Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Elke SQL Server-database heeft minimaal twee besturingssysteembestanden: een gegevensbestand en een logboekbestand. Gegevensbestanden bevatten gegevens en objecten, zoals tabellen, indexen, opgeslagen procedures en weergaven. Logboekbestanden bevatten de informatie die nodig is om alle transacties in de database te herstellen. Gegevensbestanden kunnen worden gegroepeerd in bestandsgroepen voor toewijzings- en beheerdoeleinden.
Databasebestanden
SQL Server-databases hebben drie typen bestanden, zoals wordt weergegeven in de volgende tabel.
| Bestand | Description |
|---|---|
| primaire | Bevat opstartgegevens voor de database en verwijst naar de andere bestanden in de database. Elke database heeft één primair gegevensbestand. De aanbevolen bestandsnaamextensie voor primaire gegevensbestanden is .mdf. |
| Secundaire | Optionele door de gebruiker gedefinieerde gegevensbestanden. Gegevens kunnen worden verspreid over meerdere schijven door elk bestand op een ander schijfstation te plaatsen. De aanbevolen bestandsnaamextensie voor secundaire gegevensbestanden is .ndf. |
| Transactielogboek | Het logboek bevat informatie die wordt gebruikt om de database te herstellen. Er moet ten minste één logboekbestand voor elke database zijn. De aanbevolen bestandsnaamextensie voor transactielogboeken is .ldf. |
Een eenvoudige database met de naam Sales heeft bijvoorbeeld één primair bestand met alle gegevens en objecten en een logboekbestand dat de transactielogboekgegevens bevat. Een complexere database met de naam Orders kan worden gemaakt met één primair bestand en vijf secundaire bestanden. De gegevens en objecten in de database verspreid over alle zes bestanden en de vier logboekbestanden bevatten de transactielogboekgegevens.
Standaard worden de gegevens- en transactielogboeken op hetzelfde station en pad geplaatst om systemen met één schijf te verwerken. Deze keuze is mogelijk niet optimaal voor productieomgevingen. U wordt aangeraden gegevens en logboekbestanden op afzonderlijke schijven te plaatsen.
Namen van logische en fysieke bestanden
SQL Server-bestanden hebben twee bestandstypen:
logical_file_name: De naam die wordt gebruikt om te verwijzen naar het fysieke bestand in alle Transact-SQL instructies. De naam van het logische bestand moet voldoen aan de regels voor SQL Server-id's en moet uniek zijn tussen namen van logische bestanden in de database.os_file_name: De naam van het fysieke bestand, inclusief het mappad. Deze moet de regels voor de bestandsnamen van het besturingssysteem volgen.
Zie NAME voor meer informatie over de FILENAME opties en argumenten.
Wanneer meerdere exemplaren van SQL Server worden uitgevoerd op één computer, ontvangt elk exemplaar een andere standaardmap voor het opslaan van de bestanden voor de databases die in het exemplaar zijn gemaakt. Zie Bestandslocaties voor standaard- en benoemde exemplaren van SQL Server voor meer informatie.
Ondersteuning voor bestandssysteem
SQL Server-gegevens en logboekbestanden kunnen worden geplaatst op FAT- of NTFS-bestandssystemen. Op Windows-systemen raadt Microsoft het gebruik van het NTFS-bestandssysteem aan omdat de beveiligingsaspecten van NTFS.
Lees-/schrijfgegevensbestandgroepen en logboekbestanden worden niet ondersteund op een gecomprimeerd NTFS-bestandssysteem. Alleen alleen-lezen databases en alleen-lezen secundaire bestandsgroepen mogen worden geplaatst op een gecomprimeerd NTFS-bestandssysteem. Gebruik voor ruimtebesparende gegevenscompressie in plaats van bestandssysteemcompressie.
Pagina's van gegevensbestanden
Pagina's in een SQL Server-gegevensbestand worden opeenvolgend genummerd, beginnend met nul (0) voor de eerste pagina in het bestand. Elk bestand in een database heeft een uniek bestands-id-nummer. Als u een pagina in een database uniek wilt identificeren, zijn zowel de bestands-id als het paginanummer vereist. In het volgende voorbeeld ziet u de paginanummers in een database met een primair gegevensbestand van 4 MB en een secundair gegevensbestand van 1 MB.
