Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server 2016 (13.x) SQL Server 2017 (14.x)
SQL Server 2016 (13.x) SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x) ![]() op Linux
op Linux
Python-integratie is beschikbaar in SQL Server 2017 en hoger wanneer u de Python-optie opneemt in een installatie van Machine Learning Services (In-Database).
Opmerking
Dit artikel is momenteel alleen van toepassing op SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) en SQL Server 2019 (15.x) voor Linux.
Als u Python-oplossingen voor SQL Server wilt ontwikkelen en implementeren, installeert u de hervoscalepy - en andere Python-bibliotheken van Microsoft op uw ontwikkelwerkstation. De revoscalepy-bibliotheek, die zich ook op het externe SQL Server-exemplaar bevindt, coördineert rekenaanvragen tussen beide systemen.
In dit artikel leert u hoe u een Python-ontwikkelwerkstation configureert, zodat u kunt communiceren met een externe SQL Server die is ingeschakeld voor machine learning en Python-integratie. Nadat u de stappen in dit artikel hebt voltooid, hebt u dezelfde Python-bibliotheken als die in SQL Server. U weet ook hoe u berekeningen van een lokale Python-sessie naar een externe Python-sessie op SQL Server pusht.
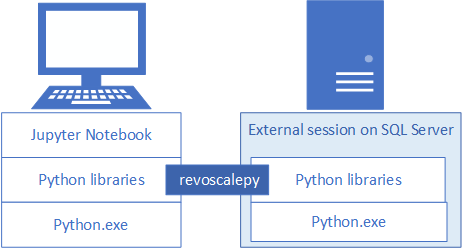
Als u de installatie wilt valideren, kunt u ingebouwde Jupyter Notebooks gebruiken zoals beschreven in dit artikel, of de bibliotheken koppelen aan PyCharm of een andere IDE die u normaal gesproken gebruikt.
Aanbeveling
Zie R en Python op afstand uitvoeren in SQL Server vanuit Jupyter Notebooks voor een videodemonstratie van deze oefeningen.
Veelgebruikte hulpprogramma's
Of u nu een Python-ontwikkelaar bent die nieuw is voor SQL of een SQL-ontwikkelaar die nieuw is in Python en in-database-analyses, u hebt zowel een Python-ontwikkelhulpprogramma als een T-SQL-queryeditor nodig, zoals SQL Server Management Studio (SSMS) om alle mogelijkheden van in-databaseanalyses uit te oefenen.
Voor Python-ontwikkeling kunt u Jupyter Notebooks gebruiken, die zijn gebundeld in de Anaconda-distributie die door SQL Server is geïnstalleerd. In dit artikel wordt uitgelegd hoe u Jupyter Notebooks start, zodat u Python-code lokaal en extern kunt uitvoeren op SQL Server.
SSMS is een afzonderlijke download, handig voor het maken en uitvoeren van opgeslagen procedures op SQL Server, met inbegrip van procedures met Python-code. Bijna elke Python-code die u in Jupyter Notebooks schrijft, kan worden ingesloten in een opgeslagen procedure. U kunt andere quickstarts doorlopen voor meer informatie over SSMS en ingesloten Python.
1 - Python-pakketten installeren
Lokale werkstations moeten dezelfde Python-pakketversies hebben als die op SQL Server, waaronder de basis-Anaconda 4.2.0 met Python 3.5.2-distributie en Microsoft-specifieke pakketten.
Een installatiescript voegt drie Microsoft-specifieke bibliotheken toe aan de Python-client. Het script installeert:
- revoscalepy wordt gebruikt om gegevensbronobjecten en de rekencontext te definiëren.
- microsoftml biedt machine learning-algoritmen.
- azureml is van toepassing op operationele taken die zijn gekoppeld aan een zelfstandige servercontext en kan beperkt worden gebruikt voor in-databaseanalyses.
Download een installatiescript. Op de juiste volgende GitHub-pagina, selecteer Download raw-bestand.
Install-PyForMLS.ps1 installeert versie 9.2.1 van de Microsoft Python-pakketten. Deze versie komt overeen met een standaard SQL Server-exemplaar.
