Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server 2016 (13.x) en latere versies
SQL Server 2016 (13.x) en latere versies ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Met gegevensvirtualisatie kunt u Transact-SQL (T-SQL)-query's uitvoeren op externe gegevens zonder deze in uw database te laden. PolyBase is de database-enginefunctie waarmee gegevensvirtualisatie wordt geïmplementeerd in SQL Server en Azure SQL. U definieert een externe gegevensbron, optionele bestandsindeling en externe tabel en voert vervolgens een query uit op de externe tabel met SELECT net als elke andere tabel.
Deze handleiding helpt u bij het volgende:
- Begrijpen welke PolyBase functies biedt voor uw SQL-platform en versieondersteuning.
- Kies tussen
OPENROWSET, externe tabellen enBULK INSERTvoor het opvragen of opnemen van gegevens. - Volg stapsgewijze koppelingen voor veelvoorkomende scenario's.
- Bekijk de prestaties, probleemoplossing en aanbevolen procedures voor productieworkloads.
Veelvoorkomende gebruiksvoorbeelden
In de volgende tabel worden mogelijke gebruiksscenario's beschreven.
| Scenario | Gebruik |
|---|---|
| Ad-hoc bestandsverkenning | OPENROWSET(BULK ...) |
| Herbruikbare bestandsquery's voor BI/rapportage | Externe tabellen op basis van bestanden |
| Query's op meerdere databases (SQL Server, Oracle, Teradata, MongoDB, ODBC) | PolyBase connectors met externe tabellen |
| Queryresultaten exporteren naar bestanden |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Bulk verzenden naar tabellen |
BULK INSERT of OPENROWSET(BULK ...) met INSERT ... SELECT |
Welke functies zijn beschikbaar waar?
In de volgende tabel ziet u welke kernfuncties voor PolyBase en gegevensvirtualisatie beschikbaar zijn op elk SQL-platform. Gebruik deze tabel om te bepalen wat u op uw platform kunt doen voordat u de gedetailleerde handleidingen gebruikt.
| Feature | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Azure SQL Managed Instance (een beheerde database-instantie van Azure) | SQL-database in Microsoft Fabric |
|---|---|---|---|---|---|---|
| Externe tabellen | Ja | Ja | Ja | Ja | Ja | Ja |
| OPENROWSET (BULK) | Ja 1 | Ja | Ja | Ja | Ja | Ja |
| CETAS (export) | No | Ja | Ja | No | Ja | No |
| CSV-/gescheiden bestanden | Ja 2 | Ja | Ja | Ja | Ja | Ja |
| Parquet-bestanden | No | Ja | Ja | Ja | Ja | Ja |
| Delta Lake-tabellen | No | Ja | Ja | No | No | No |
| Verbinding maken met een andere SQL Server | Ja | Ja | Ja | No | No | No |
| Verbinding maken met Azure SQL Database of Azure SQL Managed Instance | Ja 3 | Ja 3 | Ja 3 | No | No | No |
| Verbinding maken met Oracle/Teradata/MongoDB | Ja | Ja | Ja | No | No | No |
| Verbinding maken met Azure Blob Storage | Ja | Ja | Ja | Ja | Ja | No |
| Verbinding maken met ADLS Gen2 | No | Ja | Ja | Ja | Ja | No |
| Verbinding maken met S3-compatibele opslag | No | Ja | Ja | No | No | No |
| Verbinding maken met OneLake (Fabric) | No | No | No | No | No | Ja |
| Pushdownberekening | Ja | Ja | Ja | No | No | No |
| beheerde identiteitverificatie | No | No | Ja 4 | Ja | Ja | No |
1 SQL Server 2019 (15.x) ondersteunt OPENROWSET(BULK...) voor lokale en netwerkbestandspaden. In SQL Server 2022 (16.x) en latere versies wordt OPENROWSET(BULK...) ook het lezen vanuit cloudopslag ondersteund met FORMAT = 'PARQUET', FORMAT = DELTAen FORMAT = 'CSV'.
2 CSV-ondersteuning in SQL Server 2019 (15.x) vereist Hadoop. In SQL Server 2022 (16.x) en latere versies wordt CSV systeemeigen ondersteund zonder Hadoop.
3 Maakt gebruik van de SQL Server-connector (sqlserver://). De databasereferenties zijn gericht op het Azure SQL-eindpunt, dezelfde stappen als het maken van verbinding met een andere SQL Server.
4 Verificatie van beheerde identiteit wordt ondersteund voor het maken van verbinding met Azure Blob Storage (ABS) en ADLS Gen2. Hiervoor is SQL Server of SQL Server met Azure Arc vereist op een Azure-VM voor on-premises SQL Server. Het is systeemeigen beschikbaar in Azure SQL Database en Azure SQL Managed Instance.
Opmerking
Vanaf SQL Server 2025 (17.x) is het uitvoeren van query's op gegevensbestanden (CSV, Parquet en Delta) in Azure Blob Storage, ADLS Gen2 of S3-compatibele opslag een systeemeigen enginemogelijkheid en hoeft u geen PolyBase-services meer te installeren of uit te voeren. VOOR RDBMS-connectors (SQL Server, Oracle, Teradata, MongoDB, ODBC) moeten PolyBase-services nog steeds worden geïnstalleerd en uitgevoerd. SQL Server 2025 (17.x) voegt ook Linux-ondersteuning toe voor deze connectors, die eerder alleen beschikbaar waren in Windows.