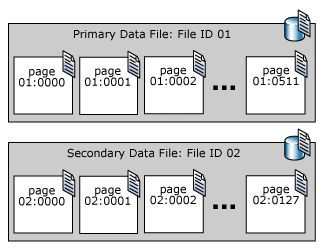
Een bestandskoppagina is de eerste pagina met informatie over de kenmerken van het bestand. Verschillende andere pagina's aan het begin van het bestand bevatten ook systeemgegevens, zoals toewijzingskaarten. Een van de systeempagina's die zijn opgeslagen in zowel het primaire gegevensbestand als het eerste logboekbestand, is een databasestartpagina met informatie over de kenmerken van de database.
Bestandsgrootte
SQL Server-bestanden kunnen automatisch groeien vanaf de oorspronkelijk opgegeven grootte. Wanneer u een bestand definieert, kunt u een specifieke groeiverhoging opgeven. Telkens wanneer het bestand wordt gevuld, wordt de grootte ervan verhoogd door de toename van de groei. Als er meerdere bestanden in een bestandsgroep bestaan, worden ze pas automatisch uitgebreid als alle bestanden vol zijn.
Zie de architectuurhandleiding Pagina's en gebieden voor meer informatie over pagina's en paginatypen.
Elk bestand kan ook een maximale grootte hebben opgegeven. Als er geen maximale grootte is opgegeven, kan het bestand blijven groeien totdat alle beschikbare ruimte op de schijf is gebruikt. Deze functie is vooral handig wanneer SQL Server wordt gebruikt als een database die is ingesloten in een toepassing waar de gebruiker geen handige toegang heeft tot een systeembeheerder. De gebruiker kan de bestanden automatisch laten groeien om de administratieve belasting van het bewaken van vrije ruimte in de database te verminderen en handmatig extra ruimte toe te wijzen.
Zie De grootte van het transactielogboekbestand beheren voor meer informatie over het beheer van transactielogboekbestanden.
Momentopnamebestanden van database
De vorm van een bestand dat wordt gebruikt door een momentopname van een database om de kopieer-op-schrijfgegevens op te slaan, is afhankelijk van of de momentopname wordt gemaakt door een gebruiker of intern wordt gebruikt:
Een momentopname van een database die door een gebruiker wordt gemaakt, slaat de gegevens op in een of meer sparse-bestanden. Sparse-bestandstechnologie is een functie van het NTFS-bestandssysteem. In het begin bevat een sparse-bestand geen gebruikersgegevens en schijfruimte voor gebruikersgegevens is niet toegewezen aan het sparse-bestand. Zie De grootte van het Sparse-bestand van een momentopname van een database weergeven voor algemene informatie over het gebruik van sparse-bestanden in momentopnamen van databases en hoe databasemomentopnamen groeien.
Databasesnapshots worden intern gebruikt door bepaalde DBCC-commando's. Deze opdrachten omvatten
DBCC CHECKDB,DBCC CHECKTABLE, enDBCC CHECKALLOCDBCC CHECKFILEGROUP. Een momentopname van een interne database maakt gebruik van sparse alternatieve gegevensstromen van de oorspronkelijke databasebestanden. Net als sparse-bestanden zijn alternatieve gegevensstromen een functie van het NTFS-bestandssysteem. Met het gebruik van sparse alternatieve gegevensstromen kunnen meerdere gegevenstoewijzingen worden gekoppeld aan één bestand of map zonder dat dit van invloed is op de bestandsgrootte of volumestatistieken.
Filegroups
- De primaire bestandsgroep bevat het primaire gegevensbestand en eventuele secundaire bestanden die niet in andere bestandsgroepen worden geplaatst.
- Door de gebruiker gedefinieerde bestandsgroepen kunnen worden gemaakt om gegevensbestanden te groeperen voor administratieve, gegevenstoewijzing en plaatsingsdoeleinden.
Bijvoorbeeld: Data1.ndf, Data2.ndfen Data3.ndf, kunnen worden gemaakt op respectievelijk drie schijfstations en worden toegewezen aan de bestandsgroep fgroup1. Een tabel kan vervolgens specifiek worden gemaakt voor de bestandsgroep fgroup1. Query's voor gegevens uit de tabel worden verspreid over de drie schijven; de prestaties worden verbeterd. Dezelfde prestatieverbetering kan worden bereikt met behulp van één bestand dat is gemaakt op een RAID-stripeset (redundante matrix met onafhankelijke schijven). Met bestanden en bestandsgroepen kunt u echter eenvoudig nieuwe bestanden toevoegen aan nieuwe schijven.
