Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server op Linux
SQL Server op Linux
In dit artikel worden de concepten uitgelegd die betrekking hebben op exemplaren van SQL Server-failoverclusters (FCI) in Linux.
Als u een SQL Server FCI in Linux wilt maken, raadpleegt u Een exemplaar van een failovercluster configureren - SQL Server op Linux (RHEL)
De clusteringlaag
In Red Hat Enterprise Linux (RHEL) is de clusteringlaag gebaseerd op de HA-invoegtoepassing Red Hat Enterprise Linux (RHEL).
Opmerking
Voor toegang tot de Red Hat HA-invoegtoepassing en documentatie is een abonnement vereist.
In SUSE Linux Enterprise Server (SLES) is de clusteringlaag gebaseerd op de SUSE Linux Enterprise High Availability Extension (HAE).
Zie SUSE Linux Enterprise High Availability Extension 15 voor meer informatie over clusterconfiguratie, resourceagentopties, beheer, best practices en aanbevelingen.
Zowel de RHEL HA-invoegtoepassing als de SUSE HAE zijn gebouwd op Pacemaker.
Zoals in het volgende diagram wordt weergegeven, wordt opslag weergegeven op twee servers. Clustering-onderdelen - Corosync en Pacemaker - communicatie en resourcebeheer coördineren. Een van de servers heeft de actieve verbinding met de opslagbronnen en de SQL Server. Wanneer Pacemaker een fout detecteert, zijn de clusteringonderdelen verantwoordelijk voor het verplaatsen van de resources naar het andere knooppunt.
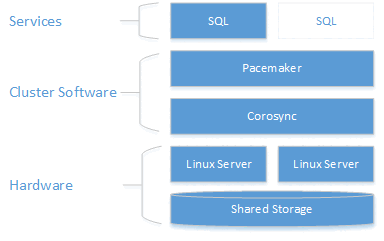
SQL Server-integratie met Pacemaker in Linux is niet zo gekoppeld aan WSFC in Windows. SQL Server heeft geen kennis over de aanwezigheid van het cluster. Alle indelingen zijn buiten en de service wordt beheerd als een zelfstandig exemplaar door Pacemaker. De naam van het virtuele netwerk is ook specifiek voor WSFC, die geen equivalent heeft in Pacemaker. Verwacht wordt dat @@SERVERNAME en sys.servers de naam van het knooppunt wordt geretourneerd, terwijl de DMV's sys.dm_os_cluster_nodes van het cluster geen sys.dm_os_cluster_properties records retourneren. Als u een verbindingsreeks wilt gebruiken die verwijst naar de naam van een tekenreeksserver en niet het IP-adres gebruikt, moet deze zich registreren op de DNS-server die wordt gebruikt voor het maken van de virtuele IP-resource (zoals wordt uitgelegd in de volgende secties) met de naam van de gekozen server.
Aantal exemplaren en knooppunten
Een belangrijk verschil met SQL Server op Linux is dat er slechts één installatie van SQL Server per Linux-server kan zijn. Deze installatie wordt een exemplaar genoemd. In tegenstelling tot Windows Server, dat maximaal 25 FCI's per Windows Server-failovercluster (WSFC) ondersteunt, heeft een op Linux gebaseerde FCI slechts één exemplaar. Dit ene exemplaar is ook een standaardexemplaren; er is geen concept van een benoemd exemplaar in Linux.
Een Pacemaker-cluster kan maximaal 16 knooppunten hebben wanneer Corosync erbij betrokken is, zodat één FCI maximaal 16 servers kan omvatten. Een FCI die is geïmplementeerd met Standard Edition van SQL Server ondersteunt maximaal twee knooppunten van een cluster, zelfs als het Pacemaker-cluster het maximum aantal 16 knooppunten heeft.
In een SQL Server FCI is het SQL Server-exemplaar actief op het ene knooppunt of op het andere.
IP-adres en -naam
In een Linux Pacemaker-cluster heeft elke SQL Server FCI een eigen unieke IP-adres en -naam nodig. Als de FCI-configuratie meerdere subnetten omvat, is één IP-adres per subnet vereist. De unieke naam en ip-adressen worden gebruikt voor toegang tot de FCI, zodat toepassingen en eindgebruikers niet hoeven te weten welke onderliggende server van het Pacemaker-cluster.
De naam van de FCI in DNS moet gelijk zijn aan de naam van de FCI-resource die wordt gemaakt in het Pacemaker-cluster. Zowel de naam als het IP-adres moeten worden geregistreerd in DNS.
Gedeelde opslag
Alle FCI's, ongeacht of ze zich op Linux of Windows Server bevinden, vereisen een vorm van gedeelde opslag. Deze opslag wordt gepresenteerd aan alle servers die mogelijk de FCI kunnen hosten, maar slechts één server kan de opslag voor de FCI op elk gewenst moment gebruiken. De beschikbare opties voor gedeelde opslag onder Linux zijn:
- iSCSI
- Netwerkbestandssysteem (NFS)
- Server Message Block (SMB)
Onder Windows Server zijn er iets andere opties. Een optie die momenteel niet wordt ondersteund voor op Linux gebaseerde FCI's, is de mogelijkheid om een schijf te gebruiken die lokaal is voor het knooppunt tempdb, wat de tijdelijke werkruimte van SQL Server is.
In een configuratie die meerdere locaties omvat, moet wat in het ene datacenter wordt opgeslagen, worden gesynchroniseerd met de andere. In het geval van een failover kan de FCI online komen en is de opslag hetzelfde. Hiervoor is een externe methode vereist voor opslagreplicatie, ongeacht of deze wordt uitgevoerd via de onderliggende opslaghardware of een softwarehulpprogramma.
Opmerking
Voor SQL Server moeten op Linux gebaseerde implementaties, waarbij schijven direct aan een server worden gepresenteerd, worden geformatteerd met XFS of ext4. Andere bestandssystemen worden momenteel niet ondersteund. Alle wijzigingen worden hier doorgevoerd.
Het proces voor het presenteren van gedeelde opslag is hetzelfde voor de verschillende ondersteunde methoden:
- De gedeelde opslag configureren
- Koppel de opslag als een map aan de servers die fungeren als knooppunten van het Pacemaker-cluster voor de FCI
- Verplaats indien nodig de SQL Server-systeemdatabases naar gedeelde opslag
- Testen of SQL Server werkt vanaf elke server die is verbonden met de gedeelde opslag
Een belangrijk verschil met SQL Server op Linux is dat hoewel u de standaardgebruikersgegevens en de locatie van het logboekbestand kunt configureren, de systeemdatabases altijd moeten bestaan op /var/opt/mssql/data. Op Windows Server hebt u de mogelijkheid om de systeemdatabases te verplaatsen, waaronder tempdb. Dit feit speelt in hoe gedeelde opslag wordt geconfigureerd voor een FCI.
De standaardpaden voor niet-systeemdatabases kunnen worden gewijzigd met behulp van het mssql-conf hulpprogramma. Voor informatie over het wijzigen van de standaardinstellingen, wijzigt u de standaardgegevens of de locatie van de logboekmap. U kunt ook SQL Server-gegevens en -transacties opslaan op andere locaties, zolang ze de juiste beveiliging hebben, zelfs als het geen standaardlocatie is; de locatie moet worden vermeld.