Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Met Zoekopdracht in volledige tekst in SQL Server en Azure SQL Database kunnen gebruikers en toepassingen query's in volledige tekst uitvoeren op gegevens op basis van tekens in SQL Server-tabellen.
Basisactiviteiten
In dit artikel vindt u een overzicht van Full-Text Zoeken en worden de onderdelen en architectuur ervan beschreven. Als u liever meteen aan de slag wilt gaan, zijn dit de basistaken.
- Aan de slag met Full-Text Search-
- Full-Text catalogi maken en beheren
- Volledige-tekstindexen maken en beheren
- Indexen vullen Full-Text
- de query uitvoeren met Full-Text
Full-Text Search is een optioneel onderdeel van de SQL Server Database Engine. Als u Full-Text Zoeken niet hebt geselecteerd toen u SQL Server hebt geïnstalleerd, voert u SQL Server Setup opnieuw uit om deze toe te voegen.
Overzicht
Een volledige-tekstindex bevat een of meer op tekens gebaseerde kolommen in een tabel. Deze kolommen kunnen een van de volgende gegevenstypen hebben: char, varchar, nchar, nvarchar, text, ntext, image, xml of varbinary(max) en FILESTREAM. Elke index in volledige tekst indexeert een of meer kolommen uit de tabel en elke kolom kan een specifieke taal gebruiken.
Query's in volledige tekst voeren taalkundige zoekopdrachten uit op tekstgegevens in indexen in volledige tekst door te werken op woorden en woordgroepen op basis van de regels van een bepaalde taal, zoals Engels of Japans. Query's in volledige tekst kunnen eenvoudige woorden en woordgroepen of meerdere vormen van een woord of woordgroep bevatten. Een volledige tekstquery retourneert documenten die ten minste één overeenkomst (ook wel hit genoemd) bevatten. Een overeenkomst treedt op wanneer een doeldocument alle termen bevat die zijn opgegeven in de query voor volledige tekst en voldoet aan andere zoekvoorwaarden, zoals de afstand tussen de overeenkomende termen.
Full-Text zoekopdrachten
Nadat kolommen zijn toegevoegd aan een index voor volledige tekst, kunnen gebruikers en toepassingen volledige tekstquery's uitvoeren op de tekst in de kolommen. Deze query's kunnen zoeken naar een van de volgende voorwaarden:
- Een of meer specifieke woorden of woordgroepen (eenvoudige term)
- Een woord of een woordgroep waarin de woorden beginnen met opgegeven tekst (voorvoegselterm)
- Inflectionele vormen van een specifiek woord (generatieterm)
- Een woord of woordgroep dicht bij een ander woord of een andere woordgroep (nabijheidsterm)
- Synoniemen van een specifiek woord (synoniemenlijst)
- Woorden of woordgroepen met gewogen waarden (gewogen term)
Query's in volledige tekst zijn niet hoofdlettergevoelig. Als u bijvoorbeeld zoekt naar Aluminum of aluminum, krijgt u dezelfde resultaten.
Query's in volledige tekst maken gebruik van een kleine set Transact-SQL predicaten (CONTAINSenFREETEXT) en functies (CONTAINSTABLEen).FREETEXTTABLE De zoekdoelen van een bepaald bedrijfsscenario zijn echter van invloed op de structuur van de query's in volledige tekst. Voorbeeld:
Een product zoeken op een e-commercewebsite:
SELECT product_id FROM products WHERE CONTAINS (product_description, '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Wervingsscenario's voor het zoeken naar kandidaten die ervaring hebben met het werken met SQL Server:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS (candidate_resume, '"SQL Server"') AND candidate_division = 'DBA';
Zie Query met Full-Text Zoeken voor meer informatie.