Alle gegevensbestanden worden opgeslagen in de bestandsgroepen die worden vermeld in de volgende tabel.
| Filegroup | Description |
|---|---|
| primaire | De bestandsgroep die het primaire bestand bevat. Alle systeemtabellen maken deel uit van de primaire bestandsgroep. |
| Geoptimaliseerde gegevens voor geheugen | Een voor geheugen geoptimaliseerde bestandsgroep is gebaseerd op FILESTREAM-bestandsgroep |
| Filestream | De ongestructureerde gegevens die zijn opgeslagen in bestandssysteemmappen. |
| Door de gebruiker gedefinieerd | Elke bestandsgroep die door de gebruiker wordt gemaakt wanneer de gebruiker de database voor het eerst maakt of later wijzigt. |
Standaardbestandsgroep (primaire)
Wanneer objecten worden gemaakt in de database zonder op te geven tot welke bestandsgroep ze behoren, worden ze toegewezen aan de standaardbestandsgroep. Op elk gewenst moment wordt precies één bestandsgroep aangewezen als de standaardbestandsgroep. De bestanden in de standaardbestandsgroep moeten groot genoeg zijn om nieuwe objecten op te slaan die niet zijn toegewezen aan andere bestandsgroepen.
De PRIMARY bestandsgroep is de standaardbestandsgroep, tenzij deze wordt gewijzigd met behulp van de ALTER DATABASE instructie. Toewijzing voor de systeemobjecten en tabellen blijft binnen de PRIMARY bestandsgroep, niet de nieuwe standaardbestandsgroep.
Voor geheugen geoptimaliseerde gegevensbestandsgroep
Zie de voor geheugen geoptimaliseerde bestandsgroep voor meer informatie over bestandsgroepen die zijn geoptimaliseerd voor geheugen.
FILESTREAM-bestandsgroep
Zie FILESTREAM en Een FILESTREAM-Enabled Database maken voor meer informatie over FILESTREAM-bestandsgroepen.
Voorbeeld van bestands- en bestandsgroep
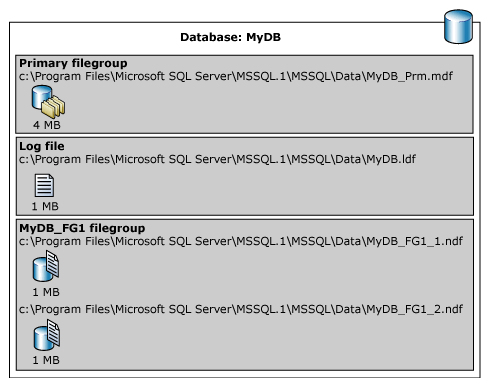
In het volgende voorbeeld wordt een database gemaakt op een exemplaar van SQL Server. De database heeft een primair gegevensbestand, een door de gebruiker gedefinieerde bestandsgroep en een logboekbestand. Het primaire gegevensbestand bevindt zich in de primaire bestandsgroep en de door de gebruiker gedefinieerde bestandsgroep heeft twee secundaire gegevensbestanden. Een ALTER DATABASE instructie maakt de door de gebruiker gedefinieerde bestandsgroep de standaardinstelling. Er wordt vervolgens een tabel gemaakt waarin de door de gebruiker gedefinieerde bestandsgroep wordt opgegeven. (In dit voorbeeld wordt een algemeen pad C:\Program Files\Microsoft SQL Server\MSSQL.1 gebruikt om te voorkomen dat een versie van SQL Server wordt opgegeven.)
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
In de volgende afbeelding ziet u een overzicht van de resultaten van het vorige voorbeeld (met uitzondering van de FILESTREAM-gegevens).