Install-PyForMLS.ps1 installeert versie 9.3 van de Microsoft Python-pakketten.
Open een PowerShell-venster met verhoogde beheerdersmachtigingen (klik met de rechtermuisknop op Uitvoeren als administrator).
Ga naar de map waarin u het installatieprogramma hebt gedownload en voer het script uit. Voeg het
-InstallFolderopdrachtregelargument toe om een maplocatie voor de bibliotheken op te geven. Voorbeeld:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Als u de installatiemap weglaat, is de standaardwaarde %ProgramFiles%\Microsoft\PyForMLS.
Het duurt even voordat de installatie is voltooid. U kunt de voortgang bewaken in het PowerShell-venster. Wanneer de installatie is voltooid, hebt u een volledige set pakketten.
Aanbeveling
We raden de veelgestelde vragen over Python voor Windows aan voor algemene informatie over het uitvoeren van Python-programma's in Windows.
2 - Uitvoerbare bestanden zoeken
Vermeld nog steeds in PowerShell de inhoud van de installatiemap om te bevestigen dat Python.exe, scripts en andere pakketten zijn geïnstalleerd.
Voer
cd \in om naar de rootmap te gaan, en voer vervolgens het pad in dat u in de vorige stap voor-InstallFolderhebt opgegeven. Als u deze parameter tijdens de installatie weglaat, is de standaardwaardecd %ProgramFiles%\Microsoft\PyForMLS.Voer in
dir *.exeom de uitvoerbare bestanden weer te geven. U ziet python.exe, pythonw.exeen uninstall-anaconda.exe.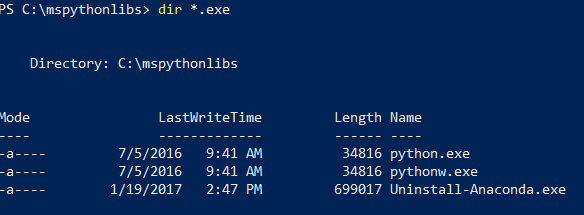
Vergeet niet om op systemen met meerdere versies van Python deze specifieke Python.exe te gebruiken als u revoscalepy en andere Microsoft-pakketten wilt laden.
Opmerking
Het installatiescript wijzigt de omgevingsvariabele PATH niet op uw computer, wat betekent dat de nieuwe Python-interpreter en modules die u zojuist hebt geïnstalleerd, niet automatisch beschikbaar zijn voor andere hulpprogramma's die u mogelijk hebt. Zie Een IDE installeren voor hulp bij het koppelen van de Python-interpreter en -bibliotheken aan hulpprogramma's.
3 - Jupyter Notebooks openen
Anaconda bevat Jupyter Notebooks. Als volgende stap maakt u een notebook en voert u python-code uit met de bibliotheken die u zojuist hebt geïnstalleerd.
Open Jupyter Notebooks vanuit de
%ProgramFiles%\Microsoft\PyForMLSmap bij de PowerShell-prompt, nog steeds in de map Scripts:.\Scripts\jupyter-notebookEr moet een notitieblok worden geopend in uw standaardbrowser op
https://localhost:8889/tree.Een andere manier om te starten is dubbelklikken jupyter-notebook.exe.
Selecteer Nieuw en selecteer vervolgens Python 3.
Voer de opdracht in
import revoscalepyen voer deze uit om een van de Microsoft-specifieke bibliotheken te laden.Voer
print(revoscalepy.__version__)in en voer het uit om de versiegegevens terug te geven. U zou 9.2.1 of 9.3.0 moeten zien. U kunt een van deze versies gebruiken met revoscalepy op de server.Voer een complexere reeks instructies in. In dit voorbeeld worden samenvattingsstatistieken gegenereerd met behulp van rx_summary via een lokale gegevensset. Andere functies krijgen de locatie van de voorbeeldgegevens en maken een gegevensbronobject voor een lokaal XDF-bestand.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
In de volgende schermopname ziet u de invoer en een deel van de uitvoer, ingekort voor beknoptheid.