Full-Text Zoekquery's vergelijken met het predicaat LIKE
In tegenstelling tot zoeken in volledige tekst werkt het predicaat LIKE Transact-SQL alleen op tekenpatronen. U kunt het predicaat ook niet gebruiken LIKE om opgemaakte binaire gegevens op te vragen. Bovendien is een LIKE query met een grote hoeveelheid ongestructureerde tekstgegevens veel langzamer dan een equivalente volledige-tekstquery voor dezelfde gegevens. Een LIKE query op miljoenen rijen met tekstgegevens kan enkele minuten duren om terug te keren. Een query in volledige tekst kan slechts enkele seconden of minder duren voor dezelfde gegevens, afhankelijk van het aantal rijen dat wordt geretourneerd.
Zoekarchitectuur voor Full-Text
De zoekarchitectuur voor volledige tekst bestaat uit de volgende processen:
Het SQL Server-proces (
sqlservr.exe).Het hostproces van de filterdaemon (
fdhost.exe).Om veiligheidsredenen worden filters geladen door afzonderlijke processen, de filter-daemonhosts genoemd. De
fdhost.exeprocessen worden gemaakt door een FDHOST-startprogrammaservice (MSSQLFDLauncher) en worden uitgevoerd onder de beveiligingsreferenties van het FDHOST-startprogrammaserviceaccount. Daarom moet de FDHOST-startprogrammaservice worden uitgevoerd voor het indexeren van volledige tekst en het uitvoeren van query's op volledige tekst. Voor meer informatie over het instellen van het serviceaccount voor deze service, zie Het Serviceaccount instellen voor de Volledige-tekst Filter Daemon Launcher.
Deze twee processen bevatten de onderdelen van de zoekarchitectuur voor volledige tekst. Deze onderdelen en hun relaties worden samengevat in de volgende afbeelding. De onderdelen worden na de afbeelding beschreven.
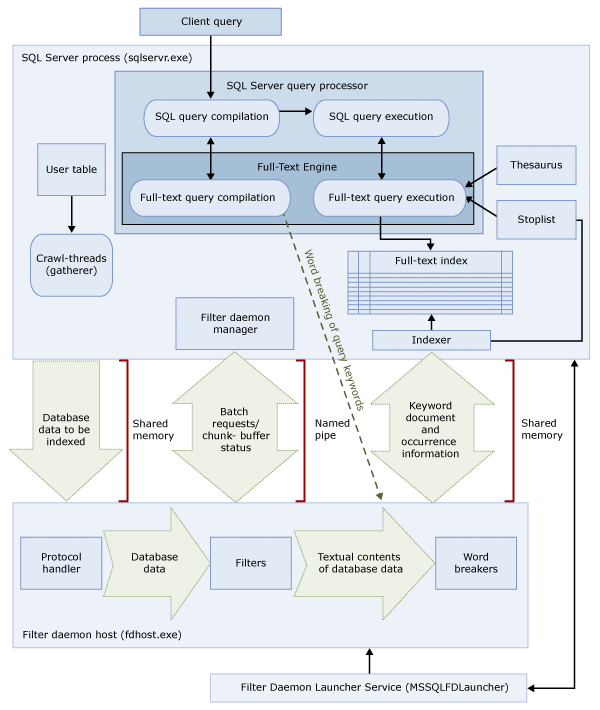
SQL Server-proces
Het SQL Server-proces maakt gebruik van de volgende onderdelen voor zoeken in volledige tekst:
| Onderdeel | Beschrijving |
|---|---|
| Gebruikerstabellen | Deze tabellen bevatten de gegevens die moeten worden geïndexeerd in volledige tekst. |
| Gegevensverzamelaar voor volledige tekst | De gegevensverzamelaar voor volledige tekst werkt met de verkenningsthreads voor volledige tekst. Het is verantwoordelijk voor het plannen en stimuleren van de populatie van indexen in volledige tekst, en ook voor het bewaken van catalogussen met volledige tekst. |
| Synoniemenlijstbestanden | Deze bestanden bevatten synoniemen van zoektermen. Zie Synoniemenlijstbestanden configureren en beheren voor Full-Text Zoeken voor meer informatie. |
| Stoplist-objecten | Stoplist-objecten bevatten een lijst met veelgebruikte woorden die niet nuttig zijn voor de zoekopdracht. Voor meer informatie, zie Stopwords en Stoplists configureren en beheren voor Full-Text zoeken. |
| SQL Server-queryprocessor | De queryprocessor compileert en voert SQL-query's uit. Als een SQL-query een zoekquery voor volledige tekst bevat, wordt de query verzonden naar de Full-Text Engine, zowel tijdens de compilatie als tijdens de uitvoering. Het queryresultaat wordt vergeleken met de volledige-tekstindex. |
| Full-Text Motor | De Full-Text Engine in SQL Server is volledig geïntegreerd met de queryprocessor. De Full-Text Engine compileert en voert volledige-tekstquery's uit. Als onderdeel van de uitvoering van query's kan de Full-Text Engine mogelijk input ontvangen van de synoniemenlijst en de stopwoordenlijst. |
