Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server op Linux
SQL Server op Linux
In dit artikel worden de kenmerken van beschikbaarheidsgroepen (AG's) beschreven onder SQL Server-installaties op basis van Linux. Het behandelt ook verschillen tussen Linux- en Windows Server-failoverclusters (WSFC) die gebaseerd zijn op AG's. Zie Wat is een AlwaysOn-beschikbaarheidsgroep? voor de basisprincipes van AG's, omdat ze hetzelfde werken in Windows en Linux, met uitzondering van de WSFC.
Opmerking
In beschikbaarheidsgroepen die geen gebruikmaken van Windows Server Failover Clustering (WSFC), zoals beschikbaarheidsgroepen met leesschaal of beschikbaarheidsgroepen op Linux, kunnen kolommen in de DMV's van de beschikbaarheidsgroepen die zijn gerelateerd aan het cluster gegevens over een intern standaardcluster weergeven. Deze kolommen zijn alleen bedoeld voor intern gebruik en kunnen worden genegeerd.
Vanuit een algemeen oogpunt zijn beschikbaarheidsgroepen onder SQL Server op Linux hetzelfde als op WSFC gebaseerde implementaties. Dat betekent dat alle beperkingen en functies hetzelfde zijn, met enkele uitzonderingen. De belangrijkste verschillen zijn:
- Microsoft Distributed Transaction Coordinator (DTC) wordt ondersteund onder Linux vanaf SQL Server 2017 CU 16. DTC wordt echter nog niet ondersteund in beschikbaarheidsgroepen in Linux. Als uw toepassingen het gebruik van gedistribueerde transacties vereisen en een AG nodig hebben, implementeert u SQL Server in Windows.
- Implementaties op basis van Linux waarvoor hoge beschikbaarheid is vereist, maken gebruik van Pacemaker voor clustering in plaats van een WSFC.
- In tegenstelling tot de meeste configuraties voor AG's in Windows, met uitzondering van het scenario Werkgroepcluster, vereist Pacemaker nooit Active Directory Domain Services (AD DS).
- Het mislukken van een beschikbaarheidsgroep van het ene knooppunt naar het andere is anders tussen Linux en Windows.
- Bepaalde instellingen, zoals
required_synchronized_secondaries_to_commit, kunnen alleen worden gewijzigd via Pacemaker op Linux, terwijl een installatie op basis van WSFC gebruikmaakt van Transact-SQL.
Aantal replica's en clusterknooppunten
Een AG in SQL Server Standard-editie kan twee totaalreplica's hebben: één primaire en één secundaire replica die alleen kan worden gebruikt voor beschikbaarheidsdoeleinden. Het kan niet worden gebruikt voor iets anders, zoals leesbare query's. Een AG in SQL Server Enterprise-editie kan maximaal negen totale replica's hebben: één primaire en maximaal acht secundaire replica's, waarvan maximaal drie (inclusief de primaire) synchroon kunnen zijn. Als u een onderliggend cluster gebruikt, kan er een totaal van maximaal 16 knooppunten zijn wanneer Corosync wordt gebruikt. Een beschikbaarheidsgroep kan maximaal negen van de 16 knooppunten omvatten met de SQL Server Enterprise-editie en twee met de SQL Server Standard-editie.
Voor een configuratie met twee replica's waarvoor de mogelijkheid is vereist om automatisch een failover naar een andere replica uit te voeren, is het gebruik van een alleen-configuratiereplica vereist, zoals beschreven in alleen-configuratiereplica en quorum. Configuratie-alleen replica's werden geïntroduceerd in SQL Server 2017 (14.x) Cumulatieve update 1 (CU 1), en dus moet dit de minimale versie zijn die voor deze configuratie wordt gebruikt.
Als Pacemaker wordt gebruikt, moet deze correct worden geconfigureerd, zodat deze actief blijft. Dit betekent dat quorum en fencing van een vastgelopen knooppunt correct moeten worden geïmplementeerd vanuit het perspectief van Pacemaker, naast eventuele SQL Server-vereisten zoals een configuratiereplica.
Leesbare secundaire replica's worden alleen ondersteund met de SQL Server Enterprise-editie.