Strategie voor opvulling van bestands- en bestandsgroepen
Bestandsgroepen gebruiken een proportionele opvullingsstrategie voor alle bestanden binnen elke bestandsgroep. Als gegevens naar de bestandsgroep worden geschreven, schrijft de SQL Server Database Engine een bedrag dat evenredig is met de vrije ruimte in het bestand in elk bestand in de bestandsgroep, in plaats van alle gegevens naar het eerste bestand te schrijven totdat deze vol is. Daarna schrijft het naar het volgende bestand. Als het bestand f1 bijvoorbeeld 100 MB vrij heeft en het bestand f2 200 MB vrij heeft, krijgt één extent van bestand f1, twee extents van bestand f2, enzovoort. Op deze manier raken beide bestanden tegelijkertijd vol, en wordt eenvoudige verdeling bereikt.
Een bestandsgroep bestaat bijvoorbeeld uit drie bestanden, die allemaal zijn ingesteld om automatisch te groeien. Wanneer de ruimte in alle bestanden in de bestandsgroep is uitgeput, wordt alleen het eerste bestand uitgevouwen. Wanneer het eerste bestand vol is en er geen gegevens meer naar de bestandsgroep kunnen worden geschreven, wordt het tweede bestand uitgevouwen. Wanneer het tweede bestand vol is en er geen gegevens meer naar de bestandsgroep kunnen worden geschreven, wordt het derde bestand uitgevouwen. Als het derde bestand vol raakt en er geen gegevens meer naar de bestandsgroep kunnen worden geschreven, wordt het eerste bestand opnieuw uitgevouwen, enzovoort.
Regels voor het ontwerpen van bestanden en bestandsgroepen
De volgende regels hebben betrekking op bestanden en bestandsgroepen:
Een bestand of bestandsgroep kan niet worden gebruikt door meer dan één database. Een voorbeeld is dat bestanden
sales.mdfensales.ndf, die gegevens en objecten uit de verkoopdatabase bevatten, niet door een andere database kunnen worden gebruikt.Een bestand kan slechts lid zijn van slechts één bestandsgroep.
Transactielogboekbestanden maken nooit deel uit van bestandsgroepen.
Aanbevelingen
Aanbevelingen bij het werken met bestanden en bestandsgroepen:
De meeste databases werken goed met één gegevensbestand en één transactielogboekbestand.
Als u meerdere gegevensbestanden gebruikt, maakt u een tweede bestandsgroep voor het extra bestand en maakt u die bestandsgroep de standaardbestandsgroep. Op deze manier bevat het primaire bestand alleen systeemtabellen en -objecten.
Als u de prestaties wilt maximaliseren, maakt u bestanden of bestandsgroepen op verschillende beschikbare schijven, indien mogelijk. Plaats objecten die sterk concurreren voor ruimte in verschillende bestandsgroepen.
Gebruik bestandsgroepen om plaatsing van objecten op specifieke fysieke schijven mogelijk te maken.
Plaats verschillende tabellen die worden gebruikt in dezelfde joinquery's in verschillende bestandsgroepen. Met deze stap worden de prestaties verbeterd vanwege I/O van parallelle schijven die zoeken naar gekoppelde gegevens.
Plaats intensief geopende tabellen en de niet-geclusterde indexen die deel uitmaken van die tabellen in verschillende bestandsgroepen. Het gebruik van verschillende bestandsgroepen verbetert de prestaties, vanwege parallelle I/O als de bestanden zich op verschillende fysieke schijven bevinden.
Plaats de transactielogboekbestanden niet op dezelfde fysieke schijf met de andere bestanden en bestandsgroepen.
Als u een volume of partitie wilt uitbreiden waarop databasebestanden zich bevinden met behulp van hulpprogramma's zoals diskpart, moet u eerst een back-up maken van alle systeem- en gebruikersdatabases en sql Server-services stoppen. Zodra schijfvolumes zijn uitgebreid, moet u ook overwegen de DBCC CHECKDB-opdracht uit te voeren om de fysieke integriteit van alle databases op het volume te garanderen.
Zie De grootte van het transactielogboekbestandsbestand beheren voor meer informatie over aanbevelingen voor het beheer van transactielogboeken.
Verwante inhoud
- Een DATABASE maken
- ALTER DATABASE (Transact-SQL) Bestands- en bestandsgroepopties
- Database ontkoppelen en koppelen (SQL Server)
- architectuur en beheerhandleiding voor SQL Server-transactielogboeken
- Architectuurhandleiding voor pagina's en extenties
- De grootte van het transactielogboekbestand beheren