Query's uitvoeren op externe gegevens
Voordat u een specifiek scenario kiest, moet u de drie manieren begrijpen waarop u externe gegevens kunt opvragen:
| Methode | Syntaxis | Gebruik wanneer | Authentication | PolyBase vereist |
|---|---|---|---|---|
| ad-hocqueries van OLE DB | OPENROWSET(provider, connection, query) |
U wilt een snelle eenmalige query zonder permanente objecten of microsoft Entra ID-verificatie nodig hebben | SQL-verificatie, Windows-verificatie, Microsoft Entra ID (MSOLEDBSQL) | No |
| Ad-hocquery's voor bestanden | OPENROWSET(BULK ...) |
U wilt bestandsgegevens snel verkennen of schema's testen voordat u een tabel maakt | SAS-token, toegangssleutel, Beheerde identiteit, Microsoft Entra-id | Ja voor Azure SQL Database en Azure SQL Managed Instance Nee voor SQL Server-exemplaren |
| Permanente gegevensconnectors |
CREATE EXTERNAL TABLE met sqlserver://, oracle://, teradata://, enz. |
U hebt terugkerende toegang, governance, statistieken en pushdownberekeningen voor productie nodig | Alleen SQL-verificatie | Ja |
PolyBase-services zijn vereist voor toegang tot cloudbestanden in SQL Server 2019 (15.x) en SQL Server 2022 (16.x). SQL Server 2025 (17.x) en latere versies hebben systeemeigen ondersteuning voor CSV, Parquet en Delta zonder PolyBase.
Beslissingshandleiding
| Scenario | Aanbeveling |
|---|---|
| Ik heb Microsoft Entra ID-verificatie nodig voor externe SQL of wil PolyBase-services vermijden | Gebruiken OPENROWSET(MSOLEDBSQL, ...) (ad-hoc, geen permanente objecten) |
| Ik heb permanente tabellen, statistieken of pushdown-berekeningen nodig voor externe databases | Gebruik CREATE EXTERNAL TABLE met PolyBase-connectors (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET biedt geen ondersteuning voor connectors |
| Ik verken een nieuw bestand of test een schema | Gebruiken OPENROWSET(BULK ...) (snelle iteratie, geen permanente objecten) |
| Ik verwerk bestandsgegevens in een tabel door middel van transformaties | Gebruik INSERT ... SELECT van OPENROWSET(BULK ...) |
| Ik heb governance of gedeelde toegang nodig voor veel gebruikers of toepassingen | Gebruik CREATE EXTERNAL TABLE zodat machtigingen en metagegevens gecentraliseerd worden. |
| Ik werk in de SQL-database in Fabric | Gebruiken OPENROWSET(BULK ...) voor ad-hoc OneLake-query's of externe tabellen voor herbruikbare toegang; voor externe opslag gebruikt u OneLake-snelkoppelingen |
Kies uw scenario
Nu u de drie benaderingen begrijpt, gebruikt u een van de volgende handleidingen om uw specifieke use-case te implementeren.
Querybestanden (Parquet, CSV of Delta)
Als uw gegevens zich in Parquet-, CSV- of Delta-bestanden bevinden in Azure Blob Storage, ADLS Gen2, S3-compatibele opslag of OneLake, volgt u een van deze handleidingen:
| Scenario | Aanbevolen handleiding | Platforms |
|---|---|---|
| Snelle ad-hocvraag voor een Parquet- of CSV-bestand | Gebruik OPENROWSET. Er is geen externe tabel nodig |
SQL Server 2022 (16.x) en latere versies, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Herhaalde query's op Parquet-bestanden met een permanent schema | Een externe tabel maken via Parquet | SQL Server 2022 (16.x) en latere versies, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Query's uitvoeren op CSV-bestanden met een externe tabel | Een externe tabel maken met een bestandstype voor door scheidingstekens gescheiden tekst | SQL Server 2019 (15.x) en latere versies, Azure SQL Database, Azure SQL Managed Instance, SQL Database in Fabric |
| Queries uitvoeren op Delta Lake-tabellen | Een externe tabel maken met FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) en latere versies |
| Queryresultaten exporteren naar Parquet- of CSV-bestanden (CETAS) | Gebruik CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) en latere versies, Azure SQL Managed Instance |
U kunt ook een van deze stapsgewijze zelfstudies volgen:
| Handleiding | Beschrijving |
|---|---|
| Aan de slag met PolyBase in SQL Server 2022 | Omvat OPENROWSET met Parquet en CSV, externe tabellen en bestandsmapnavigatie. |
| Parquet-bestand virtualiseren in een met S3 compatibele objectopslag met PolyBase | Zelfstudie voor SQL Server 2022 (16.x) en latere versies. |
| CSV-bestand virtualiseren met PolyBase | Handleiding voor SQL Server 2022 (16.x) en latere versies. |
| Deltatabel virtualiseren met PolyBase | Zelfstudie voor SQL Server 2022 (16.x) en latere versies. |
| Gegevensvirtualisatie met Azure SQL Database (preview) | Azure SQL Database-gids voor Parquet en CSV. |
| Gegevensvirtualisatie met Azure SQL Managed Instance | Handleiding voor Azure SQL Managed Instance voor Parquet, CSV en CETAS. |
| Datavirtualisatie in SQL-database binnen Fabric | SQL Database in Fabric-handleiding voor OneLake-bestanden. |
Verbinding maken met een ander SQL Server-exemplaar, Azure SQL Database of SQL Managed Instance
In SQL Server 2019 (15.x) en latere versies kan PolyBase query's uitvoeren op tabellen in een ander SQL Server-exemplaar, Azure SQL Database of Azure SQL Managed Instance, zonder gekoppelde servers te gebruiken.
