Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
van toepassing op:![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) is een van de belangrijkste T-SQL-functies die beschikbaar zijn. Het is een volledig geparallelliseerde operatie die een nieuwe tabel aanmaakt op basis van de output van een SELECT-instructie. CTAS is de eenvoudigste en snelste manier om een kopie van een tabel te maken.
Gebruik bijvoorbeeld CTAS om:
- Maak een tabel opnieuw aan met een andere hashverdelingskolom.
- Maak een tabel opnieuw aan zoals gerepliceerd.
- Maak een columnstore-index aan op slechts enkele kolommen in de tabel.
- Zoek externe data op of importeer deze zelf.
Opmerking
Omdat CREATE TABLE AS SELECT (CTAS) de mogelijkheden van het maken van een tabel uitbreidt, probeert dit onderwerp het CREATE TABLE onderwerp niet te herhalen. In plaats daarvan beschrijft het de verschillen tussen de CTAS en CREATE TABLE.
- CTAS wordt ondersteund in het Warehouse in Microsoft Fabric. Bekijk de Fabric-versie van het artikel MAAK TABEL ALS SELECT.
- Deze syntaxis wordt niet ondersteund door een serverloze SQL-pool in Azure Synapse Analytics.
-
CREATE TABLE AS SELECT(CTAS) wordt ondersteund in het Warehouse in Microsoft Fabric. Voor meer informatie, zie de Fabric Data Warehouse-versie van dit artikel.
![]() Transact-SQL syntaxis-conventies
Transact-SQL syntaxis-conventies
Syntaxis
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Arguments
Voor meer informatie, zie de sectie Argumenten in CREATE TABLE.
Kolomopties
column_name [ ,...n ]
Kolomnamen staan de kolomopties AANMAKEN niet toe zoals genoemd in CREATE TABLE. In plaats daarvan kunt u een optionele lijst opgeven met een of meer kolomnamen voor de nieuwe tabel. De kolommen in de nieuwe tabel gebruiken de namen die u opgeeft. Wanneer u kolomnamen opgeeft, moet het aantal kolommen in de kolomlijst overeenkomen met het aantal kolommen in de selectieresultaten. Als u geen kolomnamen opgeeft, worden in de nieuwe doeltabel de kolomnamen in de resultaten van de select-instructie gebruikt.
U kunt geen andere kolomopties opgeven, zoals gegevenstypen, sortering of null-uitvoerbaarheid. Elk van deze attributen is afgeleid van de resultaten van de SELECT uitspraak. U kunt echter de SELECT-instructie gebruiken om de kenmerken te wijzigen. Zie bijvoorbeeld Gebruik CTAS om kolomattributen te wijzigen.
Opties voor tabelverdeling
Voor details en om te begrijpen hoe je de kolom met de beste verdeling kiest, zie de sectie Tabel distributieopties in CREATE TABLE. Voor aanbevelingen over welke distributie te kiezen voor een tabel op basis van daadwerkelijk gebruik of voorbeeldzoeken, zie Distribution Advisor in Azure Synapse SQL.
DISTRIBUTION
=
HASH (distribution_column_name) | ROUND_ROBIN | NABOOTSEN
De CTAS-verklaring vereist een distributieoptie en bevat geen standaardwaarden. Dit is anders dan CREATE TABLE, dat standaardinstellingen heeft.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
Verdeelt de rijen op basis van de hashwaarden van maximaal acht kolommen, waardoor de basisgegevens gelijkmatiger kunnen worden verdeeld, de datascheef in de tijd wordt verminderd en de queryprestaties verbeteren.
Opmerking
- Om de functie in te schakelen, verander je het compatibiliteitsniveau van de database naar 50 met dit commando. Voor meer informatie over het instellen van het databasecompatibiliteitsniveau, zie ALTER DATABASE SCOPED CONFIGURATION. Bijvoorbeeld:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Om de multi-kolomdistributie (MCD) functie uit te schakelen, voer je dit commando uit om het compatibiliteitsniveau van de database te veranderen naar AUTO. Bijvoorbeeld:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;bestaande MCD-tabellen blijven maar worden onleesbaar. Queries over MCD-tabellen geven deze foutmelding terug:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Om weer toegang te krijgen tot MCD-tabellen, schakel de functie opnieuw in.