| Indexschrijver (indexeerfunctie) | De indexschrijver bouwt de structuur die wordt gebruikt om de geïndexeerde tokens op te slaan. |
| Filterdaemonbeheerder | De manager van de filterdaemon is verantwoordelijk voor het bewaken van de status van de Full-Text Engine-filterdaemonhost. |
Filterdemon-hostproces
De filterdemonhost is een proces dat wordt gestart door de Full-Text Engine. Hiermee worden de volgende zoekonderdelen voor volledige tekst uitgevoerd, die verantwoordelijk zijn voor het openen, filteren en breken van woorden uit tabellen, evenals voor woordafbreking en het uitbreken van de query-invoer.
De onderdelen van de filterdemonhost zijn als volgt:
| Onderdeel | Beschrijving |
|---|---|
| Protocolhandler | Dit onderdeel haalt de gegevens op uit het geheugen voor verdere verwerking en heeft toegang tot gegevens uit een gebruikerstabel in een opgegeven database. Een van de verantwoordelijkheden is het verzamelen van gegevens uit de kolommen die zijn geïndexeerd in volledige tekst en deze door te geven aan de filterdaemonhost, waarmee filteren en woordafbreking naar behoefte worden toegepast. |
| Filters | Voor sommige gegevenstypen is filteren vereist voordat de gegevens in een document kunnen worden geïndexeerd in volledige tekst, inclusief gegevens in varbinary-, varbinaire(max)-, afbeeldings- of XML-kolommen . Het filter dat wordt gebruikt voor een bepaald document, is afhankelijk van het documenttype. Er worden bijvoorbeeld verschillende filters gebruikt voor Microsoft Word -.docdocumenten, Microsoft Excel-documenten (.xls) en XML-documenten (.xml). Vervolgens extraheert het filter segmenten van tekst uit het document, verwijdert u de ingesloten opmaak en behoudt u de tekst en mogelijk informatie over de positie van de tekst. Het resultaat is een stroom tekstuele informatie. Zie Filters configureren en beheren voor zoeken voor meer informatie. |
| Woordonderbrekers en stemmers | Een woordonderbreker is een taalspecifiek onderdeel waarmee woordgrenzen worden gevonden op basis van de lexicale regels van een bepaalde taal (woordonderbreking). Elke woordonderbreker is gekoppeld aan een taalspecifiek stemmeronderdeel dat werkwoorden samenvoegt en inflectionele uitbreidingen uitvoert. Tijdens het indexeren gebruikt de filterdaemonhost een woordonderbreker en stemmer om taalkundige analyse uit te voeren op de tekstuele gegevens uit een bepaalde tabelkolom. De taal die is gekoppeld aan een tabelkolom in de index voor volledige tekst bepaalt welke woordafbreker en stemmer worden gebruikt bij het indexeren van de kolom. Voor meer informatie, zie Woordonderbrekers en stemmers configureren en beheren voor zoeken (SQL Server). |
SQL Server 2012 (11.x) installeert een nieuwe versie van de woordonderbrekers en stemmers voor Amerikaans Engels (LCID 1033) en Brits Engels (LCID 2057). U kunt echter overschakelen naar de vorige versie van deze onderdelen als u het vorige gedrag wilt behouden. Zie De word-breaker wijzigen die wordt gebruikt voor Amerikaans Engels en Brits Engels voor meer informatie.
