Azure Feature Pack for Integration Services (SSIS)
Applies to: ![]() SQL Server
SQL Server ![]() SSIS Integration Runtime in Azure Data Factory
SSIS Integration Runtime in Azure Data Factory
SQL Server Integration Services (SSIS) Feature Pack for Azure is an extension that provides the components listed on this page for SSIS to connect to Azure services, transfer data between Azure and on-premises data sources, and process data stored in Azure.
 Download SSIS Feature Pack for Azure
Download SSIS Feature Pack for Azure
- For SQL Server 2022 - Microsoft SQL Server 2022 Integration Services Feature Pack for Azure
- For SQL Server 2019 - Microsoft SQL Server 2019 Integration Services Feature Pack for Azure
- For SQL Server 2017 - Microsoft SQL Server 2017 Integration Services Feature Pack for Azure
- For SQL Server 2016 - Microsoft SQL Server 2016 Integration Services Feature Pack for Azure
- For SQL Server 2014 - Microsoft SQL Server 2014 Integration Services Feature Pack for Azure
- For SQL Server 2012 - Microsoft SQL Server 2012 Integration Services Feature Pack for Azure
The download pages also include information about prerequisites. Make sure you install SQL Server before you install the Azure Feature Pack on a server, or the components in the Feature Pack may not be available when you deploy packages to the SSIS Catalog database, SSISDB, on the server.
Components in the Feature Pack
Connection Managers
Tasks
Data Flow Components
Azure Blob, Azure Data Lake Store, and Data Lake Storage Gen2 File Enumerator. See Foreach Loop Container
Use TLS 1.2
The TLS version used by Azure Feature Pack follows system .NET Framework settings.
To use TLS 1.2, add a REG_DWORD value named SchUseStrongCrypto with data 1 under the following two registry keys.
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Dependency on Java
Java is required to use ORC/Parquet file formats with Azure Data Lake Store/Flexible File connectors.
The architecture (32/64-bit) of Java build should match that of the SSIS runtime to use.
The following Java builds have been tested.
Set Up Zulu's OpenJDK
- Download and extract the installation zip package.
- From the Command Prompt, run
sysdm.cpl. - On the Advanced tab, select Environment Variables.
- Under the System variables section, select New.
- Enter
JAVA_HOMEfor the Variable name. - Select Browse Directory, navigate to the extracted folder, and select the
jresubfolder. Then select OK, and the Variable value is populated automatically. - Select OK to close the New System Variable dialog box.
- Select OK to close the Environment Variables dialog box.
- Select OK to close the System Properties dialog box.
Tip
If you use Parquet format and hit error saying "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space", you can add an environment variable _JAVA_OPTIONS to adjust the min/max heap size for JVM.
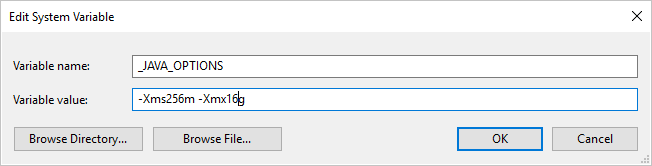
Example: set variable _JAVA_OPTIONS with value -Xms256m -Xmx16g. The flag Xms specifies the initial memory allocation pool for a Java Virtual Machine (JVM), while Xmx specifies the maximum memory allocation pool. This means that JVM will be started with Xms amount of memory and will be able to use a maximum of Xmx amount of memory. The default values are min 64MB and max 1G.
Set Up Zulu's OpenJDK on Azure-SSIS Integration Runtime
This should be done via custom setup interface for Azure-SSIS Integration Runtime.
Suppose zulu8.33.0.1-jdk8.0.192-win_x64.zip is used.
The blob container could be organized as follows.
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
As the entry point, main.cmd triggers execution of the PowerShell script install_openjdk.ps1 which in turn extracts zulu8.33.0.1-jdk8.0.192-win_x64.zip and sets JAVA_HOME accordingly.
main.cmd
powershell.exe -file install_openjdk.ps1
Tip
If you use Parquet format and hit error saying "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space", you can add command in main.cmd to adjust the min/max heap size for JVM. Example:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
The flag Xms specifies the initial memory allocation pool for a Java Virtual Machine (JVM), while Xmx specifies the maximum memory allocation pool. This means that JVM will be started with Xms amount of memory and will be able to use a maximum of Xmx amount of memory. The default values are min 64MB and max 1G.
