voor meer informatie.
Omdat er twee afzonderlijke beschikbaarheidsgroepen zijn, verschilt het proces van het installeren van een servicepack of cumulatieve update op een replica die deelneemt aan een gedistribueerde beschikbaarheidsgroep iets anders dan die van een traditionele beschikbaarheidsgroep:
Begin met het bijwerken van de replica's van de tweede beschikbaarheidsgroep in de gedistribueerde beschikbaarheidsgroep.
Patch de replica's van de primaire beschikbaarheidsgroep in de gedistribueerde beschikbaarheidsgroep.
Net als bij een standaard beschikbaarheidsgroep draagt u de primaire beschikbaarheidsgroep over naar een van de eigen replica's (niet naar de primaire van de tweede beschikbaarheidsgroep) en voert u een patch uit. Als er geen andere replica dan de primaire replica is, is een handmatige failover naar de tweede beschikbaarheidsgroep nodig.
Windows Server-versies en gedistribueerde beschikbaarheidsgroepen
Een gedistribueerde beschikbaarheidsgroep omvat meerdere beschikbaarheidsgroepen, elk op een eigen onderliggende WSFC en een gedistribueerde beschikbaarheidsgroep is een alleen-SQL Server-constructie. Dit betekent dat de WSFCs die de afzonderlijke beschikbaarheidsgroepen bevatten, verschillende primaire versies van Windows Server kunnen hebben. De primaire versies van SQL Server moeten hetzelfde zijn, zoals besproken in de vorige sectie. Net als in de eerste afbeelding ziet u in de volgende afbeelding ag 1 en AG 2 die deelnemen aan een gedistribueerde beschikbaarheidsgroep, maar elk van de WSFCs is een andere versie van Windows Server.
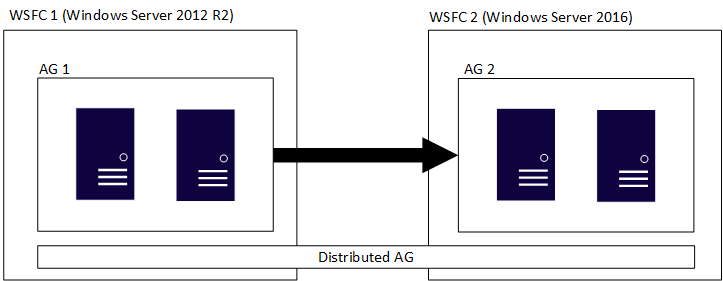
De afzonderlijke WSFCs en de bijbehorende beschikbaarheidsgroepen volgen traditionele regels. Dat wil gezegd, ze kunnen worden toegevoegd aan een domein of niet worden toegevoegd aan een domein (Windows Server 2016 of hoger). Wanneer twee verschillende beschikbaarheidsgroepen worden gecombineerd in één gedistribueerde beschikbaarheidsgroep, zijn er vier scenario's:
- Beide WSFCs zijn gekoppeld aan hetzelfde domein.
- Elke WSFC wordt toegevoegd aan een ander domein.
- Eén WSFC is gekoppeld aan een domein en één WSFC is niet gekoppeld aan een domein.
- Geen van beide WSFC's is verbonden met een domein.
Wanneer beide WSFCs lid zijn van hetzelfde domein (geen vertrouwde domeinen), hoeft u niets speciaals te doen wanneer u de gedistribueerde beschikbaarheidsgroep maakt. Voor beschikbaarheidsgroepen en WSFCs die niet aan hetzelfde domein zijn toegevoegd, gebruikt u certificaten om de gedistribueerde beschikbaarheidsgroep te laten werken, veel op de manier waarop u een beschikbaarheidsgroep kunt maken voor een domeinonafhankelijke beschikbaarheidsgroep. Als u wilt zien hoe u certificaten voor een gedistribueerde beschikbaarheidsgroep configureert, volgt u stap 3-13 onder Een domeinonafhankelijke beschikbaarheidsgroep maken.
Met een gedistribueerde beschikbaarheidsgroep moeten de primaire replica's in elke onderliggende beschikbaarheidsgroep elkaars certificaten hebben. Als u al eindpunten hebt die geen certificaten gebruiken, configureert u deze eindpunten opnieuw met ALTER ENDPOINT om het gebruik van certificaten weer te geven.