4 - SQL-machtigingen ophalen
Als u verbinding wilt maken met een exemplaar van SQL Server om scripts uit te voeren en gegevens te uploaden, moet u een geldige aanmelding hebben op de databaseserver. U kunt een SQL-aanmelding of geïntegreerde Windows-verificatie gebruiken. Over het algemeen wordt u aangeraden geïntegreerde Windows-verificatie te gebruiken, maar het gebruik van de SQL-aanmelding is voor sommige scenario's eenvoudiger, met name wanneer uw script verbindingsreeksen naar externe gegevens bevat.
Ten minste moet het account dat wordt gebruikt om code uit te voeren, gemachtigd zijn om te lezen uit de databases waarmee u werkt, plus de speciale machtiging EXECUTE ANY EXTERNAL SCRIPT. De meeste ontwikkelaars hebben ook machtigingen nodig om opgeslagen procedures te maken en gegevens naar tabellen te schrijven die trainingsgegevens of scoregegevens bevatten.
Vraag de databasebeheerder om de volgende machtigingen voor uw account te configureren in de database waarin u Python gebruikt:
- VOER EEN EXTERN SCRIPT UIT om Python uit te voeren op de server.
- db_datareader bevoegdheden voor het uitvoeren van de query's die worden gebruikt voor het trainen van het model.
- db_datawriter om trainingsdata of scoringgegevens te schrijven.
- db_owner objecten maken, zoals opgeslagen procedures, tabellen, functies. U hebt ook db_owner nodig om voorbeelddatabases te maken en te testen.
Zorg ervoor dat de pakketten die vereist zijn voor uw code geïnstalleerd zijn bij de instantie van SQL Server, indien deze niet standaard geïnstalleerd zijn, door met de databasebeheerder afspraken te maken. SQL Server is een beveiligde omgeving en er zijn beperkingen voor waar pakketten kunnen worden geïnstalleerd. Ad-hocinstallatie van pakketten als onderdeel van uw code wordt niet aanbevolen, zelfs niet als u rechten hebt. Houd ook altijd zorgvuldig rekening met de gevolgen voor de beveiliging voordat u nieuwe pakketten in de serverbibliotheek installeert.
5 - Testgegevens maken
Als u gemachtigd bent om een database te maken op de externe server, kunt u de volgende code uitvoeren om de Iris-demodatabase te maken die wordt gebruikt voor de resterende stappen in dit artikel.
5-1 - De irissql-database op afstand maken
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5-2 - Iris-voorbeeld importeren uit SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Revoscalepy-API's gebruiken om een tabel te maken en de Iris-gegevens te laden
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - Externe verbinding testen
Voordat u deze volgende stap uitvoert, moet u ervoor zorgen dat u machtigingen hebt voor het SQL Server-exemplaar en een verbindingsreeks voor de Iris-voorbeelddatabase. Als de database niet bestaat en u over voldoende machtigingen beschikt, kunt u een database maken met behulp van deze inline-instructies.
Vervang de verbindingsreeks door geldige waarden. De voorbeeldcode gebruikt "Server=localhost;Database=irissql;Trusted_Connection=Yes;", maar uw code moet een externe server opgeven, mogelijk met een instantienaam en een authenticatieoptie die is toegewezen aan een databaseaanmelding.
6-1 Een functie definiëren
De volgende code definieert een functie die u in een latere stap naar SQL Server verzendt. Wanneer deze wordt uitgevoerd, worden gegevens en bibliotheken (revoscalepy, pandas, matplotlib) op de externe server gebruikt om spreidingsdiagrammen van de irisgegevensset te maken. Deze retourneert de bytestream van de .png terug naar Jupyter Notebooks om weer te geven in de browser.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 De functie verzenden naar SQL Server
In dit voorbeeld maakt u de externe rekencontext en verzendt u vervolgens de uitvoering van de functie naar SQL Server met rx_exec. De functie rx_exec is handig omdat deze een rekencontext accepteert als argument. Elke functie die u op afstand wilt uitvoeren, moet een argument voor de berekeningscontext hebben. Sommige functies, zoals rx_lin_mod ondersteunen dit argument rechtstreeks. Voor bewerkingen die dat niet doen, kunt u rx_exec gebruiken om uw code in een externe rekencontext te leveren.