Full-Text verwerking van zoekopdrachten
Zoeken in volledige tekst wordt mogelijk gemaakt door de Full-Text Engine. De Full-Text Engine heeft twee rollen: indexeringsondersteuning en queryondersteuning.
indexeringsproces Full-Text
Wanneer een volledige tekstpopulatie (ook wel een verkenning genoemd) wordt geïnitieerd, pusht de Full-Text Engine grote hoeveelheden gegevens naar het geheugen en stuurt de filter-daemonhost een bericht. De host filtert en splitst de gegevens in woorden en zet de geconverteerde gegevens om in omgekeerde woordlijsten. De zoekopdracht in volledige tekst haalt vervolgens de geconverteerde gegevens op uit de woordenlijsten, verwerkt de gegevens om stopwoorden te verwijderen en bewaart de woordlijsten voor een batch in een of meer omgekeerde indexen.
Bij het indexeren van gegevens die zijn opgeslagen in een varbinary(max) of afbeeldingskolom , wordt met het filter, waarmee de IFilter interface wordt geïmplementeerd, tekst geëxtraheerd op basis van de opgegeven bestandsindeling voor die gegevens (bijvoorbeeld Microsoft Word). In sommige gevallen moeten de filteronderdelen de varbinary(max)- of afbeeldingsgegevens naar de filterdata map worden weggeschreven in plaats van naar het geheugen te worden gepusht.
Als onderdeel van de verwerking worden de verzamelde tekstgegevens doorgegeven via een woordonderbreker om de tekst te scheiden in afzonderlijke tokens of trefwoorden. De taal die wordt gebruikt voor tokenisatie wordt opgegeven op kolomniveau of kan worden geïdentificeerd in varbinary(max), afbeeldings- of XML-gegevens door het filteronderdeel.
Er kan extra verwerking worden uitgevoerd om stopwoorden te verwijderen en tokens te normaliseren voordat ze worden opgeslagen in de index in volledige tekst of een indexfragment.
Wanneer een populatie is voltooid, wordt een definitief samenvoegproces geactiveerd dat de indexfragmenten samenvoegt in één hoofdindex voor volledige tekst. Dit resulteert in verbeterde queryprestaties, omdat alleen de hoofdindex moet worden opgevraagd in plaats van meerdere indexfragmenten, en betere scorestatistieken kunnen worden gebruikt voor relevantieclassificatie.
Full-Text queryverwerking
De queryprocessor geeft de volledige tekstgedeelten van een query door aan de Full-Text Engine voor verwerking. De Full-Text Engine voert woordafbreking en, optioneel, synoniemenlijstuitbreidingen, stemming en stopwoordverwerking (ruiswoorden) uit. Vervolgens worden de volledige tekstgedeelten van de query weergegeven in de vorm van SQL-operators, voornamelijk als STVF's (Streaming Table Valued Functions). Tijdens het uitvoeren van query's hebben deze STVF's toegang tot de omgekeerde index om de juiste resultaten op te halen. De resultaten worden op dit moment naar de client geretourneerd of worden verder verwerkt voordat ze worden geretourneerd naar de client.
Architectuur voor volledige tekstindex
De informatie in indexen in volledige tekst wordt door de Full-Text Engine gebruikt om query's voor volledige tekst te compileren waarmee snel in een tabel naar bepaalde woorden of combinaties van woorden kan worden gezocht. In een index in volledige tekst wordt informatie opgeslagen over belangrijke woorden en de locatie ervan in een of meer kolommen van een databasetabel. Een index in volledige tekst is een speciaal type functionele index op basis van tokens die wordt gebouwd en onderhouden door de Full-Text Engine voor SQL Server. Het proces van het bouwen van een volledige-tekstindex verschilt van het bouwen van andere typen indexen. In plaats van een B-structuur te maken op basis van een waarde die is opgeslagen in een bepaalde rij, bouwt de Full-Text Engine een omgekeerde, gestapelde, gecomprimeerde indexstructuur op basis van afzonderlijke tokens uit de tekst die wordt geïndexeerd. De grootte van een volledige-tekstindex wordt alleen beperkt door de beschikbare geheugenbronnen van de computer waarop het exemplaar van SQL Server wordt uitgevoerd.