Gebruiksscenario's
Dit zijn de drie belangrijkste gebruiksscenario's voor een gedistribueerde beschikbaarheidsgroep:
- Herstel na noodgevallen en eenvoudigere configuraties voor meerdere sites
- Migratie naar nieuwe hardware of configuraties, waaronder het gebruik van nieuwe hardware of het wijzigen van de onderliggende besturingssystemen
- Het aantal leesbare replica's uitbreiden tot meer dan acht in één beschikbaarheidsgroep door meerdere beschikbaarheidsgroepen te overspannen
Scenario's voor herstel na noodgevallen en scenario's met meerdere sites
Een traditionele beschikbaarheidsgroep vereist dat alle servers deel uitmaken van dezelfde WSFC, wat het uitdagend kan maken om meerdere datacenters te overspannen. In de volgende afbeelding ziet u hoe een traditionele architectuur voor een beschikbaarheidsgroep met meerdere sites eruitziet, inclusief de gegevensstroom. Er is één primaire replica die transacties naar alle secundaire replica's verzendt. Deze configuratie is op sommige manieren minder dan een gedistribueerde beschikbaarheidsgroep. U moet bijvoorbeeld zaken implementeren zoals Active Directory (indien van toepassing) en de getuige voor een quorum in de WSFC. Mogelijk moet u ook rekening houden met andere aspecten van een WSFC, zoals het wijzigen van knooppuntstemmen.

Gedistribueerde beschikbaarheidsgroepen bieden een flexibeler implementatiescenario voor beschikbaarheidsgroepen die meerdere datacenters omvatten. U kunt zelfs gedistribueerde beschikbaarheidsgroepen gebruiken waarbij functies zoals logboekverzending in het verleden zijn gebruikt voor scenario's zoals herstel na noodgevallen. In tegenstelling tot verzending van logboeken kunnen gedistribueerde beschikbaarheidsgroepen echter geen vertraagde toepassing van transacties hebben. Dit betekent dat beschikbaarheidsgroepen of gedistribueerde beschikbaarheidsgroepen niet kunnen helpen in het geval van menselijke fouten waarin gegevens onjuist worden bijgewerkt of verwijderd.
Gedistribueerde beschikbaarheidsgroepen zijn losjes gekoppeld, wat in dit geval betekent dat ze geen enkele WSFC nodig hebben en dat ze worden onderhouden door SQL Server. Omdat de WSFCs afzonderlijk worden onderhouden en de synchronisatie voornamelijk asynchroon is tussen de twee beschikbaarheidsgroepen, is het eenvoudiger om herstel na noodgevallen op een andere site te configureren. De primaire replica's in elke beschikbaarheidsgroep synchroniseren hun eigen secundaire replica's.
- Alleen handmatige failover wordt ondersteund voor een gedistribueerde beschikbaarheidsgroep. In een situatie voor herstel na noodgevallen waarbij u overschakelt naar datacenters, moet u geen automatische failover configureren (met zeldzame uitzonderingen).
- U hoeft waarschijnlijk geen van de traditionele items of parameters in te stellen voor WSFC's voor meerdere sites of subnetten, zoals CrossSubnetThreshold, maar u moet nog steeds letten op netwerklatentie op een ander niveau voor de gegevensoverdracht. Het verschil is dat elke WSFC zijn eigen beschikbaarheid behoudt; het cluster is niet één grote entiteit van vier knooppunten. U hebt twee afzonderlijke WSFC's met twee knooppunten, zoals wordt weergegeven in de vorige afbeelding.
- We raden asynchrone gegevensverplaatsing aan, omdat deze aanpak voor noodhersteldoeleinden zou zijn.
- Als u synchrone gegevensverplaatsing tussen de primaire replica en ten minste één secundaire replica van de tweede beschikbaarheidsgroep configureert en u synchrone verplaatsing configureert voor de gedistribueerde beschikbaarheidsgroep, wacht een gedistribueerde beschikbaarheidsgroep totdat alle synchrone kopieën bevestigen dat ze de gegevens hebben. Als meerdere gedistribueerde beschikbaarheidsgroepen daisy-chained zijn (AG1 -> AG2 -> AG3) en zijn ingesteld op synchroon, wacht een gedistribueerde beschikbaarheidsgroep tot de laatste replica van de laatste beschikbaarheidsgroep is bijgewerkt.