Belangrijk
De sqlserver:// connector wordt niet ondersteund in SQL Database in Fabric. PolyBase RDBMS-connectors gebruiken SQL-verificatie via CREATE DATABASE SCOPED CREDENTIAL en bieden geen ondersteuning voor Microsoft Entra ID, Managed Identity of service-principalverificatie. Omdat voor SQL-database in Fabric Microsoft Entra-verificatie is vereist, kunt u er geen verbinding mee maken via PolyBase.
| Stap | Wat u moet doen |
|---|---|
| 1. PolyBase installeren | PolyBase installeren in Windows of PolyBase installeren op Linux |
| 2. Een referentie maken |
CREATE DATABASE SCOPED CREDENTIAL met de doelaanmelding |
| 3. Een externe gegevensbron maken | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Een externe tabel maken | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Opzoeking | SELECT * FROM <external_table> |
Aanbeveling
De SQL Server-connector (sqlserver://) werkt ook voor Azure SQL Database en Azure SQL Managed Instance. Gebruik dezelfde stappen, en stel deze in op het Azure SQL-eindpunt (bijvoorbeeld sqlserver://myserver.database.windows.net).
Zie PolyBase configureren voor toegang tot externe gegevens in SQL Server voor een gedetailleerde handleiding.
Verbinding maken met Oracle, Teradata of MongoDB
SQL Server 2019 (15.x) en latere versies kunnen query's uitvoeren op Oracle, Teradata, MongoDB en Cosmos DB via PolyBase ODBC-connectors.
| Gegevensbron | Guide | Requirements |
|---|---|---|
| Oracle | PolyBase configureren voor toegang tot externe gegevens in Oracle | SQL Server 2019 (15.x) en latere versies, Oracle-clientstuurprogramma's |
| Teradata | PolyBase configureren voor toegang tot externe gegevens in Teradata | SQL Server 2019 (15.x) en latere versies, Teradata ODBC-stuurprogramma |
| MongoDB/Cosmos DB | PolyBase configureren voor toegang tot externe gegevens in MongoDB | SQL Server 2019 (15.x) en latere versies, MongoDB ODBC-stuurprogramma |
| Elke ODBC-bron | PolyBase configureren voor toegang tot externe gegevens met algemene ODBC-typen | SQL Server 2019 (15.x) en latere versies (Windows) (Linux beginnend met SQL Server 2025 (17.x)) |
Verbinding maken met Azure Blob Storage of ADLS Gen2
| SQL platform | Verificatieopties | Guide |
|---|---|---|
| SQL Server 2022 (16.x) en latere versies | SAS-token, toegangssleutel, beheerde identiteit (vanaf SQL Server 2025 (17.x)) | PolyBase configureren voor toegang tot externe gegevens in Azure Blob Storage |
| SQL Server 2019 (15.x) | Toegangssleutel (via Hadoop-connector) | PolyBase configureren voor toegang tot externe gegevens in Azure Blob Storage |
| Azure SQL Database | SAS-token, Beheerde identiteit, Microsoft Entra pass-through | Gegevensvirtualisatie met Azure SQL Database (preview) |
| Azure SQL Managed Instance (een beheerde database-instantie van Azure) | SAS-token, beheerde identiteit | Gegevensvirtualisatie met Azure SQL Managed Instance |
In SQL Server 2022 (16.x) zijn de URI-voorvoegsels gewijzigd. Wanneer u migreert vanuit SQL Server 2019 (15.x) of eerdere versies:
-
Azure Blob Storage: wijzigen
wasb[s]://inabs:// -
ADLS Gen2: wijzigen
abfs[s]://inadls://
Zie PolyBase configureren voor toegang tot externe gegevens in Azure Blob Storage voor meer informatie.
Verbinding maken met S3-compatibele objectopslag
SQL Server 2022 (16.x) en latere versies ondersteunen S3-compatibele opslag, zoals Amazon S3, MinIO en Ceph.
Zie PolyBase configureren voor toegang tot externe gegevens in S3-compatibele objectopslag voor meer informatie.
Gegevens exporteren met CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS voert de export uit van queryresultaten naar externe bestanden (Parquet of CSV) in Azure Blob Storage, ADLS Gen2 of S3-compatibele opslag.
| SQL platform | Ondersteund | Exportformaten | Aantekeningen |
|---|---|---|---|
| SQL Server 2022 (16.x) en latere versies | Ja | Parquet, CSV | Serverconfiguratie vereist : polybase-export toestaan |
| Azure SQL Managed Instance (een beheerde database-instantie van Azure) | Ja | Parquet, CSV | Standaard uitgeschakeld |
| Azure SQL Database | No | Geen | Niet beschikbaar |
| Een SQL-database in Fabric | No | Geen | Niet beschikbaar |
Zie CREATE EXTERNAL TABLE AS SELECT (CETAS) voor de Transact-SQL referentie.
Voorbeelden van snel starten
Voorbeeld 1: Ad-hoc-query voor een Parquet-bestand (OPENROWSET)
Er is geen externe tabel nodig. Werkt op SQL Server 2022 (16.x) en latere versies, Azure SQL Database, Azure SQL Managed Instance en SQL Database in Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Voorbeeld 2: Externe tabel via CSV in Azure Blob Storage
Dit voorbeeld werkt op alle SQL-platforms die PolyBase ondersteunen.
Stap 1: Een databasehoofdsleutel (DMK) maken. Deze stap is vereist omdat met de referentie een SAS-tokengeheim wordt opgeslagen. U kunt deze stap echter uitvoeren als u beheerde identiteit of Microsoft Entra-verificatie gebruikt.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Stap 2: Maak een referentie met een SAS-token. Laat de voorafgaande
?weg.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Stap 3: Een externe gegevensbron maken.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Stap 4: Maak een bestandsindeling voor het CSV-bestand.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Stap 5: Maak de externe tabel.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Stap 6: Voer een query uit op de externe tabel.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Voorbeeld 3: Een query uitvoeren op een tabel in een andere SQL Server
Dit voorbeeld werkt in SQL Server 2019 (15.x) en latere versies.