In dit voorbeeld moesten er geen onbewerkte gegevens worden overgebracht van SQL Server naar de Jupyter Notebook. Alle berekeningen worden uitgevoerd in de Iris-database en alleen het afbeeldingsbestand wordt geretourneerd naar de client.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
In de volgende screenshot ziet u de invoer en de uitvoer van het spreidingsdiagram.

7 - Python starten vanuit hulpprogramma's
Omdat ontwikkelaars vaak met meerdere versies van Python werken, wordt Python niet toegevoegd aan uw PATH. Als u het uitvoerbare Python-bestand en de bibliotheken wilt gebruiken die door setup zijn geïnstalleerd, koppelt u uw IDE aan Python.exe op het pad dat ook revoscalepy en microsoftml biedt.
Opdrachtregel
Wanneer u Python.exe uitvoert vanaf %ProgramFiles%\Microsoft\PyForMLS (of welke locatie u hebt opgegeven voor de installatie van de Python-clientbibliotheek), hebt u toegang tot de volledige Anaconda-distributie plus de Microsoft Python-modules, revoscalepy en microsoftml.
- Ga naar
%ProgramFiles%\Microsoft\PyForMLSen voer Python.exeuit. - Open interactieve hulp:
help(). - Typ de naam van een module bij de helpprompt:
help> revoscalepy. Help retourneert de naam, pakketinhoud, versie en bestandslocatie. - Retourneert versie- en pakketgegevens bij de helpprompt> :
revoscalepy. Druk een paar keer op Enter om hulp af te sluiten. - Een module importeren:
import revoscalepy.
Jupyter notitieboekjes
In dit artikel worden ingebouwde Jupyter Notebooks gebruikt om functieaanroepen in revoscalepy te demonstreren. Als u geen toegang hebt tot dit hulpprogramma, ziet u in de volgende schermopname hoe de onderdelen bij elkaar passen en waarom het allemaal 'gewoon werkt'.
De bovenliggende map %ProgramFiles%\Microsoft\PyForMLS bevat Anaconda plus de Microsoft-pakketten. Jupyter Notebooks is opgenomen in Anaconda, onder de map Scripts en de uitvoerbare Python-bestanden worden automatisch geregistreerd bij Jupyter Notebooks. Pakketten die worden gevonden onder sitepakketten, kunnen worden geïmporteerd in een notebook, waaronder de drie Microsoft-pakketten die worden gebruikt voor data science en machine learning.
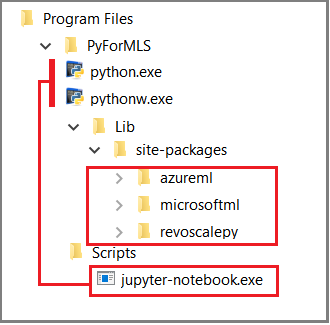
Als u een andere IDE gebruikt, moet u de uitvoerbare Python-bestanden en functiebibliotheken koppelen aan uw hulpprogramma. De volgende secties bevatten instructies voor veelgebruikte hulpprogramma's.
Visual Studio
Als u Python in Visual Studio hebt, gebruikt u de volgende configuratieopties om een Python-omgeving te maken die de Microsoft Python-pakketten bevat.
| Configuratie-instelling | waarde |
|---|---|
| Voorvoegselpad | %ProgramFiles%\Microsoft\PyForMLS |
| Interpreterpad | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Interpreter met vensters | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Zie Python-omgevingen beheren in Visual Studio voor hulp bij het configureren van een Python-omgeving.
PyCharm
Stel in PyCharm de interpreter in op het uitvoerbare Python-bestand dat is geïnstalleerd.
Selecteer Lokaal toevoegen in een nieuw project in Instellingen.
Voer
%ProgramFiles%\Microsoft\PyForMLS\in.
U kunt nu de modules revoscalepy, microsoftml of azureml importeren. U kunt ook Tools>Python Console kiezen om een interactief venster te openen.