Clustertype en failovermodus
Nieuw bij SQL Server 2017 (14.x) is de introductie van een clustertype voor AG's. Voor Linux zijn er twee geldige waarden: Extern en Geen. Een clustertype Extern betekent dat Pacemaker wordt gebruikt onder de AG. Als u Extern voor clustertype gebruikt, moet de failovermodus ook zijn ingesteld op Extern (ook nieuw in SQL Server 2017 (14.x)). Automatische failover wordt ondersteund, maar in tegenstelling tot een WSFC is de failovermodus ingesteld op Extern, niet automatisch, wanneer Pacemaker wordt gebruikt. In tegenstelling tot een WSFC wordt het gedeelte van de AG dat door Pacemaker wordt beheerd, gemaakt nadat de AG is geconfigureerd.
Een clustertype 'Geen' betekent dat er geen vereiste is voor, noch gebruikt de AG, Pacemaker. Zelfs op servers waarop Pacemaker is geconfigureerd, als een AG is geconfigureerd met het clustertype None, ziet of beheert Pacemaker die AG niet. Een clustertype None ondersteunt alleen handmatige failover van een primaire naar een secundaire replica. Een AG die met de optie 'None' is gemaakt, is voornamelijk gericht op upgrades en het vergroten van de leescapaciteit. Hoewel het kan functioneren in scenario's zoals herstel na noodsituaties of lokale beschikbaarheid waar geen automatische failover nodig is, wordt dit niet aanbevolen. Het verhaal van de listener is ook complexer zonder Pacemaker.
Het clustertype wordt opgeslagen in de dynamische beheerweergave van SQL Server (DMV), sys.availability_groupsin de kolommen cluster_type en cluster_type_desc.
vereiste_gesynchroniseerde_secundaires_om_te_committen
Nieuw bij SQL Server 2017 (14.x) is een instelling die wordt gebruikt door AG's met de naam required_synchronized_secondaries_to_commit. Dit geeft de AG het aantal secundaire replica's aan dat gesynchroniseerd moet zijn met de primaire replica. Dit maakt zaken zoals automatische failover mogelijk (alleen als deze is geïntegreerd met Pacemaker met een clustertype Extern) en bepaalt het gedrag van zaken zoals de beschikbaarheid van de primaire replica als het juiste aantal secundaire replica's online of offline is. Voor meer informatie over hoe dit werkt, raadpleegt u Hoge beschikbaarheid en gegevensbeveiliging voor configuraties van beschikbaarheidsgroepen. De required_synchronized_secondaries_to_commit waarde wordt standaard ingesteld en onderhouden door Pacemaker/SQL Server. U kunt deze waarde handmatig overschrijven.
De combinatie van required_synchronized_secondaries_to_commit en het nieuwe volgnummer (dat is opgeslagen in sys.availability_groups) informeert Pacemaker en SQL Server dat bijvoorbeeld automatische failover kan plaatsvinden. In dat geval zou een secundaire replica hetzelfde volgnummer hebben als de primaire, wat betekent dat deze up-to-date is met alle meest recente configuratiegegevens.
Er zijn drie waarden die kunnen worden ingesteld voor required_synchronized_secondaries_to_commit: 0, 1 of 2. Ze bepalen het gedrag van wat er gebeurt wanneer een replica niet meer beschikbaar is. De getallen komen overeen met het aantal secundaire replica's dat moet worden gesynchroniseerd met de primaire replica. Het gedrag is als volgt onder Linux:
| Configuratie | Beschrijving |
|---|---|
0 |
Secundaire replica's hoeven niet in een gesynchroniseerde status te zijn met de primaire replica. Als de secundaire bestanden echter niet worden gesynchroniseerd, is er geen automatische failover. |
1 |
Eén secundaire replica moet een gesynchroniseerde status hebben met de primaire replica; automatische failover is mogelijk. De primaire database is niet beschikbaar totdat er een secundaire synchrone replica beschikbaar is. |
2 |
Beide secundaire replica's in een ag-configuratie van drie of meer knooppunten moeten worden gesynchroniseerd met de primaire. automatische failover is mogelijk. |
required_synchronized_secondaries_to_commit beheert niet alleen het gedrag van failovers met synchrone replica's, maar gegevensverlies. Met de waarde 1 of 2 moet een secundaire replica altijd worden gesynchroniseerd om gegevensredundantie te garanderen. Dat betekent geen gegevensverlies.