- Om data in een MCD-tabel te laden, gebruik je de CTAS-instructie en de databron moet Synapse SQL-tabellen zijn.
- CTAS op MCD HEAP-doeltabellen wordt niet ondersteund. Gebruik in plaats daarvan INSERT SELECT als oplossing om data te laden in MCD HEAP-tabellen.
- Het gebruik van SSMS voor het genereren van een script om MCD-tabellen te maken wordt momenteel ondersteund na SSMS versie 19.
Voor details en om te begrijpen hoe je de kolom met de beste verdeling kiest, zie de sectie Tabel distributieopties in CREATE TABLE.
Voor aanbevelingen over de beste distributie om te gebruiken op basis van je workloads, zie de Synapse SQL Distribution Advisor (Preview).
Opties voor tabelpartitities
De CTAS-instructie maakt standaard een niet-gepartitioneerde tabel aan, zelfs als de brontabel gepartitioneerd is. Om een gepartitioneerde tabel met de CTAS-instructie te maken, moet je de partitieoptie specificeren.
Voor details, zie de sectie Table-partitieopties in CREATE TABLE.
SELECT-instructie
De SELECT-instructie is het fundamentele verschil tussen CTAS en CREATE TABLE.
WITH
common_table_expression
Hiermee geeft u een tijdelijke benoemde resultatenset op, ook wel een algemene tabelexpressie (CTE) genoemd. Zie WITH common_table_expression (Transact-SQL)voor meer informatie.
SELECT
select_criteria
Hiermee wordt de nieuwe tabel gevuld met de resultaten van een SELECT-instructie. select_criteria is de hoofdtekst van de SELECT-instructie waarmee wordt bepaald welke gegevens naar de nieuwe tabel moeten worden gekopieerd. Zie SELECT (Transact-SQL)voor meer informatie over SELECT-instructies.
Zoektip
Gebruikers kunnen MAXDOP instellen op een geheel getal om de maximale mate van parallelisme te regelen. Wanneer MAXDOP op 1 is gezet, wordt de query uitgevoerd door één enkele thread.
Permissions
CTAS vereist SELECT toestemming voor alle objecten waarnaar in de select_criteria wordt verwezen.
Voor permissies om een tabel aan te maken, zie Rechten in CREATE TABLE.
Opmerkingen
Voor details, zie Algemene Opmerkingen in CREATE TABLE.
Beperkingen en beperkingen
Voor meer details over beperkingen en beperkingen, zie Beperkingen en Beperkingen in CREATE TABLE.
Een geordende geclusterde columnstore-index kan worden aangemaakt op kolommen van alle datatypes die in Azure Synapse Analytics worden ondersteund, behalve voor stringkolommen.
SET ROWCOUNT (Transact-SQL) heeft geen effect op CTAS. Gebruik TOP (Transact-SQL)om een vergelijkbaar gedrag te bereiken.
CTAS ondersteunt de
OPENJSONfunctie niet als onderdeel van deSELECTverklaring. Gebruik als alternatiefINSERT INTO ... SELECT. Voorbeeld:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Vergrendelingsgedrag
Voor details, zie Locking Behavior in CREATE TABLE.
Performance
Voor een hash-gedistribueerde tabel kun je CTAS gebruiken om een andere distributiekolom te kiezen voor betere prestaties voor joins en aggregaties. Als het kiezen van een andere distributiekolom niet je doel is, heb je de beste CTAS-prestaties als je dezelfde distributiekolom specificeert, omdat dit voorkomt dat de rijen opnieuw worden verdeld.
Als je CTAS gebruikt om een tabel te maken en prestaties geen factor zijn, kun je specificeren ROUND_ROBIN om te voorkomen dat je een verdelingskolom hoeft te kiezen.
Om gegevensbeweging in latere queries te voorkomen, kun je tegen de kosten van meer opslag specificeren REPLICATE dat je een volledige kopie van de tabel op elke Compute-node laadt.