Migreren
Omdat gedistribueerde beschikbaarheidsgroepen twee volledig verschillende configuraties van beschikbaarheidsgroepen ondersteunen, maken ze niet alleen eenvoudiger herstel na noodgevallen en scenario's met meerdere sites mogelijk, maar ook migratiescenario's. Of u nu migreert naar nieuwe hardware of virtuele machines (on-premises of IaaS in de openbare cloud), waarbij u een gedistribueerde beschikbaarheidsgroep configureert, kan een migratie plaatsvinden waarbij u in het verleden mogelijk back-up, kopieer en herstel of logboekverzending hebt gebruikt.
De mogelijkheid om te migreren is vooral handig in scenario's waarin u het onderliggende besturingssysteem wijzigt of upgradet terwijl u dezelfde SQL Server-versie behoudt. Hoewel Windows Server 2016 een rolling upgrade van Windows Server 2012 R2 op dezelfde hardware toestaat, kiezen de meeste gebruikers ervoor om nieuwe hardware of virtuele machines te implementeren.
Als u de migratie naar de nieuwe configuratie wilt voltooien, stopt u aan het einde van het proces alle gegevensverkeer naar de oorspronkelijke beschikbaarheidsgroep en wijzigt u de gedistribueerde beschikbaarheidsgroep in synchrone gegevensverplaatsing. Deze actie zorgt ervoor dat de primaire replica van de tweede beschikbaarheidsgroep volledig is gesynchroniseerd, zodat er geen gegevensverlies zou optreden. Nadat u de synchronisatie hebt geverifieerd, voert u een failover uit van de gedistribueerde beschikbaarheidsgroep naar de secundaire beschikbaarheidsgroep. Zie Failover naar een secundaire beschikbaarheidsgroep voor meer informatie.
Na de migratie, waarbij de tweede beschikbaarheidsgroep nu de nieuwe primaire beschikbaarheidsgroep is, moet u mogelijk een van de volgende stappen uitvoeren:
- Wijzig de naam van de listener in de secundaire beschikbaarheidsgroep (en verwijder of wijzig de naam van de oude in de oorspronkelijke primaire beschikbaarheidsgroep) of maak deze opnieuw met de listener van de oorspronkelijke primaire beschikbaarheidsgroep, zodat toepassingen en gebruikers toegang hebben tot de nieuwe configuratie.
- Als een naam wijzigen of opnieuw maken niet mogelijk is, wijst u toepassingen en gebruikers aan bij de listener in de tweede beschikbaarheidsgroep.
Migreren naar hogere SQL Server-versies
Tijdens een migratiescenario is het mogelijk om een gedistribueerde beschikbaarheidsgroep te configureren om uw databases te migreren naar een SQL Server-doelserver met een hogere versie dan de bron, maar zijn er enkele beperkingen.
Wanneer u de gedistribueerde beschikbaarheidsgroep configureert met een SQL Server-migratiedoel dat een hogere versie is dan de bron, wordt autoseeding niet ondersteund, zodat de zaaimodus moet worden ingesteld op MANUAL. Als u AUTO-SEEDING niet uitschakelt, mislukt de migratie en ziet u foutmelding 946 "Kan de database 'DistributionAG' versie xxx niet openen." Werk de database bij naar de nieuwste versie in het foutenlogboek. U moet de seedingmodus instellen op HANDMATIG en handmatig een volledige en transactielogboekback-up van de brondatabase uitvoeren vanuit de primaire beschikbaarheidsgroep. Herstel het vervolgens handmatig, samen met het transactielogboek, naar de secundaire AG. Raadpleeg de handmatige seedingstappen voor het configureren van uw gedistribueerde beschikbaarheidsgroep en scripts voor het maken van back-ups en het herstellen van uw database van de primaire AG naar de secundaire AG voor meer informatie.
Ervan uitgaande dat de secundaire AG (AG2) het migratiedoel is en een hogere versie is dan de primaire AG (AG1), moet u rekening houden met de volgende beperkingen:
- U hebt geen leestoegang tot een van de replicadatabases in de secundaire AG, zolang de primaire ag een lagere versie heeft.
- Gedurende deze tijd blijven updates van de primaire AG (AG1) naar de secundaire AG (AG2) stromen, maar de status van de secundaire AG wordt weergegeven als Gedeeltelijk in orde en databases op secundaire replica's van de secundaire AG (AG2) worden weergegeven als Syncizing/In Recovery (zelfs als de AG zich in synchronisatie-doorvoer bevindt).
