De spraak-naar-tekst-API gebruiken
Tip
Zie het tabblad Tekst en afbeeldingen voor meer informatie.
Azure Speech in Foundry Tools ondersteunt spraakherkenning via de Spraak-naar-tekst-API. Hoewel de specifieke details variëren, afhankelijk van de SDK die wordt gebruikt (Python, C#, enzovoort); er is een consistent patroon voor het gebruik van de Spraak-naar-tekst-API :
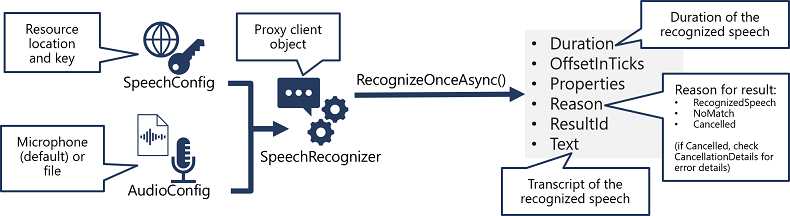
- Gebruik een SpeechConfig-object om de informatie in te kapselen die nodig is om verbinding te maken met uw Foundry-resource. Met name het eindpunt (of de regio) en de sleutel.
- Gebruik desgewenst een AudioConfig- om de invoerbron voor de audio te definiëren die moet worden getranscribeerd. Dit is standaard de standaardsysteemmicrofoon, maar u kunt ook een audiobestand opgeven.
- Gebruik speechConfig en AudioConfig om een SpeechRecognizer-object te maken. Dit object is een proxyclient voor de Spraak-naar-tekst-API .
- Gebruik de methoden van het SpeechRecognizer-object om de onderliggende API-functies aan te roepen. De methode RecognizeOnceAsync() gebruikt bijvoorbeeld de Azure Speech-service om asynchroon één gesproken uiting te transcriberen.
- Het antwoord verwerken. In het geval van de methode RecognizeOnceAsync() is het resultaat een SpeechRecognitionResult-object dat de volgende eigenschappen bevat:
- Duur
- OffsetInTicks
- Eigenschappen
- Reden
- ResultaatId
- Tekst
Als de bewerking is geslaagd, heeft de eigenschap Reason de opgesomde waarde RecognizedSpeech en bevat de eigenschap Text de transcriptie. Andere mogelijke waarden voor Resultaat zijn NoMatch (waarmee wordt aangegeven dat de audio is geparseerd, maar er geen spraak is herkend) of Geannuleerd, waarmee wordt aangegeven dat er een fout is opgetreden (in dat geval kunt u de verzameling Eigenschappen voor de eigenschap CancellationReason controleren om te bepalen wat er mis is gegaan).
Voorbeeld: een audiobestand transcriberen
In het volgende Python-voorbeeld wordt Azure Speech in Foundry Tools gebruikt om spraak in een audiobestand te transcriberen.
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))