Voorbeelden voor het kopiëren van een tabel
Eén. Gebruik CTAS om een tabel te kopiëren
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Misschien is een van de meest voorkomende toepassingen CTAS het maken van een kopie van een tabel zodat je de DDL kunt wijzigen. Als je bijvoorbeeld oorspronkelijk je tabel hebt aangemaakt en ROUND_ROBIN deze nu wilt veranderen in een tabel die op een kolom is verdeeld, CTAS is dat hoe je de verdelingskolom zou aanpassen.
CTAS kan ook worden gebruikt om partitieren, indexering of kolomtypes te wijzigen.
Stel dat je deze tabel hebt gemaakt door het standaardverdelingstype van HEAPte specificeren ROUND_ROBIN en te gebruiken.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Nu wil je een nieuwe kopie van deze tabel maken met een geclusterde columnstore-index, zodat je kunt profiteren van de prestaties van geclusterde columnstore-tabellen. Je wilt deze tabel ook verdelen op ProductKey omdat je joins op deze kolom verwacht en databeweging tijdens joins op ProductKeywilt vermijden. Tot slot wil je ook partitionering toevoegen OrderDateKey zodat je snel oude data kunt verwijderen door oude partities te verwijderen. Hier is de CTAS-instructie die je oude tabel naar een nieuwe tabel zou kopiëren:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Tot slot kun je je tabellen hernoemen om je nieuwe tabel te vervangen en dan je oude tabel laten vallen.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Voorbeelden van kolomopties
B. Gebruik CTAS om kolomattributen te wijzigen
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Dit voorbeeld gebruikt CTAS om datatypes, nullability en collaging voor meerdere kolommen in de DimCustomer2 tabel te wijzigen.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
Als laatste stap kun je RENAME (Transact-SQL) gebruiken om de tabelnamen te wisselen. Dit maakt DimCustomer2 de nieuwe tafel.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Voorbeelden voor tabelverdeling
C. Gebruik CTAS om de distributiemethode voor een tabel te wijzigen
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Dit eenvoudige voorbeeld laat zien hoe je de distributiemethode voor een tabel kunt wijzigen. Om de mechaniek te laten zien hoe dit gebeurt, verandert het een hash-distributed table in round-robin en vervolgens de round-robin-tabel terug naar hash-distribusied. De eindtabel komt overeen met de originele tafel.
In de meeste gevallen hoef je een hash-distributed table niet te veranderen in een round-robin table. Vaker moet je een round-robin-tabel vervangen door een hash-gedistribueerde tabel. Je kunt bijvoorbeeld aanvankelijk een nieuwe tabel als round-robin laden en deze later verplaatsen naar een hash-gedistribueerde tabel om betere joinprestaties te krijgen.
Dit voorbeeld gebruikt de voorbeelddatabase van AdventureWorksDW. Om de Azure Synapse Analytics-versie te laden, zie Quickstart: Create and query a dedicated SQL pool (voorheen SQL DW) in Azure Synapse Analytics met behulp van het Azure-portaal.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Verander het vervolgens weer terug naar een hash-gedistribueerde tabel.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Gebruik CTAS om een tabel om te zetten naar een gerepliceerde tabel
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Dit voorbeeld geldt voor het omzetten van round-robin of hash-distributed tabellen naar een gerepliceerde tabel. Dit specifieke voorbeeld brengt de vorige methode van het veranderen van het verdelingstype nog een stap verder. Omdat DimSalesTerritory het een dimensie is en waarschijnlijk een kleinere tabel, kun je ervoor kiezen de tabel opnieuw te maken als gerepliceerd om databeweging te voorkomen bij het joinen met andere tabellen.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Gebruik CTAS om een tabel met minder kolommen te maken
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Het volgende voorbeeld creëert een round-robin gedistribueerde tabel genaamd myTable (c, ln). De nieuwe tabel heeft slechts twee kolommen. Het gebruikt de kolomaliasen in de SELECT-instructie voor de namen van de kolommen.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Voorbeelden van query hints
F. Gebruik een queryhint met CREATE TABLE AS SELECT (CTAS)
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Deze query toont de basissyntaxis voor het gebruik van een query join hint met de CTAS-instructie. Nadat de query is ingediend, past Azure Synapse Analytics de hash join-strategie toe wanneer het het queryplan voor elke individuele distributie genereert. Voor meer informatie over de hash join query hint, zie OPTION Clause (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Voorbeelden voor externe tabellen
G. Gebruik CTAS om data te importeren uit Azure Blob Storage
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Om gegevens te importeren uit een externe tabel, gebruik je CREATE TABLE AS SELECT om uit de externe tabel te selecteren. De syntaxis om gegevens uit een externe tabel te selecteren in Azure Synapse Analytics is hetzelfde als de syntaxis voor het selecteren van gegevens uit een gewone tabel.