- Zodra de gedistribueerde beschikbaarheidsgroep is overgeschakeld naar een hogere versie (AG2), moet AG2 gezond worden.
- Gedurende deze tijd is failback naar AG1 niet mogelijk, omdat deze zich in een lagere versie bevindt.
- Omdat AG1 een lagere versie heeft, worden updates van AG2 na een failover naar AG2 niet gerepliceerd naar AG1.
- Kies hier of u de oorspronkelijke (primaire) AG buiten gebruik wilt stellen of als u AG1 wilt upgraden en de gedistribueerde ag wilt onderhouden.
- Als u ervoor kiest AG1 buiten gebruik te stellen, verwijdert u de oorspronkelijke primaire ag uit de gedistribueerde ag en is het proces voltooid.
- Als u ervoor kiest om AG te behouden, voert u een upgrade uit van de SQL Server-versie voor AG1 zodat deze overeenkomt met AG2. Zodra AG1 is bijgewerkt, wordt AG1 in orde, wordt de gedistribueerde beschikbaarheidsgroep in orde, worden de replica's ingehaald om te synchroniseren en wordt failback mogelijk.
Leesbare replica's uitschalen
Eén gedistribueerde beschikbaarheidsgroep kan naar behoefte maximaal 16 secundaire replica's hebben. Er kunnen dus maximaal 18 exemplaren zijn voor lezen, inclusief de twee primaire replica's die deel uitmaken van de verschillende beschikbaarheidsgroepen. Deze aanpak betekent dat meer dan één site bijna realtime toegang kan hebben voor rapportage aan verschillende toepassingen.
Gedistribueerde beschikbaarheidsgroepen kunnen helpen bij het opschalen van een alleen-lezen cluster meer dan alleen met een enkele beschikbaarheidsgroep. Een gedistribueerde beschikbaarheidsgroep kan leesbare replica's op twee manieren uitschalen:
- U kunt de primaire replica van de tweede beschikbaarheidsgroep in een gedistribueerde beschikbaarheidsgroep gebruiken om een andere gedistribueerde beschikbaarheidsgroep te maken, ook al bevindt de database zich niet in RECOVERY.
- U kunt ook de primaire replica van de eerste beschikbaarheidsgroep gebruiken om een andere gedistribueerde beschikbaarheidsgroep te maken.
Met andere woorden, een primaire replica kan deelnemen aan verschillende gedistribueerde beschikbaarheidsgroepen. In de volgende afbeelding ziet u AG 1 en AG 2 die beide deelnemen aan Distributed AG 1, terwijl AG 2 en AG 3 deelnemen aan gedistribueerde AG 2. De primaire replica (of doorstuurserver) van AG 2 is zowel een secundaire replica voor gedistribueerde AG 1 als een primaire replica van gedistribueerde AG 2.
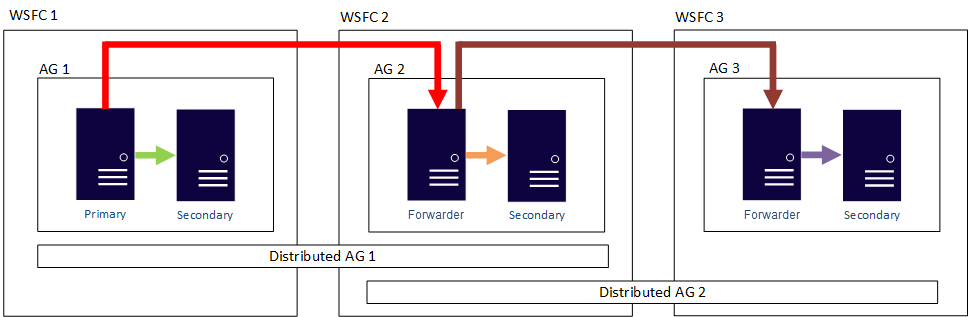
In de volgende afbeelding ziet u AG 1 als primaire replica voor twee verschillende gedistribueerde beschikbaarheidsgroepen: Gedistribueerde BESCHIKBAARHEIDSGROEP 1 (samengesteld uit AG 1 en AG2) en Gedistribueerde AG 2 (samengesteld uit AG 1 en AG 3).
