Tekstanalyse begrijpen
Voordat u de mogelijkheden voor tekstanalyse van de Azure AI-taalservice verkent, gaan we enkele algemene principes en algemene technieken onderzoeken die worden gebruikt om tekstanalyses en andere NLP-taken (Natural Language Processing) uit te voeren.
Sommige van de vroegste technieken die worden gebruikt om tekst met computers te analyseren, omvatten statistische analyse van een teksttekst (een corpus) om een soort semantische betekenis af te leiden. Eenvoudig gezegd, als u de meest gebruikte woorden in een bepaald document kunt bepalen, kunt u vaak een goed beeld krijgen van wat het document inhoudt.
Tokenisatie
De eerste stap bij het analyseren van een corpus is het opsplitsen in tokens. Omwille van de eenvoud kunt u elk afzonderlijk woord in de trainingstekst beschouwen als een token, maar in werkelijkheid kunnen tokens worden gegenereerd voor gedeeltelijke woorden of combinaties van woorden en leestekens.
Denk bijvoorbeeld aan deze zin uit een beroemde amerikaanse presidentiële toespraak: 'we kiezen ervoor om naar de maan te gaan'. De woordgroep kan worden opgesplitst in de volgende tokens, met numerieke id's:
- We
- Kies
- to
- go
- het
- Maan
U ziet dat 'to' (tokennummer 3) tweemaal wordt gebruikt in het corpus. De zin 'we kiezen ervoor om naar de maan te gaan' kan worden vertegenwoordigd door de tokens [1,2,3,4,3,5,6].
Notitie
We hebben een eenvoudig voorbeeld gebruikt waarin tokens worden geïdentificeerd voor elk afzonderlijk woord in de tekst. Houd echter rekening met de volgende concepten die van toepassing kunnen zijn op tokenisatie, afhankelijk van het specifieke type NLP-probleem dat u probeert op te lossen:
- Tekstnormalisatie: Voordat u tokens genereert, kunt u ervoor kiezen om de tekst te normaliseren door interpunctie te verwijderen en alle woorden te wijzigen in kleine letters. Voor analyse die uitsluitend afhankelijk is van woordfrequentie, verbetert deze benadering de algehele prestaties. Sommige semantische betekenis kan echter verloren gaan- denk bijvoorbeeld aan de zin "De heer Banks heeft in veel banken gewerkt.". Misschien wilt u dat uw analyse onderscheid maakt tussen de persoon die de heer Banks en de banken waarin hij heeft gewerkt. U kunt ook 'banken' beschouwen als een afzonderlijk token aan 'banken', omdat de opname van een periode de informatie bevat die het woord aan het einde van een zin krijgt
- Stop het verwijderen van woorden. Stopwoorden zijn woorden die moeten worden uitgesloten van de analyse. Als u bijvoorbeeld 'the', 'a' of 'it' gebruikt, is tekst gemakkelijker te lezen, maar voegt u weinig semantische betekenis toe. Door deze woorden uit te sluiten, kan een oplossing voor tekstanalyse de belangrijke woorden beter identificeren.
- n-grammen zijn meervoudige woordgroepen zoals 'Ik heb' of 'hij liep'. Eén woordgroep is een unigram, een woordgroep met twee woorden is een bi-gram, een woordgroep met drie woorden is een trigram, enzovoort. Door woorden als groepen te beschouwen, kan een machine learning-model beter inzicht krijgen in de tekst.
- Stemming is een techniek waarbij algoritmen worden toegepast om woorden samen te voegen voordat ze worden geteld, zodat woorden met dezelfde hoofdmap, zoals 'macht', 'aangedreven' en 'krachtig', worden geïnterpreteerd als hetzelfde token.
Frequentieanalyse
Na het tokeniseren van de woorden kunt u een analyse uitvoeren om het aantal exemplaren van elk token te tellen. De meest gebruikte woorden (behalve stopwoorden zoals "a", "the", enzovoort) kunnen vaak een aanwijzing geven over het hoofdonderwerp van een tekstlichaam. De meest voorkomende woorden in de hele tekst van de spraak 'naar de maan gaan' die we eerder hebben overwogen, zijn bijvoorbeeld 'nieuw', 'go', 'spatie' en 'maan'. Als we de tekst zouden tokeniseren als bi-gram (woordparen), is de meest voorkomende bigram in de spraak 'de maan'. Uit deze informatie kunnen we gemakkelijk zien dat de tekst voornamelijk betrekking heeft op ruimtereizen en naar de maan gaat.
Tip
Eenvoudige frequentieanalyse waarin u gewoon het aantal exemplaren van elk token telt, kan een effectieve manier zijn om één document te analyseren, maar wanneer u onderscheid moet maken tussen meerdere documenten binnen hetzelfde corpus, hebt u een manier nodig om te bepalen welke tokens het meest relevant zijn in elk document. Termfrequentie - inverse documentfrequentie (TF-IDF) is een veelgebruikte techniek waarbij een score wordt berekend op basis van hoe vaak een woord of term in één document wordt weergegeven in vergelijking met de meer algemene frequentie in de hele verzameling documenten. Met deze techniek wordt een hoge mate van relevantie verondersteld voor woorden die vaak voorkomen in een bepaald document, maar relatief zelden in een breed scala aan andere documenten.
Machine learning voor tekstclassificatie
Een andere handige techniek voor tekstanalyse is het gebruik van een classificatiealgoritme, zoals logistieke regressie, om een machine learning-model te trainen dat tekst classificeert op basis van een bekende set categorisaties. Een veelvoorkomende toepassing van deze techniek is het trainen van een model dat tekst classificeert als positief of negatief om sentimentanalyse of meninganalyse uit te voeren.