Het volgende voorbeeld definieert een externe tabel op data in een Azure Blob Storage-account. Vervolgens gebruikt het CREATE TABLE AS SELECT om uit de externe tabel te kiezen. Dit importeert de gegevens uit Azure Blob Storage tekstgescheiden bestanden en slaat de gegevens op in een nieuwe Azure Synapse Analytics-tabel.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Gebruik CTAS om Hadoop-gegevens te importeren van een externe tabel
Van toepassing op: Analytics Platform System (PDW)
Om gegevens uit een externe tabel te importeren, gebruik je simpelweg CREATE TABLE AS SELECT om uit de externe tabel te selecteren. De syntaxis om gegevens uit een externe tabel te selecteren in het Analytics Platform System (PDW) is hetzelfde als de syntaxis voor het selecteren van gegevens uit een gewone tabel.
Het volgende voorbeeld definieert een externe tabel op een Hadoop-cluster. Vervolgens gebruikt het CREATE TABLE AS SELECT om uit de externe tabel te kiezen. Dit importeert de gegevens uit Hadoop-tekstgescheiden bestanden en slaat de gegevens op in een nieuwe Analytics Platform System (PDW)-tabel.
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Voorbeelden die CTAS gebruiken ter vervanging van SQL Server-code
Gebruik CTAS om enkele niet-ondersteunde functies te omzeilen. Naast het kunnen draaien van je code op het datawarehouse, zal het herschrijven van bestaande code om CTAS te gebruiken meestal de prestaties verbeteren. Dit is het resultaat van het volledig parallelle ontwerp.
Opmerking
Probeer te denken "eerst CTAS". Als je denkt dat je een probleem kunt oplossen met CTAS behulp van een probleem, is dat meestal de beste aanpak – zelfs als je daardoor meer data schrijft.
I. Gebruik CTAS in plaats van SELECT.. IN
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
SQL Server-code gebruikt doorgaans SELECT.. INTO om een tabel te vullen met de resultaten van een SELECT-instructie. Dit is een voorbeeld van een SQL Server SELECT.. IN-verklaring.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Deze syntax wordt niet ondersteund in Azure Synapse Analytics en Parallel Data Warehouse. Dit voorbeeld laat zien hoe je de vorige SELECT herschrijft.. INTO-verklaring als een CTAS-verklaring. Je kunt kiezen uit een van de DISTRIBUTIE-opties die in de CTAS-syntaxis worden beschreven. Dit voorbeeld gebruikt de ROUND_ROBIN distributiemethode.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Gebruik CTAS om merge statements te vereenvoudigen
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Merge-instructies kunnen, althans gedeeltelijk, worden vervangen door gebruik te maken CTASvan . Je kunt de en INSERT de UPDATE samenvoegen tot één verklaring. Alle verwijderde records moeten in een tweede statement worden afgesloten.
Een voorbeeld van een UPSERT volgt:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. Expliciet het type toestandsdata en de nulbaarheid van de output
Van toepassing op: Azure Synapse Analytics and Analytics Platform System (PDW)
Bij het migreren van SQL Server-code naar Azure Synapse Analytics kun je dit soort codeerpatroon tegenkomen:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Instinctief denk je misschien dat je deze code naar een CTAS moet migreren en dat klopt. Er is echter een verborgen probleem.
De volgende code levert NIET hetzelfde resultaat op:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Let op dat de kolom "resultaat" het datatype en de nullability-waarden van de expressie overdraagt. Dit kan leiden tot subtiele variaties in waarden als je niet voorzichtig bent.
Probeer het volgende als voorbeeld:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
De waarde die voor het resultaat wordt opgeslagen is anders. Naarmate de behouden waarde in de resultaatkolom in andere expressies wordt gebruikt, wordt de fout nog belangrijker.