Stap 1: Maak een databasehoofdsleutel (vereist omdat de referentie een wachtwoord opslaat).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Stap 2: Maak een referentie voor het externe SQL Server-exemplaar.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Stap 3: Maak de externe gegevensbron.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Stap 4: Maak de externe tabel aan (met de driedelige naam in
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Stap 5: Query uitvoeren op servers.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Voorbeeld 4: Resultaten exporteren naar Parquet met CETAS
Werkt op SQL Server 2022 (16.x) en latere versies, Azure SQL Managed Instance.
Stap 1: CETAS inschakelen (alleen SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Stap 2: Referentie en gegevensbron maken (hergebruik uit eerdere voorbeelden).
Stap 3: Maak een bestandsindeling voor Parquet-export.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Stap 4: Queryresultaten exporteren.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
T-SQL-bouwstenen voor PolyBase
Voordat u een scenario implementeert, moet u inzicht hebben in de T-SQL-kernobjecten die PolyBase gebruikt en hoe ze bij elkaar passen:
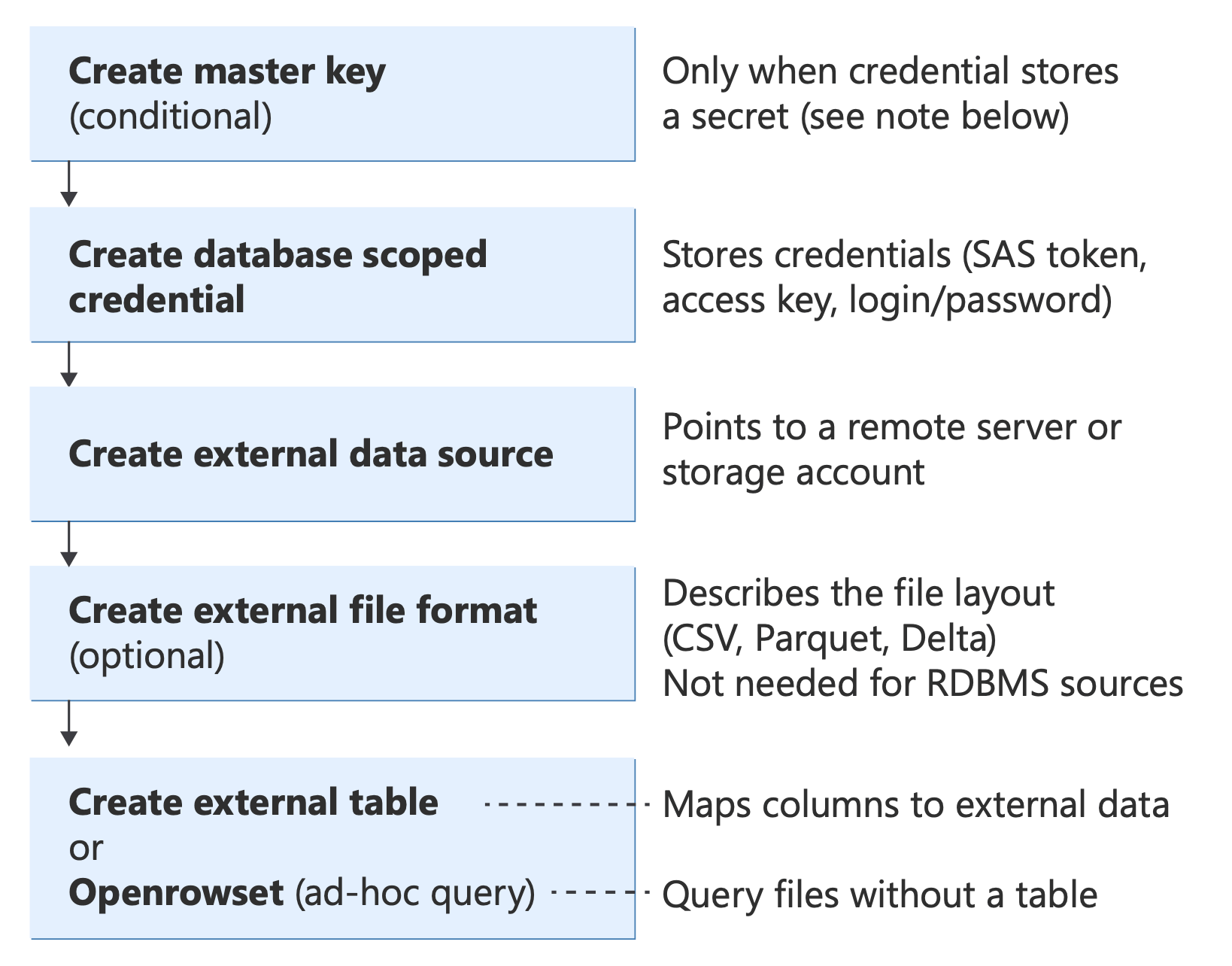
Diagram met PolyBase T-SQL-objecten en hun relaties, van verificatie (databasehoofdsleutel, referenties) via gegevensbronnen en bestandsindelingen tot querymethoden (externe tabel, OPENROWSET, BULK INSERT, CETAS).
Zie voor meer informatie over deze T-SQL-instructies:
- MAAK EXTERNE GEGEVENSBRON AAN
- CREËER EXTERN BESTANDSFORMAT
- CREËER EXTERNE TABEL
- OPENROWSET
- CREATE EXTERNAL TABLE AS SELECT (CETAS)
Zie voor een volledige Transact-SQL-referentie voor alle objecten de PolyBase Transact-SQL naslaginformatie.