Denk bijvoorbeeld aan de volgende restaurantbeoordelingen, die al zijn gelabeld als 0 (negatief) of 1 (positief):
- Het eten en de service waren allebei geweldig: 1
- Een echt vreselijke ervaring: 0
- Mmm! lekker eten en een leuke sfeer1:
- Langzame service en ondermaats voedsel: 0
Met voldoende gelabelde beoordelingen kunt u een classificatiemodel trainen met behulp van de tokenized tekst als functies en het gevoel (0 of 1) een label. In het model wordt een relatie tussen tokens en sentiment ingekapseld, bijvoorbeeld beoordelingen met tokens voor woorden zoals 'geweldig', 'smakelijk' of 'leuk' zijn waarschijnlijker om een gevoel van 1 (positief) te retourneren, terwijl beoordelingen met woorden als 'vreselijk', 'langzaam' en 'substandard' waarschijnlijker 0 (negatief) retourneren.
Semantische taalmodellen
Naarmate de stand van de kunst voor NLP is gevorderd, heeft de mogelijkheid om modellen te trainen die de semantische relatie tussen tokens inkapselen, geleid tot de opkomst van krachtige taalmodellen. Het hart van deze modellen is het coderen van taaltokens als vectoren (matrices met meerdere waarden) die insluiten worden genoemd.
Het kan handig zijn om de elementen in een tokeninsluitingsvector als coördinaten in multidimensionale ruimte te beschouwen, zodat elk token een specifieke 'locatie' in beslag neemt. Hoe dichter bij elkaar liggen langs een bepaalde dimensie, hoe semantisch gerelateerder ze zijn. Met andere woorden, gerelateerde woorden worden dichter bij elkaar gegroepeerd. Stel dat de insluitingen voor onze tokens bestaan uit vectoren met drie elementen, bijvoorbeeld:
- 4 ("hond"): [10.3.2]
- 5 ("schors"): [10,2,2]
- 8 ("kat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
We kunnen de locatie van tokens tekenen op basis van deze vectoren in driedimensionale ruimte, zoals deze:
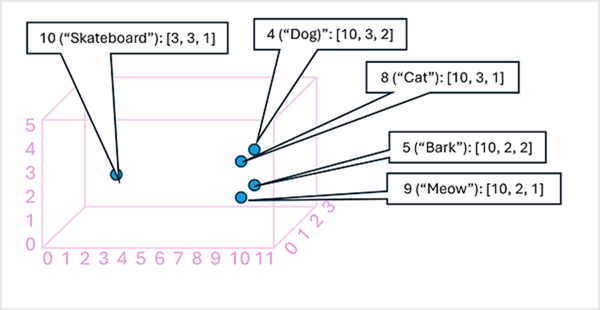
De locaties van de tokens in de ruimte voor insluiten bevatten enkele informatie over hoe dicht de tokens bij elkaar horen. Het token voor 'hond' is bijvoorbeeld dicht bij 'kat' en ook bij 'blaffen'. De tokens voor 'kat' en 'schors' liggen dicht bij 'meow'. Het token voor skateboard ligt verder weg van de andere tokens.
De taalmodellen die we in de industrie gebruiken, zijn gebaseerd op deze principes, maar hebben meer complexiteit. De vectoren die in het algemeen worden gebruikt, hebben bijvoorbeeld veel meer dimensies. Er zijn ook meerdere manieren waarop u de juiste insluitingen voor een bepaalde set tokens kunt berekenen. Verschillende methoden resulteren in verschillende voorspellingen van modellen voor natuurlijke taalverwerking.
In het volgende diagram ziet u een gegeneraliseerde weergave van de meeste moderne oplossingen voor natuurlijke taalverwerking. Een grote verzameling onbewerkte tekst wordt getokeniseerd en gebruikt voor het trainen van taalmodellen, die veel verschillende soorten verwerkingstaken voor natuurlijke taal kunnen ondersteunen.
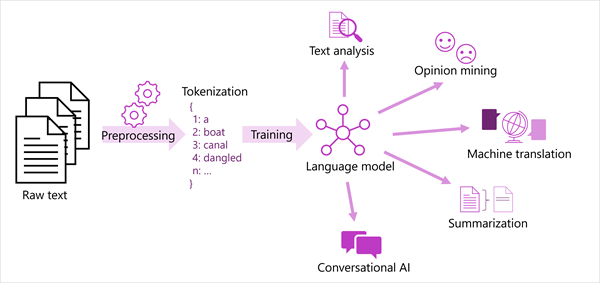
Algemene NLP-taken die door taalmodellen worden ondersteund, zijn onder andere:
- Tekstanalyse, zoals het extraheren van belangrijke termen of het identificeren van benoemde entiteiten in tekst.
- Sentimentanalyse en meninganalyse om tekst als positief of negatief te categoriseren.
- Automatische vertaling, waarin tekst automatisch van de ene taal naar de andere wordt vertaald.
- Samenvatting, waarin de belangrijkste punten van een grote teksttekst worden samengevat.
- Conversationele AI-oplossingen zoals bots of digitale assistenten waarin het taalmodel invoer in natuurlijke taal kan interpreteren en een geschikt antwoord kan retourneren.
Deze mogelijkheden en meer worden ondersteund door de modellen in de Azure AI Language-service, die we hierna gaan verkennen.