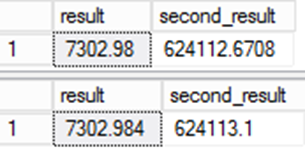
Dit is belangrijk voor datamigraties. Hoewel de tweede vraag misschien nauwkeuriger is, is er een probleem. De data zou anders zijn dan het bronsysteem en dat leidt tot vragen over integriteit in de migratie. Dit is een van die zeldzame gevallen waarin het "verkeerde" antwoord eigenlijk het juiste is!
De reden dat we dit verschil tussen de twee resultaten zien, is te wijten aan impliciete typecasting. In het eerste voorbeeld definieert de tabel de kolomdefinitie. Wanneer de rij wordt ingevoegd, vindt er een impliciete typeconversie plaats. In het tweede voorbeeld is er geen impliciete typeconversie, omdat de expressie het datatype van de kolom definieert. Let ook op dat de kolom in het tweede voorbeeld is gedefinieerd als een NULLable kolom, terwijl dat in het eerste voorbeeld niet zo is. Toen de tabel in het eerste voorbeeld werd aangemaakt, was kolom expliciet gedefinieerd als nullabiliteit. In het tweede voorbeeld werd het aan de uitdrukking overgelaten en standaard resulteerde dit in een NULL definitie.
Om deze problemen op te lossen, moet je expliciet de typeconversie en nullability instellen in het SELECT deel van de CTAS stelling. Je kunt deze eigenschappen niet instellen in het deel 'maak een tabel'.
Dit voorbeeld laat zien hoe je de code kunt repareren:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Let op het volgende in het voorbeeld:
- CAST of CONVERT had gebruikt kunnen worden.
- ISNULL wordt gebruikt om NULLability af te dwingen, niet COALESCE.
- ISNULL is de buitenste functie.
- Het tweede deel van de ISNULL is een constante,
0.
Opmerking
Om de nullability correct in te stellen is het essentieel om te gebruiken ISNULL en niet COALESCE.
COALESCE geen deterministische functie is en dus zal het resultaat van de uitdrukking altijd NULLable zijn.
ISNULL is anders. Het is deterministisch. Daarom, wanneer het tweede deel van de ISNULL functie een constante of een literaal is, zal de resulterende waarde NIET NULL zijn.
Deze tip is niet alleen nuttig om de integriteit van je berekeningen te waarborgen. Het is ook belangrijk voor het wisselen van tabelpartities. Stel je voor dat je deze tabel hebt gedefinieerd als je feit:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Het waardeveld is echter een berekende expressie, het maakt geen deel uit van de brongegevens.
Om uw gepartitioneerde dataset te maken, overweegt u het volgende voorbeeld:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
De query zou prima draaien. Het probleem ontstaat wanneer je probeert de partitiewissel uit te voeren. De tabeldefinities komen niet overeen. Om de tabeldefinities te maken, moet de CTAS worden aangepast.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Je ziet dus dat typeconsistentie en het behouden van nullability-eigenschappen op een CTAS een goede technische best practice is. Het helpt om integriteit in je berekeningen te behouden en zorgt er ook voor dat partitiewisseling mogelijk is.
L. Maak een geordende geclusterde kolomopslagindex aan met MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Verwante inhoud
- MAAK EXTERNE DATABRON AAN (Transact-SQL)
- MAAK EEN EXTERN BESTANDSFORMAAT AAN (Transact-SQL)
- CREËER EXTERNE TABEL (Transact-SQL)
- MAAK EXTERNE TABEL AAN ALS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP-TABEL (Transact-SQL)
- LAAT EXTERNE TAFEL VALLEN (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- EXTERNE TABEL WIJZIGEN (Transact-SQL)
van toepassing op:![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) is een van de belangrijkste T-SQL-functies die beschikbaar zijn. Het is een volledig geparallelliseerde operatie die een nieuwe tabel aanmaakt op basis van de output van een SELECT-instructie. CTAS is de eenvoudigste en snelste manier om een kopie van een tabel te maken.
Gebruik bijvoorbeeld CTAS in Warehouse in Microsoft Fabric om:
- Maak een kopie van een tabel met enkele kolommen van de brontabel.
- Maak een tabel aan die het resultaat is van een query die andere tabellen joint.