Als u de waarde van required_synchronized_secondaries_to_commitwilt wijzigen, gebruikt u de volgende syntaxis:
Opmerking
Als u de waarde wijzigt, wordt de resource opnieuw opgestart, wat een korte storing betekent. De enige manier om dit te voorkomen, is door de resource zo in te stellen dat deze niet tijdelijk door het cluster wordt beheerd.
Red Hat Enterprise Linux (RHEL) en Ubuntu-
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
Opmerking
Vanaf SQL Server 2025 (17.x) wordt SUSE Linux Enterprise Server (SLES) niet ondersteund.
In dit voorbeeld is <AGResourceName> de naam van de resource die is geconfigureerd voor de beschikbaarheidsgroep, en is <value> 0, 1 of 2. Als u deze wilt terugzetten op de standaardinstelling van Pacemaker voor het beheren van de parameter, voert u dezelfde instructie uit zonder waarde.
Automatische failover van een AG is mogelijk wanneer aan de volgende voorwaarden wordt voldaan:
- De primaire en de secundaire replica zijn ingesteld op synchrone gegevensverplaatsing.
- De secundaire heeft een status van gesynchroniseerd (niet synchroniseren), wat betekent dat de twee zich op hetzelfde gegevenspunt bevinden.
- Het clustertype is ingesteld op Extern. Automatische failover is niet mogelijk met het clustertype None.
- De
sequence_numbersecundaire replica die de primaire replica wordt, heeft het hoogste reeksnummer, met andere woorden, de secundaire replicasequence_numberkomt overeen met de replica van de oorspronkelijke primaire replica.
Als aan deze voorwaarden wordt voldaan en de server die als host fungeert voor de primaire replica uitvalt, wordt het eigendom van de beschikbaarheidsgroep overgedragen aan een synchrone replica. Het gedrag voor synchrone replica's (waarvan er drie totalen kunnen zijn: één primaire en twee secundaire replica's) kunnen verder worden beheerd door required_synchronized_secondaries_to_commit. Dit werkt met AG's in zowel Windows als Linux, maar is anders geconfigureerd. In Linux wordt de waarde automatisch geconfigureerd door het cluster op de AG-resource zelf.
Alleen-configuratiereplica en quorum
Er is een configuratie-exclusieve replica geïntroduceerd om beperkingen in quorumbeheer met Pacemaker aan te pakken, vooral bij het isoleren van een defect knooppunt. Het hebben van slechts een configuratie met twee knooppunten werkt niet voor een AG. Voor een FCI kunnen de quorummechanismen van Pacemaker prima zijn omdat alle FCI-failover-arbitrage plaatsvindt op de clusterlaag. Voor een beschikbaarheidsgroep vindt arbitrage onder Linux plaats in SQL Server, waar alle metagegevens worden opgeslagen. Hier komt de alleen-voor-configuratie replica aan bod.
Zonder iets anders zou een derde knooppunt en ten minste één gesynchroniseerde replica vereist zijn. In de alleen-configuratiereplica wordt de AG-configuratie opgeslagen in de master database, net zoals in de andere replica's binnen de AG-configuratie. De replica die alleen voor configuratie is, bevat niet de gebruikersdatabases die deelnemen aan de beschikbaarheidsgroep (AG). De configuratiegegevens worden synchroon verzonden vanaf de primaire. Deze configuratiegegevens worden vervolgens gebruikt tijdens failovers, ongeacht of ze automatisch of handmatig zijn.
Om een beschikbaarheidsgroep quorum te laten behouden en automatische failovers met een clustertype Extern in te schakelen, moet deze:
- Drie synchrone replica's hebben (alleen SQL Server Enterprise Edition); of
- Heb twee replica's (de primaire en de secundaire) en een configuratiereplica.