Belangrijk
Controleer de toewijzing van het gegevenstype voor uw externe bestandsindeling. Wanneer u een externe bestandsindeling maakt of query's uitvoert op bestanden met behulp van OPENROWSETPolyBase, worden brongegevenstypen (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) automatisch toegewezen aan SQL Server-gegevenstypen. Ongelijksoortige typen kunnen onopgemerkte afkorting, precisieverlies of queryfouten veroorzaken. Een Parquet DECIMAL(38,18) komt bijvoorbeeld overeen met DECIMAL(18,0). Controleer de toewijzingstabellen voordat u externe tabelkolommen of een WITH clausule definieert. Zie Typetoewijzing met PolyBase voor de volledige referentie.
Wanneer is CREATE MASTER KEY vereist?
Er wordt een DMK (Database Master Key) gemaakt met behulp van CREATE MASTER KEY de syntaxis. De DMK versleutelt de geheimen die zijn opgeslagen in database-specifieke inloggegevens. Dit is alleen vereist wanneer de referentie een geheime waarde bevat, dat wil gezegd, wanneer een wachtwoord, token of toegangssleutel wordt opgeslagen.
DMK is vereist (authenticatiereferenties bevatten een geheim):
Verificatietype IDENTITYwaardeHeeft geheim DMK SAS-token 'SHARED ACCESS SIGNATURE'Ja Verplicht S3-toegangssleutel 'S3 ACCESS KEY'Ja Verplicht SQL-aanmelding/basisverificatie '<username>'Ja Verplicht Toegangssleutel voor opslagaccount '<storage_account_name>'Ja Verplicht DMK is niet vereist (geen geheim opgeslagen):
Verificatietype IDENTITYwaardeHeeft geheim DMK Beheerde identiteit 'Managed Identity'No Niet vereist Microsoft Entra ID 'User Identity'of'Managed Identity'No Niet vereist
Aanbeveling
Als uw verklaring geen geheim CREATE DATABASE SCOPED CREDENTIAL bevat, hebt u geen DMK nodig. Managed Identity en Microsoft Entra ID-verificatie delegeren vertrouwen aan het platform. In de database worden geen wachtwoorden of tokens opgeslagen.
Voorbeelden:
In deze voorbeeldquery is de DMK vereist (de inloggegevens slaan een SAS-token op).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
In deze voorbeeldquery is de DMK niet vereist (Beheerde identiteit, geen geheim).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
In deze voorbeeldquery is de DMK niet vereist (Microsoft Entra pass-through, geen geheim).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Externe gegevenstoegang met OPENROWSET en externe tabellen
SQL Server biedt drie verschillende benaderingen voor het uitvoeren van query's op externe gegevens. U kunt de juiste benadering kiezen wanneer u de verschillen in syntaxis, verificatie en architectuur begrijpt.
| Methode | Syntaxis | Verbinding maken met | Authentication | PolyBase-services | Platforms |
|---|---|---|---|---|---|
| OLE DB-query's | OPENROWSET(provider, connection, query) |
Een OLE DB-bron via MSOLEDBSQL, SQLOLEDB of andere providers | SQL-verificatie, Windows-verificatie, Microsoft Entra ID (MSOLEDBSQL) | No | SQL Server (alle ondersteunde versies) |
| Bestandsquerys | OPENROWSET(BULK ...) |
Bestanden op lokale schijf, netwerk of cloud (Azure Blob, ADLS, S3, OneLake) | SAS-token, toegangssleutel, Beheerde identiteit, Microsoft Entra-id | Ja voor cloud*; Nee voor lokaal | SQL Server 2005; SQL Server 2022 (16.x) en latere versies (cloud); Azure SQL |
| PolyBase connectors |
CREATE EXTERNAL TABLE met CREATE EXTERNAL DATA SOURCE door gebruik te maken van sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Externe SQL Server, Oracle, Teradata, MongoDB, ODBC-bronnen | Alleen SQL-verificatie | Ja | SQL Server 2019 (15.x) en latere versies (Windows); SQL Server 2025 (17.x) en latere versies (Linux) |
PolyBase-services zijn vereist voor toegang tot cloudbestanden in SQL Server 2019 (15.x) en SQL Server 2022 (16.x). SQL Server 2025 (17.x) en latere versies hebben systeemeigen cloudbestandsondersteuning en vereisen geen PolyBase meer voor CSV, Parquet of Delta.
Wanneer moet u elke benadering gebruiken
OLE DB OPENROWSET gebruiken voor:
- Snelle, eenmalige ad hoc queries zonder het maken van permanente objecten.
- Microsoft Entra ID- of Managed Identity-authenticatie (via MSOLEDBSQL)
- PolyBase-serviceafhankelijkheden vermijden
- Verbinding maken met een gegevensbron met een OLE DB-provider
Gebruik File OPENROWSET(BULK) voor:
- Ad hoc bestandsverkenning en schemadetectie
- Snelle transformaties en previews voordat u een tabeldefinitie doorvoert
- Flexibele kolomtransformaties inline (casten, filteren, berekende kolommen)
- Gegevens die niet regelmatig worden gewijzigd en die geen permanente metagegevens nodig hebben
PolyBase-connectors gebruiken met CREATE EXTERNAL TABLE voor:
- Permanente, herbruikbare tabeldefinities die worden geopend door meerdere gebruikers of toepassingen
- Productieworkloads waarvoor statistieken en optimalisatie van queryplannen zijn vereist
- Pushdownberekening naar externe bronnen (filters pushen naar Oracle, SQL Server, enzovoort)
- Gedeelde governance en beveiliging (zodra ze zijn gemaakt, hebben gebruikers alleen machtigingen nodig
SELECT) - Wanneer u SQL-verificatie beschikbaar hebt voor de externe bron
OPENROWSET (OLE DB) - ad hoc externe queries (geen PolyBase-services vereist)
De OLE DB-vorm van OPENROWSET verbindt met een externe gegevensbron via een OLE DB-provider, voert een passthrough-query uit en retourneert de resultaten als een gegevensset. Het is een eenmalig ad-hoc alternatief voor een gekoppelde server. Er worden geen permanente metagegevens gemaakt. Voor deze syntaxis zijn geen PolyBase-services vereist en worden geen cloudbestanden of externe gegevensbronnen ondersteund.