Voor meer informatie over het gebruik van CTAS op uw Warehouse in Microsoft Fabric, zie Invoer data in uw Warehouse met Transact-SQL.
Opmerking
Omdat CREATE TABLE AS SELECT (CTAS) de mogelijkheden van het maken van een tabel uitbreidt, probeert dit onderwerp het onderwerp CREATE TABLE niet te herhalen. In plaats daarvan beschrijft het de verschillen tussen de CTAS en CREATE TABLE.
![]() Transact-SQL syntaxis-conventies
Transact-SQL syntaxis-conventies
Syntaxis
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
) WITH (CLUSTER BY [ ,... n ])
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Arguments
Voor details over veelvoorkomende argumenten, zie de argumenten in CREATE TABLE for Microsoft Fabric.
MET (CLUSTER DOOR [ ,... n])
De CLUSTER BY clausule voor dataclustering in Fabric Data Warehouse vereist dat er minstens één kolom wordt gespecificeerd voor dataclustering, en maximaal vier kolommen.
Voor meer informatie, zie Data clustering in Fabric Data Warehouse.
SELECT-instructie
De SELECT uitspraak is het fundamentele verschil tussen CTAS en CREATE TABLE.
SELECTEER select_criteria
Vult de nieuwe tabel met de resultaten van een SELECT statement.
select_criteria is het lichaam van de SELECT instructie dat bepaalt welke data naar de nieuwe tabel gekopieerd moet worden. Voor informatie over SELECT statements, zie SELECT (Transact-SQL).
Opmerking
In Microsoft Fabric is het gebruik van variabelen in CTAS niet toegestaan.
Permissions
CTAS vereist SELECT toestemming voor alle objecten waarnaar in de select_criteria wordt verwezen.
Voor permissies om een tabel aan te maken, zie Rechten in CREATE TABLE.
Opmerkingen
Voor details, zie Algemene Opmerkingen in CREATE TABLE.
Beperkingen en beperkingen
SET ROWCOUNT (Transact-SQL) heeft geen effect op CTAS. Gebruik TOP (Transact-SQL)om een vergelijkbaar gedrag te bereiken.
Voor details, zie Beperkingen en Beperkingen in CREATE TABLE.
Vergrendelingsgedrag
Voor details, zie Locking Behavior in CREATE TABLE.
Voorbeelden voor het kopiëren van een tabel
Voor meer informatie over het gebruik van CTAS op uw Warehouse in Microsoft Fabric, zie Invoer data in uw Warehouse met Transact-SQL.
Eén. Gebruik CTAS om kolomattributen te wijzigen
Dit voorbeeld gebruikt CTAS om gegevenstypen en nulbaarheid voor meerdere kolommen in de DimCustomer2 tabel te wijzigen.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Gebruik CTAS om een tabel met minder kolommen te maken
Het volgende voorbeeld creëert een tabel genaamd myTable (c, ln). De nieuwe tabel heeft slechts twee kolommen. Het gebruikt de kolomaliasen in de SELECT-instructie voor de namen van de kolommen.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Gebruik CTAS in plaats van SELECT.. IN
SQL Server-code gebruikt doorgaans SELECT.. INTO om een tabel te vullen met de resultaten van een SELECT-instructie. Dit is een voorbeeld van een SQL Server SELECT.. IN-verklaring.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
Dit voorbeeld laat zien hoe je de vorige SELECT herschrijft.. INTO-verklaring als een CTAS-verklaring.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Gebruik CTAS om merge statements te vereenvoudigen
Merge-instructies kunnen, althans gedeeltelijk, worden vervangen door gebruik te maken CTASvan . Je kunt de en INSERT de UPDATE samenvoegen tot één verklaring. Alle verwijderde records moeten in een tweede statement worden afgesloten.
Een voorbeeld van een UPSERT volgt:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
D. Maak een tabel met dataclustering
Gebruik het volgende commando om een nieuwe tabel aan te maken met CREATE TABLE AS SELECT (CTAS) met een gespecificeerde dataclusteringkolom:
CREATE TABLE nyctlc_With_DataClustering
WITH (CLUSTER BY (lpepPickupDatetime))
AS SELECT * FROM nyctlc;
Voor meer informatie, zie Data clustering in Fabric Data Warehouse.