Vanaf SQL Server 2008 (10.0.x) worden de volledige-tekstindexen geïntegreerd met de Database Engine, in plaats van in het bestandssysteem te blijven staan zoals in eerdere versies van SQL Server. Voor een nieuwe database is de catalogus met volledige tekst nu een virtueel object dat geen deel uitmaakt van een bestandsgroep; het is slechts een logisch concept dat verwijst naar een groep volledige-tekstindexen. Houd er echter rekening mee dat tijdens de upgrade van een SQL Server 2005-database (9.x) elke volledige tekstcatalogus met gegevensbestanden een nieuwe bestandsgroep wordt gemaakt; Zie Upgrade Full-Text Search voor meer informatie.
Er is slechts één volledige-tekstindex per tabel toegestaan. Als u een volledige-tekstindex wilt maken in een tabel, moet de tabel één unieke niet-null-kolom hebben. U kunt een volledige-tekstindex maken voor kolommen van het type char, varchar, nchar, nvarchar, tekst, ntext, afbeelding, xml, varbinary en varbinary(max) kunnen worden geïndexeerd voor zoekopdrachten in volledige tekst. Als u een volledige-tekstindex maakt voor een kolom waarvan het gegevenstype varbinary, varbinary(max), afbeelding of XML is, moet u een typekolom opgeven. Een typekolom is een tabelkolom waarin u de bestandsextensie (.doc, .pdf.xlsenzovoort) van het document in elke rij opslaat.
Indexstructuur voor volledige tekst
Een goed begrip van de structuur van een index in volledige tekst helpt u te begrijpen hoe de Full-Text Engine werkt. In dit artikel wordt het volgende fragment van de Document tabel gebruikt als AdventureWorks2022 voorbeeldtabel. In dit fragment ziet u slechts twee kolommen, de DocumentID kolom en de Title kolom en drie rijen uit de tabel.
In dit voorbeeld wordt ervan uitgegaan dat er een volledige-tekstindex is gemaakt in de Title kolom.
| DocumentID | Titel |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
De volgende tabel, waarin Fragment 1 wordt weergegeven, geeft bijvoorbeeld de inhoud weer van de volledige-tekstindex die is gemaakt op de Title kolom van de Document tabel. Indexen in volledige tekst bevatten meer informatie dan in deze tabel wordt weergegeven. De tabel is een logische weergave van een volledige-tekstindex en is alleen beschikbaar voor demonstratiedoeleinden. De rijen worden opgeslagen in een gecomprimeerde indeling om het schijfgebruik te optimaliseren.
De gegevens worden omgekeerd van de oorspronkelijke documenten. Inversie treedt op omdat de trefwoorden zijn toegewezen aan de document-ID's. Daarom wordt een index in volledige tekst vaak een omgekeerde index genoemd.
U ziet ook dat het trefwoord and wordt verwijderd uit de volledige-tekstindex. Dit wordt gedaan omdat and het een stopwoord is en het verwijderen van stopwoorden uit een index in volledige tekst kan leiden tot aanzienlijke besparingen in schijfruimte, waardoor de queryprestaties worden verbeterd. Voor meer informatie over stopwoorden, zie Stopwords en Stoplists configureren en beheren voor Full-Text Zoeken.
Fragment 1
| Trefwoord | ColId | DocId | Gebeurtenis |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
De Keyword kolom bevat een weergave van één token dat tijdens het indexeren is geëxtraheerd. Woordonderbrekers bepalen wat een token vormt.