Deze voorbeeldquery maakt verbinding met een externe SQL Server via OLE DB (niet PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - bestandgebaseerde queries (PolyBase)
De BULK vorm van OPENROWSET leest gegevens rechtstreeks uit bestanden. In SQL Server 2019 (15.x) en eerdere versies wordt het gelezen uit lokale of UNC-bestandspaden en is een indelingsbestand vereist. In SQL Server 2022 (16.x) en latere versies kunt u lezen uit cloudopslag met behulp van de DATA_SOURCE en FORMAT parameters. Deze benadering is de geïntegreerde PolyBase-versie die wordt gebruikt voor gegevensvirtualisatie.
In de context van PolyBase en gegevensvirtualisatie betekent deze handleiding dat wanneer wordt verwezen naar OPENROWSET, het gaat om de syntaxis OPENROWSET(BULK ...) met een clausule FORMAT voor het uitvoeren van query's op externe bestanden.
Voorbeelden:
Deze voorbeeldquery leest een Parquet-bestand uit Azure Blob Storage (SQL Server 2022 en latere versies).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Deze voorbeeldquery leest een Parquet-bestand met een inlinepad (Azure SQL Database, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Wanneer gebruikt u OPENROWSET versus externe tabellen
Met beide OPENROWSET(BULK ...) en externe tabellen kunt u query's uitvoeren op externe gegevens met T-SQL, maar ze zijn ontworpen voor verschillende gebruiksvoorbeelden. De volgende tabel bevat een overzicht van de belangrijkste verschillen waarmee u kunt bepalen welke benadering past bij uw scenario.
| Vermogen | OPENROWSET(BULK ...) |
Externe tabel |
|---|---|---|
| Purpose | Ad-hoconderzoek en eenmalige query's | Permanente, herbruikbare tabeldefinitie |
| Metagegevens die zijn opgeslagen in database | Nee. Er wordt niets opgeslagen nadat de query is uitgevoerd | Ja. De tabeldefinitie, gegevensbron en bestandsindeling worden opgeslagen als databaseobjecten |
| Schemadefinitie | Automatisch afgeleid uit het bestand (Parquet) of opgegeven inline met een WITH clausule |
Expliciet gedefinieerd in de CREATE EXTERNAL TABLE instructie |
| toestemmingen | Vereist ADMINISTER BULK OPERATIONS of ADMINISTER DATABASE BULK OPERATIONS |
Zodra de tabel is gemaakt, is de standaardmachtiging SELECT voor de tabel voldoende |
| Berekende kolommen | Ja. Voeg expressies en berekende kolommen toe in de SELECT lijst; metagegevensfuncties zoals filename() en filepath() zijn hier alleen beschikbaar. |
Nee. Vaste kolomlijst; transformaties uitvoeren in een weergave of in de query die de externe tabel leest |
| statistieken | Azure SQL: handmatige statistieken met één kolom via sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) en latere versies: automatisch statistieken maken op predicaten (geen handmatige statistieken op SQL Server). Zie handmatige statistieken van OPENROWSET. |
Volledige CREATE STATISTICS ondersteuning op alle platforms, plus automatisch maken in SQL Server 2022 (16.x) en nieuwere versies. Zie Handmatige statistieken voor externe tabellen maken. |
| Pushdown | Beperkte ondersteuning. De engine kan filters naar beneden pushen naar de bestandsscan, maar er is geen pushdown naar externe RDBMS-bronnen | Ja. Ondersteunt pushdownberekeningen voor RDBMS-connectors (SQL Server, Oracle, Teradata, MongoDB) |
| Het beste voor | Gegevensverkenning, schemadetectie, prototypequery's, eenmalige gegevensbelastingen, flexibele transformaties | Productieworkloads, herhaalde query's, gedeelde toegang voor gebruikers, dashboards en rapportage |
OPENROWSET gebruiken wanneer u flexibiliteit nodig hebt
Gebruik OPENROWSET dit om een bestand te verkennen, verschillende schema's te testen of berekende kolommen en transformaties toe te voegen zonder permanente objecten te maken. U kunt bijvoorbeeld het bestandspad extraheren als een kolom, gegevenstypen inline casten of filteren op berekende expressies in één query.
Deze voorbeeldquery bevat berekende kolommen en transformaties:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Aanbeveling
De filepath() en filename() functies zijn beschikbaar in Azure SQL Database, Azure SQL Managed Instance en SQL Server 2022 (16.x) en latere versies. Hiermee kunt u filteren op delen van het bestandspad (partitie-verwijdering) en de naam van het bronbestand beschikbaar maken als een kolom, wat niet rechtstreeks mogelijk is met externe tabellen.
Externe tabellen gebruiken wanneer u persistentie en governance nodig hebt
Gebruik externe tabellen wanneer meerdere gebruikers of toepassingen herhaaldelijk dezelfde externe gegevens moeten opvragen. U definieert het schema, de gegevensbron en de referenties eenmaal en slaat deze op in de database. Gebruikers hebben alleen SELECT toestemming nodig voor de tabel.