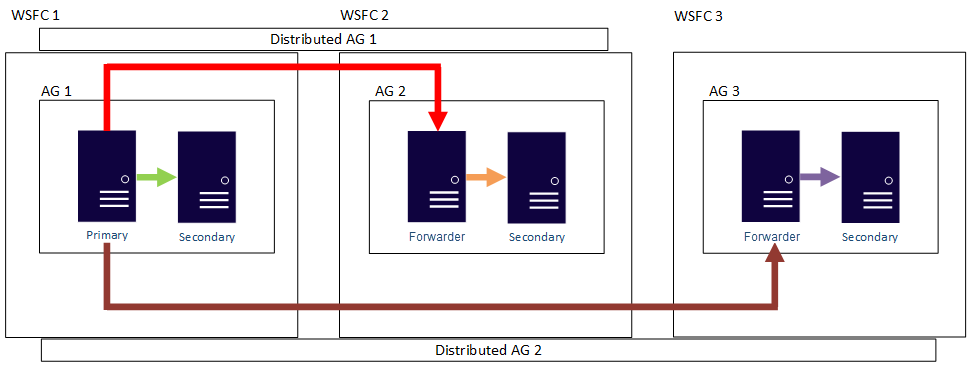
In beide voorgaande voorbeelden kunnen er maximaal 27 totale replica's zijn voor de drie beschikbaarheidsgroepen, die allemaal kunnen worden gebruikt voor alleen-lezen query's.
Alleen-lezenroutering werkt niet volledig met gedistribueerde beschikbaarheidsgroepen. Meer specifiek,
- Read-Only Routering kan worden geconfigureerd en werkt voor de primaire beschikbaarheidsgroep van de gedistribueerde beschikbaarheidsgroep.
- Read-Only Routering kan worden geconfigureerd, maar werkt niet voor de secundaire beschikbaarheidsgroep van de gedistribueerde beschikbaarheidsgroep. Als alle query's de listener gebruiken om verbinding te maken met de secundaire beschikbaarheidsgroep, worden ze doorgestuurd naar de primaire replica van de secundaire beschikbaarheidsgroep. Anders moet u elke replica zo configureren dat alle verbindingen als secundaire replica rechtstreeks toegankelijk zijn. Alleen-lezenroutering werkt echter als de secundaire beschikbaarheidsgroep na een failover primair wordt. Dit gedrag kan worden gewijzigd in een update van SQL Server 2016 of in een toekomstige versie van SQL Server.
Secundaire beschikbaarheidsgroepen initialiseren
Gedistribueerde beschikbaarheidsgroepen zijn ontworpen met automatische seeding als de belangrijkste methode die wordt gebruikt voor het initialiseren van de primaire replica in de tweede beschikbaarheidsgroep. Een volledig databaseherstel op de primaire replica van de tweede beschikbaarheidsgroep is mogelijk als u het volgende doet:
- Herstel de database-back-up met NORECOVERY.
- Herstel zo nodig de juiste back-ups van transactielogboeken MET NORECOVERY.
- Maak de tweede beschikbaarheidsgroep zonder een databasenaam op te geven en met SEEDING_MODE ingesteld op AUTOMATISCH.
- Maak de gedistribueerde beschikbaarheidsgroep met behulp van automatische seeding.
Wanneer u de primaire replica van de tweede beschikbaarheidsgroep toevoegt aan de gedistribueerde beschikbaarheidsgroep, wordt de replica gecontroleerd ten opzichte van de primaire databases van de eerste beschikbaarheidsgroep en wordt de database automatisch bijgewerkt tot de bron. Er zijn enkele opmerkingen:
In de uitvoer die in
sys.dm_hadr_automatic_seedingwordt weergegeven op de primaire replica van de tweede beschikbaarheidsgroep, zal eencurrent_statede status FAILED tonen met als reden "Time-out van seedingcheckbericht".In het huidige SQL Server-foutenlogboek op de primaire replica van de tweede beschikbaarheidsgroep ziet u dat automatische seeding heeft gewerkt en dat de LSN's zijn gesynchroniseerd.