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Set Up Oracle's Java SE Runtime Environment
- Download and run the exe installer.
- Follow the installer instructions to complete setup.
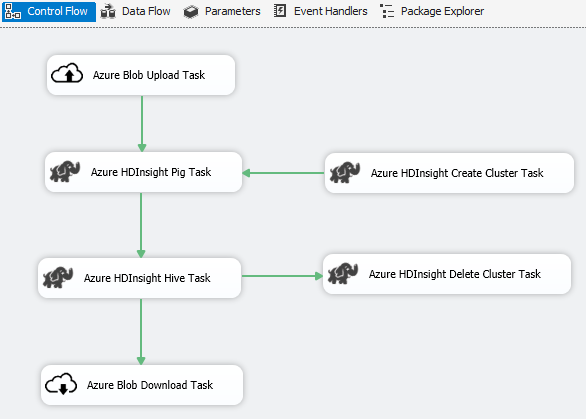
Scenario: Processing big data
Use Azure Connector to complete following big data processing work:
Use the Azure Blob Upload Task to upload input data to Azure Blob Storage.
Use the Azure HDInsight Create Cluster Task to create an Azure HDInsight cluster. This step is optional if you want to use your own cluster.
Use the Azure HDInsight Hive Task or Azure HDInsight Pig Task to invoke a Pig or Hive job on the Azure HDInsight cluster.
Use the Azure HDInsight Delete Cluster Task to delete the HDInsight Cluster after use if you have created an on-demand HDInsight cluster in step #2.
Use the Azure HDInsight Blob Download Task to download the Pig/Hive output data from the Azure Blob Storage.
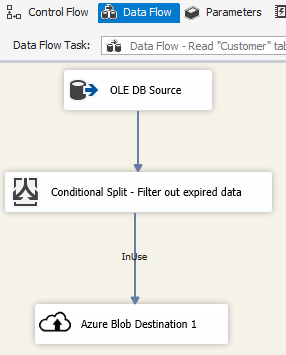
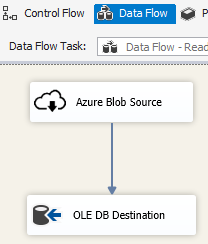
Scenario: Managing data in the cloud
Use the Azure Blob Destination in an SSIS package to write output data to Azure Blob Storage, or use the Azure Blob Source to read data from an Azure Blob Storage.
Use the Foreach Loop Container with the Azure Blob Enumerator to process data in multiple blob files.
Release Notes
Version 1.21.0
Improvements
- Upgraded log4j from version 1.2.17 to 2.17.1.
Version 1.20.0
Improvements
- Updated target .NET Framework version from 4.6 to 4.7.2.
- Renamed "Azure SQL DW Upload Task" to "Azure Synapse Analytics Task".
Bugfixes
- When accessing Azure Blob Storage and the machine running SSIS is in a non en-US locale, package execution will fail with error message "String not recognized as a valid DateTime value".
- For Azure Storage Connection Manager, secret is required (and unused) even when Data Factory managed identity is used to authenticate.
Version 1.19.0
Improvements
- Added support for shared access signature authentication to Azure Storage connection manager.
Version 1.18.0
Improvements
- For Flexible File task, three are three improvements: (1) wildcard support for copy/delete operations is added; (2) user can enable/disable recursive searching for delete operation; and (3) the file name of Destination for copy operation can be empty to keep the source file name.
Version 1.17.0
This is a hotfix version released for SQL Server 2019 only.
Bugfixes
- When executing in Visual Studio 2019 and targeting SQL Server 2019, Flexible File Task/Source/Destination may fail with the error message
Attempted to access an element as a type incompatible with the array. - When executing in Visual Studio 2019 and targeting SQL Server 2019, Flexible File Source/Destination using ORC/Parquet format may fail with the error message
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException.
Version 1.16.0
Bugfixes
- In certain cases, package execution reports "Error: Could not load file or assembly 'Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed' or one of its dependencies."
Version 1.15.0
Improvements
- Add delete folder/file operation to Flexible File Task
- Add External/Output data type convert function in Flexible File Source
Bugfixes
- In certain cases, test connection malfunctions for Data Lake Storage Gen2 with the error message "Attempted to access an element as a type incompatible with the array"
- Bring back support for Azure Storage Emulator