De tekst-naar-spraak-API gebruiken
Tip
Zie het tabblad Tekst en afbeeldingen voor meer informatie.
Net als de spraak-naar-tekst-API's biedt Azure Speech in Foundry Tools een Text to Speech-API voor spraaksynthese:
Net als bij spraakherkenning worden in de praktijk de meeste interactieve spraaktoepassingen gebouwd met behulp van de Azure Speech SDK.
Het patroon voor het implementeren van spraaksynthese is vergelijkbaar met die van spraakherkenning:
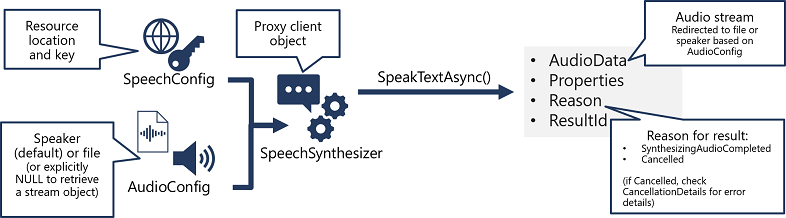
- Gebruik een SpeechConfig-object om de informatie in te kapselen die nodig zijn om verbinding te maken met uw Azure Speech-resource. Met name de locatie en sleutel.
- U kunt eventueel een AudioConfig gebruiken om het uitvoerapparaat voor de spraak te definiëren dat moet worden gesynthetiseerd. Dit is standaard de standaardsysteemluidspreker, maar u kunt ook een audiobestand opgeven of door deze waarde expliciet in te stellen op een null-waarde, kunt u het audiostreamobject verwerken dat rechtstreeks wordt geretourneerd.
- Gebruik SpeechConfig en AudioConfig om een SpeechSynthesizer-object te maken. Dit object is een proxyclient voor de Tekst-naar-spraak-API .
- Gebruik de methoden van het SpeechSynthesizer-object om de onderliggende API-functies aan te roepen. De methode SpeakTextAsync() gebruikt bijvoorbeeld de Azure Speech-service om tekst te converteren naar gesproken audio.
- Het antwoord van de Azure Speech-service verwerken. In het geval van de SpeakTextAsync-methode is het resultaat een SpeechSynthesisResult-object dat de volgende eigenschappen bevat:
- AudioData
- Eigenschappen
- Reden
- ResultaatId
Wanneer spraak is gesynthetiseerd, wordt de eigenschap Reason ingesteld op de opsomming SynthesizingAudioCompleted en bevat de eigenschap AudioData de audiostream (die, afhankelijk van de AudioConfig , mogelijk automatisch naar een luidspreker of bestand is verzonden).
Voorbeeld: tekst synthetiseren als spraak
In het volgende Python-voorbeeld wordt Azure Speech in Foundry Tools gebruikt om gesproken uitvoer van tekst te genereren.
import azure.cognitiveservices.speech as speechsdk
# Speech config encapsulates the connection to the resource
speech_config = speechsdk.SpeechConfig(subscription=KEY, endpoint=ENDPOINT)
# Audio output config determines where to send the audio stream (defaults to speaker)
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# Use speech synthesizer to synthesize text as speech
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config,
audio_config=audio_config)
text = "My voice is my password!"
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
# Did it succeeed?
if speech_synthesis_result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
# Yes!
print("Speech synthesized for text [{}]".format(text))
elif speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:
# No - Ty to find out why not
cancellation_details = speech_synthesis_result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))