Handmatige failovers kunnen optreden, ongeacht of u clustertypen Extern of Geen gebruikt voor AG-configuraties. Hoewel een replica met alleen-configuratie kan worden geconfigureerd met een beschikbaarheidsgroep met het 'clustertype' Geen, wordt dit niet aanbevolen, omdat het de implementatie ingewikkeld maakt. Voor deze configuraties moet u de required_synchronized_secondaries_to_commit handmatig aanpassen naar een waarde van ten minste 1, zodat er ten minste één gesynchroniseerde replica is.
Een alleen-configuratiereplica kan worden gehost op elke editie van SQL Server, met inbegrip van SQL Server Express. Dit minimaliseert de licentiekosten en zorgt ervoor dat deze werkt met AG's in de SQL Server Standard-editie. Dit betekent dat de derde vereiste server alleen moet voldoen aan de minimumspecificatie voor SQL Server, omdat deze geen gebruikerstransactieverkeer voor de AG ontvangt.
Wanneer een alleen-configuratiereplica wordt gebruikt, vertoont deze het volgende gedrag:
required_synchronized_secondaries_to_commitStandaard is ingesteld op 0. Dit kan desgewenst handmatig worden gewijzigd in 1.Als de primaire replica mislukt en
required_synchronized_secondaries_to_commit0 is, wordt de secundaire replica de nieuwe primaire en is deze beschikbaar voor zowel lezen als schrijven. Als de waarde 1 is, treedt automatische failover op, maar accepteert u geen nieuwe transacties totdat de andere replica online is.Als een secundaire replica mislukt en
required_synchronized_secondaries_to_commit0 is, accepteert de primaire replica nog steeds transacties, maar als de primaire mislukt op dit moment, is er geen beveiliging voor de gegevens of failover mogelijk (handmatig of automatisch), omdat er geen secundaire replica beschikbaar is.Als de configuratiereplica mislukt, werkt de AG normaal, maar is er geen automatische failover mogelijk.
Als zowel de synchrone secundaire replica als de configuratie-only replica uitvallen, kan de primaire geen transacties accepteren en is er geen mogelijkheid voor failover naar een andere replica.
Meerdere beschikbaarheidsgroepen
Er kan meer dan één AG worden gemaakt per Pacemaker-cluster of een set servers. De enige beperking is systeembronnen. Eigendom van AG wordt weergegeven door de primaire. Verschillende AG's kunnen eigendom zijn van verschillende knooppunten; ze hoeven niet allemaal op hetzelfde knooppunt te worden uitgevoerd.
Station en maplocatie voor databases
Net zoals bij AG's op Windows moeten het station en de mapstructuur voor de gebruikersdatabases die deelnemen aan een AG identiek zijn. Als de gebruikersdatabases zich bijvoorbeeld op Server A bevinden /var/opt/mssql/userdata , moet diezelfde map bestaan op Server B. De enige uitzondering hierop wordt vermeld in de sectie Interoperabiliteit met Windows-beschikbaarheidsgroepen en replica's.
De listener onder Linux
De listener is optionele functionaliteit voor een AG. Het biedt één toegangspunt voor alle verbindingen (lezen/schrijven naar de primaire replica en/of alleen-lezen naar secundaire replica's), zodat toepassingen en eindgebruikers niet hoeven te weten welke server de gegevens host. In een WSFC is dit de combinatie van een netwerknaamresource en een IP-resource, die vervolgens wordt geregistreerd in AD DS (indien nodig) en DNS. In combinatie met de AG resource zelf biedt het die abstractie. Zie Verbinding maken met een AlwaysOn-listener voor beschikbaarheidsgroepen voor meer informatie over een listener.
De listener onder Linux is anders geconfigureerd, maar de functionaliteit is hetzelfde. Er is geen concept van een netwerknaamresource in Pacemaker, noch is er een object gemaakt in AD DS; er is slechts een IP-adresresource gemaakt in Pacemaker die op een van de knooppunten kan worden uitgevoerd. Er moet een vermelding worden gemaakt die is gekoppeld aan de IP-resource voor de listener in DNS met een beschrijvende naam. De IP-resource voor de listener is alleen actief op de server die als host fungeert voor de primaire replica voor die beschikbaarheidsgroep.