Externe tabellen ondersteunen ook statistieken, die de queryoptimalisatie gebruikt om betere uitvoeringsplannen te maken. U kunt statistieken handmatig maken of de engine deze automatisch laten maken (SQL Server 2022 (16.x) en latere versies).
Met deze voorbeeldquery worden statistieken voor een externe tabel gemaakt voor betere queryplannen.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Zie PolyBase-prestatieoverwegingen - Statistieken voor meer informatie over statistieken voor beide benaderingen.
BULK INSERT versus OPENROWSET(BULK): Welke moet ik gebruiken?
Zowel BULK INSERT als OPENROWSET(BULK ...) importeren gegevens uit bestanden in SQL Server met behulp van dezelfde onderliggende bulk-loading engine. Ze verschillen echter in syntaxis, flexibiliteit en wat u met de resultaten kunt doen. De volgende tabel bevat een overzicht van de belangrijkste verschillen:
Opmerking
BULK INSERT is niet beschikbaar in SQL Database in Fabric. Gebruik OPENROWSET(BULK ...) tegen OneLake voor Fabric.
| Vermogen | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Basisdoel | Gegevens uit een bestand rechtstreeks in een doeltabel laden | Retourneert een rijenset die je in een SELECT- of INSERT ... SELECT-instructie gebruikt |
| Gebruikspatroon | Zelfstandige uitspraak: BULK INSERT <table> FROM '<file>' |
Moet worden gebruikt in een query: SELECT * FROM OPENROWSET(BULK ...) of INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Is er een doeltabel nodig? | Ja. Schrijft altijd rechtstreeks naar een tabel | Nee. U kunt SELECT direct gebruiken zonder ergens in te voegen, of in een tabel of tijdelijke tabel invoegen. |
| Kolomtransformaties tijdens het laden | Beperkte ondersteuning. De gegevens stromen zonder wijziging van bestand naar tabel (toewijzing beheerd door indelingsbestand of kolomvolgorde) | Volledige ondersteuning. U kunt expressies, CASTWHERE filters, JOIN andere tabellen en berekende kolommen toevoegen in de omgevingSELECT |
| Tafeltips | De WITH component bevat ondersteuning voor BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, , KEEPNULLS, , en TABLOCKmeer |
Ondersteunt tabelhints via de INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) syntaxis |
| Import van één waarde voor groot object (LOB) | Niet ondersteund | Ja. Ondersteunt SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB om een volledig bestand te importeren als één varbinary(max), varchar(max), of nvarchar(max) waarde |
| Bestanden formatteren | Ja. Ondersteund via (XML en niet-XML) | Ja. Ondersteund (XML en niet-XML) |
| Toegang tot cloudbestanden (Azure Blob Storage, ADLS Gen2, S3) | Ja. Ondersteund via DATA_SOURCE parameter (SQL Server 2017 (14.x) en latere versies, Azure SQL) |
Ja. Ondersteund via DATA_SOURCE parameter ofwel inline URL met FORMAT clausule (SQL Server 2022 (16.x) en latere versies, Azure SQL) |
| Parquet- of Delta-bestanden | Wordt niet ondersteund. Alleen CSV-/gescheiden tekstbestanden | Ja. Ondersteund met FORMAT = 'PARQUET' of FORMAT = 'DELTA' (SQL Server 2022 (16.x) en latere versies, Azure SQL) |
| Machtiging vereist |
ADMINISTER BULK OPERATIONS of ADMINISTER DATABASE BULK OPERATIONS, plus INSERT op de doeltabel |
ADMINISTER BULK OPERATIONS of ADMINISTER DATABASE BULK OPERATIONS |
| Minimale logboekregistratie | Ja. Ondersteund onder eenvoudige of bulksgewijs vastgelegde herstelmodellen met TABLOCK |
Ja. Ondersteund bij gebruik met INSERT ... SELECT en TABLOCK |
Wanneer kiest u BULK INSERT
Gebruik BULK INSERT wanneer u een eenvoudige bestand-naar-tabel laden heeft en geen gegevens hoeft te transformeren, filteren of samenvoegen tijdens het importeren. Er wordt gebruikgemaakt van eenvoudigere syntaxis voor CSV- of andere bestanden met scheidingstekens:
In dit voorbeeld wordt een CSV-bestand vanuit Azure Blob Storage rechtstreeks in een tabel geladen.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
In dit voorbeeld wordt een lokaal bestand geladen met een formaatbestand voor kolomtoewijzing.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Wanneer moet u OPENROWSET(BULK) kiezen
Gebruik OPENROWSET(BULK ...) deze optie wanneer u een of meer van de volgende voorwaarden nodig hebt:
- Query's uitvoeren of bestandsgegevens bekijken zonder eerst een tabel te maken.
- Gegevens transformeren, filteren of samenvoegen tijdens het importeren.
-
Laad Parquet- of Delta-bestanden (alleen
OPENROWSETondersteunt deze indelingen). -
Een volledig bestand importeren als één LOB-waarde (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
In dit voorbeeldquery wordt een CSV-bestand uit Azure Blob Storage weergegeven zonder de gegevens ergens in te voegen.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
Met deze voorbeeldquery worden gegevens ingevoegd met transformatie en filteren.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Met deze voorbeeldquery wordt een Parquet-bestand geladen (niet mogelijk met BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
Met deze voorbeeldquery wordt een heel XML-bestand geïmporteerd als één varbinary(max) -waarde.
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Aanbeveling
Een benadering is om te beginnen met OPENROWSET(BULK ...) in een SELECT om bestandsgegevens te verkennen en te valideren, en vervolgens over te schakelen naar BULK INSERT voor de definitieve productielading als u geen transformaties nodig hebt. Als u parquet- of Delta-ondersteuning of inlinefiltering nodig hebt, moet u bij OPENROWSET blijven.