In de uitvoer op de primaire replica
sys.dm_hadr_automatic_seedingvan de eerste beschikbaarheidsgroep wordt een state weergegeven die op VOLTOOID staat.Automatische seeding heeft ook ander gedrag met gedistribueerde beschikbaarheidsgroepen. Als u automatische seeding wilt laten beginnen op de tweede replica, moet u de opdrachtopdracht
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEop de replica uitvoeren. Hoewel deze voorwaarde nog steeds geldt voor een secundaire replica die deelneemt aan de onderliggende beschikbaarheidsgroep, heeft de primaire replica van de tweede beschikbaarheidsgroep al de juiste machtigingen om automatische seeding toe te staan om te beginnen nadat deze is toegevoegd aan de gedistribueerde beschikbaarheidsgroep.
Opmerking
- De secundaire beschikbaarheidsgroep moet hetzelfde eindpunt voor databasespiegeling gebruiken. Anders stopt de replicatie na een lokale failover.
- De onderliggende beschikbaarheidsgroepen moeten zich in dezelfde beschikbaarheidsmodus bevinden: beide beschikbaarheidsgroepen moeten zich in de synchrone doorvoermodus bevinden of beide moeten zich in de asynchrone doorvoermodus bevinden. Als u niet zeker weet welke bewerking moet worden gebruikt, stelt u beide in op de asynchrone doorvoermodus totdat u klaar bent om een failover uit te voeren.
Gezondheidsmonitoring
Een gedistribueerde beschikbaarheidsgroep is een alleen-SQL Server-constructie en wordt niet weergegeven in de onderliggende WSFC. In het volgende codevoorbeeld ziet u twee verschillende WSFCs (CLUSTER_A en CLUSTER_B), elk met een eigen beschikbaarheidsgroep. Alleen AG1 in CLUSTER_A en AG2 in CLUSTER_B worden hier besproken.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
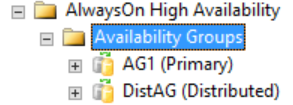
Alle gedetailleerde informatie over een gedistribueerde beschikbaarheidsgroep bevindt zich in SQL Server, met name in de dynamische beheerweergaven van de beschikbaarheidsgroep. Op dit moment bevindt de enige informatie die wordt weergegeven in SQL Server Management Studio voor een gedistribueerde beschikbaarheidsgroep zich op de primaire replica voor de beschikbaarheidsgroepen. Zoals weergegeven in de volgende afbeelding, onder de map Beschikbaarheidsgroepen, laat SQL Server Management Studio zien dat er een gedistribueerde beschikbaarheidsgroep is. In de afbeelding ziet u AG1 als primaire replica voor een individuele beschikbaarheidsgroep die lokaal is voor de instantie, niet voor een gedistribueerde beschikbaarheidsgroep.
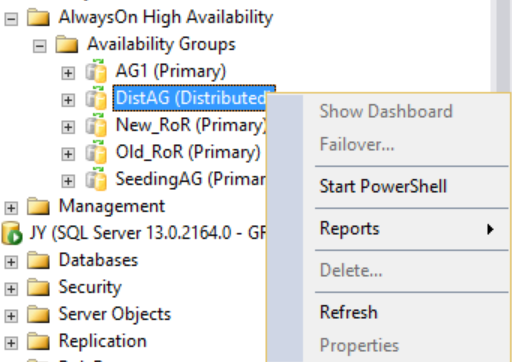
Als u echter met de rechtermuisknop op de gedistribueerde beschikbaarheidsgroep klikt, zijn er geen opties beschikbaar (zie de volgende afbeelding) en de uitgebreide mappen Beschikbaarheidsdatabases, Listeners voor beschikbaarheidsgroepen en Beschikbaarheidsreplica's zijn allemaal leeg. Dit resultaat wordt weergegeven in SQL Server Management Studio 16, maar dit kan veranderen in een toekomstige versie van SQL Server Management Studio.
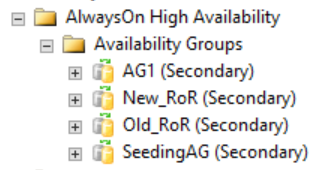
Zoals in de volgende afbeelding wordt weergegeven, tonen secundaire replica's niets in SQL Server Management Studio met betrekking tot de gedistribueerde beschikbaarheidsgroep. Deze namen van beschikbaarheidsgroepen komen overeen met de rollen die worden weergegeven in de vorige CLUSTER_A WSFC-afbeelding.
