Oefening: Azure Data Factory-gegevens wrangling gebruiken
Met de Power Query-functie in Azure Data Factory kunt u werken met en gegevens wrangle. Het is een object dat kan worden toegevoegd aan de canvasontwerper als activiteit in een Azure Data Factory-pijplijn om codevrij gegevensvoorbereiding uit te voeren. Hiermee kunnen personen die niet met de traditionele technologieën voor gegevensvoorbereiding, zoals Spark of SQL Server, en talen zoals Python en T-SQL, gegevens op iteratief op cloudschaal voorbereiden.
De Power Query-functie maakt gebruik van een rastertypeinterface voor basisgegevensvoorbereiding die lijkt op de vormgeving van Excel, ook wel een Online Mashup-editor genoemd. Met de editor kunnen ook geavanceerdere gebruikers complexere gegevensvoorbereiding uitvoeren met behulp van formules. U moet eerst een gekoppelde service maken aan een bron van de gegevens voordat u toegang hebt tot de gegevens
De formules werken met Power Query Online en maken Power Query M-functies beschikbaar voor data factory-gebruikers. Power Query vertaalt vervolgens de M-taal die is gegenereerd door de Online Mashup-editor in spark-code voor het uitvoeren van de cloudschaal.
Met deze mogelijkheid kunnen zowel gegevenstechnici als gegevensanalisten gegevenssets interactief verkennen en voorbereiden. Daarnaast kunnen ze interactief met de M-taal werken en een voorbeeld van het resultaat bekijken voordat ze het bekijken in de context van een bredere pijplijn.
Als u een Power Query-activiteit wilt toevoegen in Azure Data Factory, klikt u op het pluspictogram en selecteert u Power Query in het deelvenster Factory-resources.

Voeg een brongegevensset toe voor uw gegevensstroom en selecteer een sinkgegevensset. De volgende gegevensbronnen worden ondersteund.
| Connector | Gegevensopmaak | Authentication type |
|---|---|---|
| Azure Blob-opslag | CSV, Parquet | Accountsleutel |
| Azure Data Lake Storage Gen1 | CSV | Service-principal |
| Azure Data Lake Storage Gen2 | CSV, Parquet | Accountsleutel, service-principal |
| Azure SQL-database | SQL-verificatie | |
| Azure Synapse Analytics | SQL-verificatie |
Zodra u een bron hebt geselecteerd, klikt u op Maken.