Zie de volgende gerelateerde handleidingen voor meer informatie:
- Gebruik BULK INSERT of OPENROWSET(BULK...) om gegevens te importeren in SQL Server: een gedetailleerde handleiding met beveiligingsoverwegingen.
-
Bulkimport en export van gegevens (SQL Server): een overzicht van alle methoden voor bulkgegevensverplaatsing (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): een volledige T-SQL-verwijzing.
- OPENROWSET BULK (Transact-SQL): een volledige T-SQL-verwijzing.
- Voorbeelden van bulktoegang tot gegevens in Azure Blob Storage: voorbeelden naast elkaar met behulp van beide methoden met Azure Storage.
-
Gegevens van grote objecten bulksgewijs importeren met OPENROWSET Bulk Rowset Provider (SQL Server):,
SINGLE_BLOBSINGLE_CLOBenSINGLE_NCLOBvoorbeelden. - Gebruik een indelingsbestand om gegevens bulkgewijs te importeren (SQL Server): gebruik van formatbestanden met beide methoden.
Nuttige metagegevensfuncties
Wanneer u query's uitvoert op externe bestanden met OPENROWSET of externe tabellen, kunt u verschillende ingebouwde functies en procedures gebruiken om metagegevens van bestanden te inspecteren, schema's te detecteren en partitiebewuste query's te implementeren.
filepath() en bestandsnaam()
De filepath() en filename() functies retourneren delen van de bestandsnaam of het bestandspad voor elke rij in de resultatenset. Ze zijn vooral handig voor:
Partitie-verwijdering: Filter op mapsegmenten (bijvoorbeeld jaar-/maand-/dagpartities) zodat de engine alleen de overeenkomende bestanden leest in plaats van alles te scannen.
Metagegevens van bron beschikbaar maken: neem de oorspronkelijke bestandsnaam of het oorspronkelijke pad op als een kolom in de queryresultaten. Dit is handig voor controle of foutopsporing.
| Function | Retouren | Voorbeeld |
|---|---|---|
filename() |
De bestandsnaam (inclusief extensie) van het bronbestand voor elke rij | sales_2025_01.parquet |
filepath(N) |
Het Nde mapsegment van het jokerteken (*) in het BULK pad, waarbij N begint bij 1 |
Bij het pad sales/2025/01/*.parquet, geeft filepath(1)2025 terug en geeft filepath(2)01 terug |
Van toepassing op: Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) en latere versies, SQL Database in Fabric.
In deze voorbeeldquery wordt filepath() gebruikgemaakt van partitie-verwijdering en filename() om bronbestanden te identificeren. Het leest alleen bestanden onder de /2025/ map en leest alleen bestanden onder de /06/ submap.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Aanbeveling
Plaats filepath() filters in de WHERE component in plaats van in een subquery of CTE. Wanneer het filter zich in de WHERE component bevindt, kan de engine partitie-verwijdering uitvoeren op het niveau van de bestandsscan, wat de I/O aanzienlijk vermindert.
sp_describe_first_result_set - het ontdekken van OPENROWSET-kolomtypen
Wanneer u OPENROWSET met Parquet-bestanden gebruikt, worden kolomgegevenstypen automatisch afgeleid (schema-afleiding). De afgeleide typen kunnen groter zijn dan nodig is. Tekenkolommen worden bijvoorbeeld vaak afgeleid als varchar(8000), omdat Parquet-metagegevens geen maximale lengte bevatten. Deze keuze kan de prestaties verminderen en meer geheugen verbruiken.
Gebruik sp_describe_first_result_set om het afgeleide schema te inspecteren voordat u de query afrondt. Nadat u de afgeleide typen hebt bekeken, specificeert u smallere typen in een WITH clausule om de prestaties te verbeteren.
Stap 1: Inspecteer het uitgestelde schema.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';De uitvoer toont de naam van elke kolom, afgeleid gegevenstype, maximale lengte, precisie en schaal. Als u varchar(8000) ziet waarbij een varchar(100) volstaat, overschrijft u het volgende:
Stap 2: Gebruik expliciete typen voor betere prestaties.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
Schemadeductie werkt alleen met Parquet-bestanden. Geef voor CSV-bestanden altijd kolomdefinities op in een WITH component (voor OPENROWSET) of in de CREATE EXTERNAL TABLE instructie.
sp_describe_first_result_set is een algemene SQL Server- en Azure SQL-procedure, maar dit is vooral handig voor OPENROWSET query's. Voor meer informatie, zie sp_describe_first_result_set.
Prestaties, probleemoplossing en aanbevolen procedures
Nadat u gegevensvirtualisatie hebt geïmplementeerd, gebruikt u deze handleidingen om prestaties te optimaliseren, problemen te diagnosticeren en de gereedheid van de productie te garanderen:
| Oppervlak | Artikel | Details |
|---|---|---|
| PolyBase-prestaties | Prestatieoverwegingen in PolyBase voor SQL Server- | Statistieken, pushdown, parallellisme en geheugenbeheer |
| Pushdownberekening | Pushdown-berekeningen in PolyBase | Hiermee geeft u op welke bewerkingen naar de externe bron worden gepusht |
| Hoe te herkennen of er een pushdown heeft plaatsgevonden | Hoe kunt u zien of er een externe pushdown is opgetreden | Queryplannen en DMV's |
| Troubleshooting | PolyBase- bewaken en problemen oplossen | Veelvoorkomende fouten en oplossingen |
| Kerberos-connectiviteit | Problemen met PolyBase Kerberos-connectiviteit oplossen | |
| Veelgestelde vragen | Veelgestelde vragen over PolyBase | |
| Fouten en oplossingen | PolyBase-fouten en mogelijke oplossingen |