De ColId kolom bevat een waarde die overeenkomt met een bepaalde kolom die is geïndexeerd in volledige tekst.
De DocId kolom bevat waarden voor een geheel getal van 8 bytes dat wordt toegewezen aan een bepaalde sleutelwaarde voor volledige tekst in een geïndexeerde tabel met volledige tekst. Deze toewijzing is nodig wanneer de sleutel voor volledige tekst geen gegevenstype geheel getal is. In dergelijke gevallen worden toewijzingen tussen sleutelwaarden in volledige tekst en DocId waarden bijgehouden in een afzonderlijke tabel met de naam van de DocId Mapping tabel. Om een query uit te voeren op deze toewijzingen, gebruikt u de systeemeigen opgeslagen procedure sp_fulltext_keymappings. Als u aan een zoekvoorwaarde wilt voldoen, DocId moeten waarden uit de vorige tabel worden gekoppeld aan de DocId toewijzingstabel om rijen op te halen uit de basistabel waarop een query wordt uitgevoerd. Als de sleutelwaarde voor volledige tekst van de basistabel een geheel getal is, fungeert de waarde rechtstreeks als de DocId waarde en is er geen toewijzing nodig. Het gebruik van sleutelwaarden voor volledige tekst kan daarom helpen bij het optimaliseren van query's met volledige tekst.
De Occurrence kolom bevat een geheel getal. Voor elke DocId-waarde is er een lijst met voorkomens-waarden die overeenkomen met de relatieve woordverschuivingen van het specifieke trefwoord in die specifieke DocId. Voorkomenswaarden zijn handig bij het vaststellen van woordgroepen of nabijheidsovereenkomsten, bijvoorbeeld dat zinnen numeriek aangrenzende voorkomenswaarden hebben. Ze zijn ook nuttig bij het berekenen van relevantiescores; Het aantal exemplaren van een trefwoord in een DocId kan bijvoorbeeld worden gebruikt bij het scoren.
Indexfragmenten in volledige tekst
De logische index voor volledige tekst wordt meestal verdeeld over meerdere interne tabellen. Elke interne tabel wordt een indexfragment met volledige tekst genoemd. Sommige van deze fragmenten bevatten mogelijk nieuwere gegevens dan andere. Als een gebruiker bijvoorbeeld de volgende rij bijwerkt waarvan DocId 3 is en de tabel automatisch wordt gewijzigd, wordt er een nieuw fragment gemaakt.
| DocumentID | Titel |
|---|---|
3 |
Rear Reflector |
In het volgende voorbeeld, waarin Fragment 2 wordt weergegeven, bevat het fragment nieuwere gegevens over DocId 3 in vergelijking met Fragment 1. Daarom, wanneer de gebruiker een query uitvoert voor Rear Reflector, worden de gegevens van Fragment 2 gebruikt voor DocId 3. Elk fragment wordt gemarkeerd met een tijdstempel voor het maken die kan worden opgevraagd met behulp van de sys.fulltext_index_fragments catalogusweergave.
Fragment 2
| Trefwoord | ColId | DocId | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Zoals u kunt zien in Fragment 2, moeten query's in volledige tekst elk fragment intern opvragen en oudere vermeldingen verwijderen. Daarom kunnen te veel volledige-tekstindexfragmenten in de index voor volledige tekst leiden tot aanzienlijke afname van de queryprestaties. Als u het aantal fragmenten wilt verminderen, kunt u de catalogus met volledige tekst opnieuw ordenen met behulp van de REORGANIZE optie ALTER FULLTEXT CATALOGTransact-SQL instructie. Met deze instructie wordt een hoofdsamenvoeging uitgevoerd, waarmee de fragmenten worden samengevoegd in één groter fragment en alle verouderde vermeldingen uit de volledige-tekstindex worden verwijderd.