Als Pacemaker wordt gebruikt en er een IP-adresresource wordt gemaakt die is gekoppeld aan de listener, is er een korte storing omdat het IP-adres stopt op de ene server en begint op de andere, ongeacht of het automatische of handmatige failover is. Hoewel dit abstractie biedt door de combinatie van één naam en IP-adres, wordt de storing niet gemaskeerd. Een toepassing moet in staat zijn om te gaan met het verbreken van de verbinding door functionaliteit te hebben die dit kan detecteren en opnieuw kan verbinden.
De combinatie van de DNS-naam en het IP-adres is echter nog steeds niet voldoende om alle functionaliteit te bieden die een listener op een WSFC biedt, zoals alleen-lezenroutering voor secundaire replica's. Wanneer u een AG configureert, moet er nog steeds een listener in SQL Server worden geconfigureerd. Dit is te zien in de wizard en de Transact-SQL-syntaxis. Er zijn twee manieren waarop dit kan worden geconfigureerd om hetzelfde te werken als in Windows:
- Voor een AG met een clustertype Extern moet het IP-adres dat is gekoppeld aan de listener die in SQL Server is gemaakt, het IP-adres zijn van de resource die in Pacemaker is gemaakt.
- Gebruik voor een AG die is gemaakt met het clustertype None het IP-adres dat is gekoppeld aan de primaire replica.
Het exemplaar dat is gekoppeld aan het opgegeven IP-adres wordt vervolgens de coördinator voor zaken als de alleen-lezen routeringsaanvragen van toepassingen.
Interoperabiliteit met beschikbaarheidsgroepen en replica's op basis van Windows
Een beschikbaarheidsgroep met een clustertype Extern of een cluster met Windows Server Failover Clustering (WSFC) kan zijn replicas niet op meerdere platforms laten draaien. Dit is waar of de AG SQL Server Standard-editie of SQL Server Enterprise-editie is. Dat betekent dat in een traditionele AG-configuratie met een onderliggend cluster één replica niet op een WSFC en de andere in Linux met Pacemaker kan zijn.
Een AG met een clustertype NONE kan de replica's over verschillende besturingssystemen heen hebben, zodat er zowel Linux- als Windows-replica's in dezelfde beschikbaarheidsgroep kunnen zijn. Hier ziet u een voorbeeld waarin de primaire replica is gebaseerd op Windows, terwijl de secundaire zich op een van de Linux-distributies bevindt.
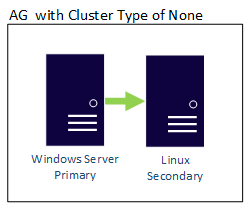
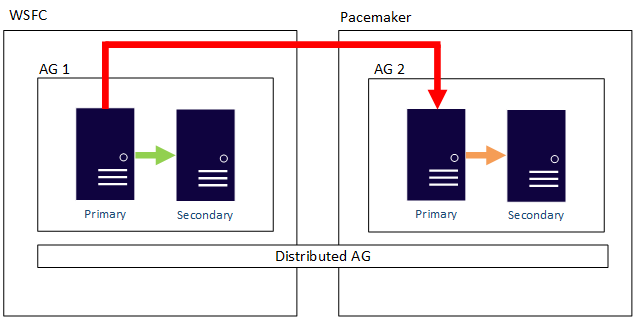
Een gedistribueerde beschikbaarheidsgroep kan ook besturingssysteemgrenzen overschrijden. De onderliggende beschikbaarheidsgroepen (AG's) zijn gebonden aan de regels voor hoe ze worden geconfigureerd, zoals een die is geconfigureerd met Extern, zodat het alleen Linux ondersteunt, maar de beschikbaarheidsgroep waaraan deze is gekoppeld, kan onderdeel zijn van een WSFC-opstelling. Bekijk het volgende voorbeeld:
Verwante inhoud
- SQL Server-beschikbaarheidsgroep configureren voor hoge beschikbaarheid in Linux
- Een SQL Server-beschikbaarheidsgroep configureren voor leesschaal in Linux
- Een Pacemaker-cluster configureren voor SQL Server-beschikbaarheidsgroepen
- Sql Server AlwaysOn-beschikbaarheidsgroep configureren in Windows en Linux (platformoverschrijdend)