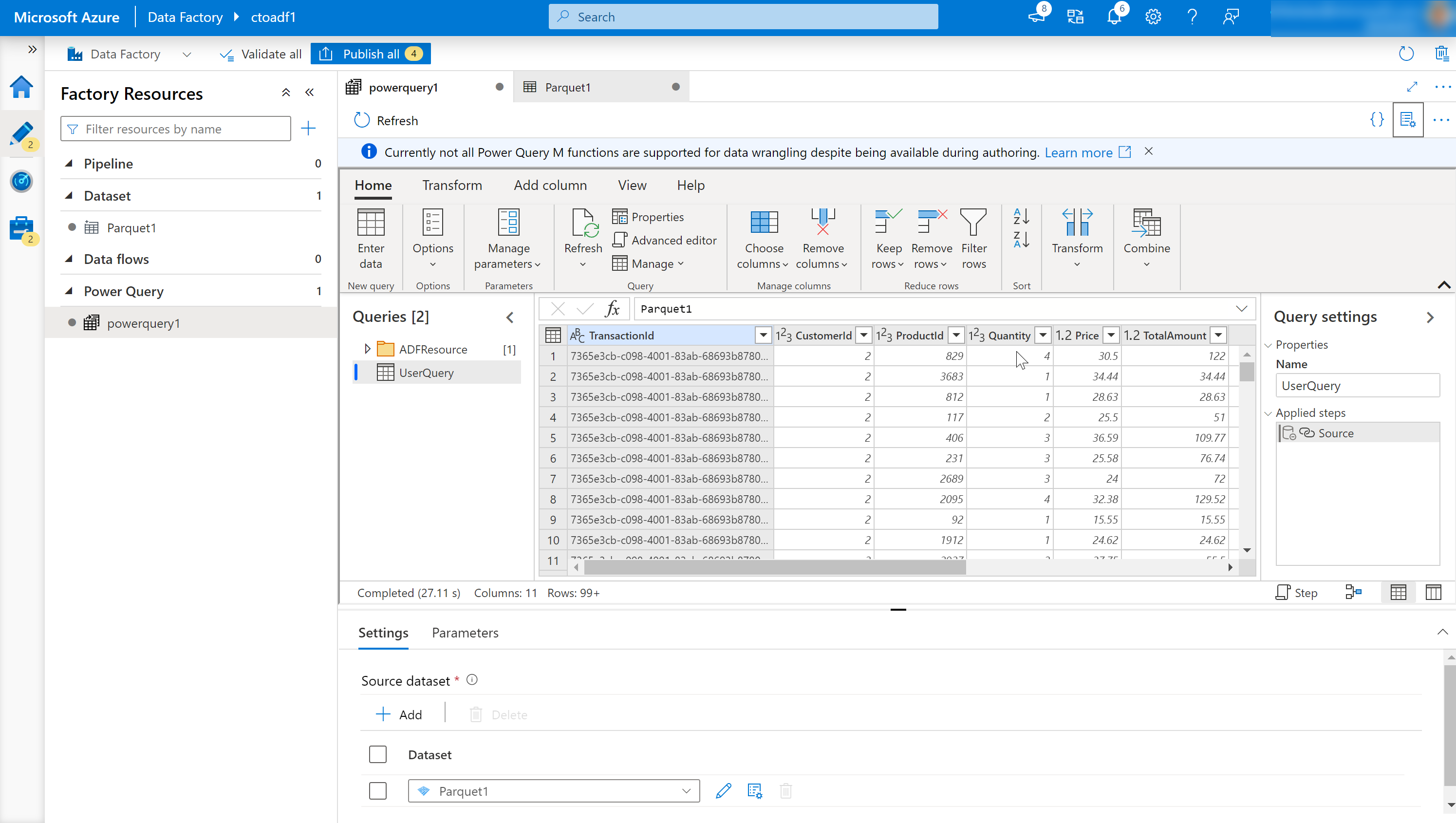
Hiermee opent u de Online Mashup Editor.

Het bestaat uit de volgende onderdelen:
Lijst met gegevenssets.
Hiermee worden de gegevenssets opgegeven die zijn gedefinieerd als de bron voor de Data Wrangling.
Werkbalk Wrangling Function.
De werkbalk bevat verschillende functies voor het wrangling van gegevens waartoe de gebruiker toegang heeft om de gegevens te bewerken, waaronder:
- Kolommen beheren.
- Tabellen transformeren.
- Rijen verminderen.
- Kolommen toevoegen.
- Tabellen combineren.
Elk item is contextgevoelig en bevat subfuncties die specifiek voor het item zijn.
Kolomkoppen.
Naast de mogelijkheid om de naam van kolommen te wijzigen, worden door met de rechtermuisknop op de kolom te klikken contextgevoelige items weergegeven voor het beheren van kolommen.
Instellingen.
Hiermee kunt u gegevensbronnen en gegevenssinks toevoegen of bewerken en de instelling voor de taak voor het wrangling-gegevens wijzigen.
Venster Stappen.
In dit venster ziet u de stappen die zijn toegepast op de wrangling-uitvoer. In het voorbeeld in de afbeelding is de stap met de naam Bron toegepast op de wrangling-uitvoer met de naam UserQuery.
Power Query-uitvoerlijst.
Geeft een lijst weer van de gegevens die zijn gedefinieerd.
Knop Publiceren.
Hiermee kunt u het werk publiceren dat is gemaakt.
Een Power Query-taak kan worden toegevoegd in de ontwerpfunctie voor canvass, net als een kopieeractiviteitstaak of een toewijzingstaak Gegevensstroom en kan op dezelfde manier worden beheerd en bewaakt.