Nadat de voorbeeldindex opnieuw is geordend, bevat deze de volgende rijen:
| Trefwoord | ColId | DocId | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Verschillen tussen indexen in volledige tekst en reguliere SQL Server-indexen
| Indexen voor volledige tekst | Reguliere SQL Server-indexen |
|---|---|
| Er is slechts één volledige tekstindex toegestaan per tabel. | Verschillende reguliere indexen zijn toegestaan per tabel. |
| De toevoeging van gegevens aan indexen in volledige tekst, een populatie genoemd, kan worden aangevraagd via een planning of een specifieke aanvraag, of kan automatisch worden uitgevoerd met het toevoegen van nieuwe gegevens. | Automatisch bijgewerkt wanneer de gegevens waarop ze zijn gebaseerd, worden ingevoegd, bijgewerkt of verwijderd. |
| Gegroepeerd in dezelfde database in een of meer volledige tekstcatalogussen. | Niet gegroepeerd. |
Full-Text taalkundige componenten en taalondersteuning zoeken
Zoeken in volledige tekst ondersteunt bijna 50 verschillende talen, zoals Engels, Spaans, Chinees, Japans, Arabisch, Bangla en Hindi. Zie sys.fulltext_languages voor een volledige lijst met ondersteunde talen voor volledige tekst. Elk van de kolommen in de volledige-tekstindex is gekoppeld aan een LCID (Microsoft Windows Locale Identifier) die gelijk is aan een taal die wordt ondersteund door zoeken in volledige tekst. LCID 1033 is bijvoorbeeld gelijk aan Amerikaans Engels en LCID 2057 is gelijk aan Brits Engels. Voor elke ondersteunde taal voor volledige tekst biedt SQL Server taalkundige onderdelen die ondersteuning bieden voor het indexeren en opvragen van gegevens in volledige tekst die in die taal zijn opgeslagen.
Taalspecifieke onderdelen bevatten de volgende items:
| Onderdeel | Beschrijving |
|---|---|
| Woordonderbrekers en stemmers | Een woordonderbreker vindt woordgrenzen op basis van de lexicale regels van een bepaalde taal (woordonderbreking). Elke woordonderbreker is gekoppeld aan een stemmer die werkwoorden voor dezelfde taal samenvoegt. Voor meer informatie, zie Woordonderbrekers en stemmers configureren en beheren voor zoeken (SQL Server). |
| Stoplijsten | Er wordt een systeemstoplijst geleverd, die een basisset stopwoorden bevat (ook wel ruiswoorden genoemd). Een stopwoord is een woord dat de zoekopdracht niet helpt en wordt genegeerd door query's in volledige tekst. Bijvoorbeeld, voor de Engelse landinstellingen worden woorden zoals a, and, is, en the beschouwd als stopwoorden. Normaal gesproken moet u een of meer synoniemenlijstbestanden en stoplijsten configureren. Voor meer informatie, zie Stopwords en Stoplists configureren en beheren voor Full-Text zoeken. |
| Synoniemenlijstbestanden | SQL Server installeert ook een synoniemenlijstbestand voor elke volledige teksttaal en een globaal synoniemenlijstbestand. De geïnstalleerde synoniemenlijstbestanden zijn leeg, maar u kunt ze bewerken om synoniemen te definiëren voor een specifieke taal of zakelijk scenario. Door een synoniemenlijst te ontwikkelen die is afgestemd op uw gegevens in volledige tekst, kunt u het bereik van query's op volledige tekst op die gegevens effectief uitbreiden. Zie Synoniemenlijstbestanden configureren en beheren voor Full-Text Zoeken voor meer informatie. |
| Filters (iFilters) | Voor het indexeren van een document in een kolom varbinary(max), afbeelding of XML-gegevenstype is een filter vereist om extra verwerking uit te voeren. Het filter moet specifiek zijn voor het documenttype (.doc, .pdf.xls, enzovoort.xml). Zie Filters configureren en beheren voor zoeken voor meer informatie. |
Woordonderbrekers (en stemmers) en filters worden uitgevoerd in het filterdaemon-hostproces (fdhost.exe).