DMV om alle namen van beschikbaarheidsreplica's weer te geven
Dezelfde concepten zijn waar wanneer u de dynamische beheerweergaven gebruikt. Met behulp van de volgende query ziet u alle beschikbaarheidsgroepen (normaal en gedistribueerd) en de knooppunten die eraan deelnemen. Dit resultaat wordt alleen weergegeven als u een query uitvoert op de primaire replica in een van de WSFCs die deelnemen aan de gedistribueerde beschikbaarheidsgroep. Er is een nieuwe kolom in de dynamische beheerweergave sys.availability_groups met de naam is_distributed1 wanneer de beschikbaarheidsgroep een gedistribueerde beschikbaarheidsgroep is. Ga als volgt te werk om deze kolom te zien:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
In de volgende afbeelding ziet u een voorbeeld van uitvoer van de tweede WSFC die deelneemt aan een gedistribueerde beschikbaarheidsgroep. SPAG1 bestaat uit twee replica's: DENNIS en JY. De gedistribueerde beschikbaarheidsgroep met de naam SPDistAG heeft echter de namen van de twee deelnemende beschikbaarheidsgroepen (SPAG1 en SPAG2) in plaats van de namen van de exemplaren, zoals bij een traditionele beschikbaarheidsgroep.
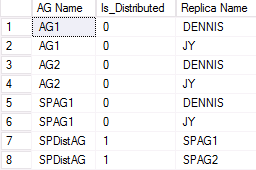
DMV om gedistribueerde AG-gezondheid weer te geven
In SQL Server Management Studio zijn alle statussen die worden weergegeven op het dashboard en andere gebieden, alleen voor lokale synchronisatie binnen die beschikbaarheidsgroep. Als u de status van een gedistribueerde beschikbaarheidsgroep wilt weergeven, voert u een query uit op de dynamische beheerweergaven. Met de volgende voorbeeldquery wordt de vorige query uitgebreid en verfijnd:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV voor het weergeven van onderliggende prestaties
Als u de vorige query verder wilt uitbreiden, kunt u ook de onderliggende prestaties zien via de dynamische beheerweergaven door ze toe sys.dm_hadr_database_replicas_stateste voegen. In de dynamische beheerweergave wordt momenteel alleen informatie over de tweede beschikbaarheidsgroep opgeslagen. De volgende voorbeeldquery, uitgevoerd op de primaire beschikbaarheidsgroep, produceert de voorbeelduitvoer die hieronder wordt weergegeven:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV om prestatiemeteritems voor gedistribueerde beschikbaarheidsgroep weer te geven
In de onderstaande query worden prestatiemeteritems weergegeven die zijn gekoppeld aan de specifieke gedistribueerde beschikbaarheidsgroep.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
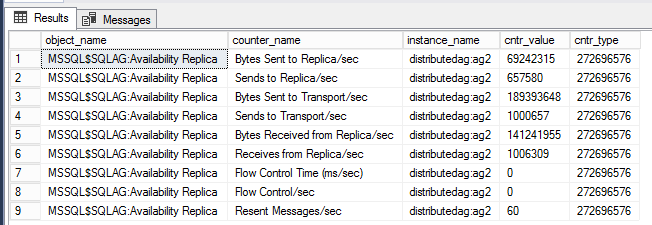
Opmerking
Het LIKE filter moet de naam van de gedistribueerde beschikbaarheidsgroep hebben. In dit voorbeeld is de naam van de gedistribueerde beschikbaarheidsgroep 'distributedag'. Wijzig de LIKE wijzigingsfunctie zodat deze overeenkomt met de naam van uw gedistribueerde beschikbaarheidsgroep.
DMV om de gezondheid van zowel AG als gedistribueerde AG weer te geven
In de onderstaande query ziet u een schat aan informatie over de status van zowel de beschikbaarheidsgroep als de gedistribueerde beschikbaarheidsgroep. (Gereproduceerd met toestemming van Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMV's om de metadata van gedistribueerde beschikbaarheidsgroepen weer te geven
In de onderstaande query's wordt informatie weergegeven over eindpunt-URL's die worden gebruikt door de beschikbaarheidsgroepen, inclusief de gedistribueerde beschikbaarheidsgroep. (Gereproduceerd met toestemming van David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV om de huidige status van seeding weer te geven
In de onderstaande query wordt informatie weergegeven over de huidige seedingstatus. Dit is handig voor het oplossen van synchronisatiefouten tussen replica's. (Gereproduceerd met toestemming van David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
