Een IaaS-oplossing voor hoge beschikbaarheid en herstel na noodgevallen verkennen
Er zijn veel verschillende combinaties van functies die kunnen worden geïmplementeerd in Azure voor IaaS. In deze sectie vindt u vijf veelvoorkomende voorbeelden van HADR-architecturen (High Availability and Disaster Recovery) van SQL Server in Azure.
Voorbeeld 1 van hoge beschikbaarheid in één regio- AlwaysOn-beschikbaarheidsgroepen
Als u alleen hoge beschikbaarheid nodig hebt en geen noodherstel, is het configureren van een (beschikbaarheidsgroep) AG een van de meest alomtegenwoordige methoden, ongeacht waar u SQL Server gebruikt. In de onderstaande afbeelding ziet u een voorbeeld van hoe één mogelijke beschikbaarheidsgroep in één regio eruit kan zien.
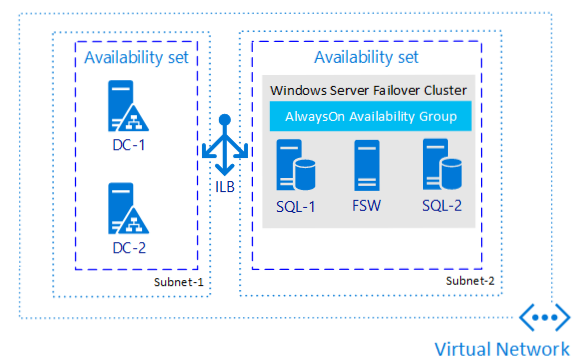
Waarom is deze architectuur de moeite waard om rekening mee te houden?
Deze architectuur beveiligt gegevens door meer dan één kopie op verschillende virtuele machines (VM's) te hebben.
Met deze architectuur kunt u voldoen aan RTO (Recovery Time Objective) en RPO (Recovery Point Objective) met minimaal tot geen gegevensverlies als deze correct zijn geïmplementeerd.
Deze architectuur biedt een eenvoudige, gestandaardiseerde methode voor toepassingen voor toegang tot zowel primaire als secundaire replica's (als zaken als alleen-lezen replica's worden gebruikt).
Deze architectuur biedt verbeterde beschikbaarheid tijdens patchscenario's.
Deze architectuur heeft geen gedeelde opslag nodig, dus er is minder complicatie dan bij het gebruik van een exemplaar van een failovercluster (FCI).
Voorbeeld 2 van hoge beschikbaarheid in één regio: AlwaysOn-failoverclusterexemplaren
Totdat AG's werden geïntroduceerd, waren CCI's de populairste manier om hoge beschikbaarheid van SQL Server te implementeren. HCI's zijn echter ontworpen wanneer fysieke implementaties dominant waren. In een gevirtualiseerde wereld bieden FCI's niet veel van dezelfde beveiligingen op de manier waarop ze zich op fysieke hardware zouden bevinden, omdat het zelden voorkomt dat een virtuele machine een probleem heeft. FCI's zijn ontworpen om te beschermen tegen zaken als netwerkkaartstoringen of schijffouten, die beide waarschijnlijk niet in Azure zouden plaatsvinden.
Dat gezegd hebbende, hebben CCI's een plaats in Azure. Ze werken, en zolang u de juiste verwachtingen hebt over wat is en niet wordt verstrekt, is een FCI een perfect acceptabele oplossing. In de onderstaande afbeelding in de Microsoft-documentatie ziet u een algemeen overzicht van hoe een FCI-implementatie eruitziet wanneer u Opslagruimten Direct gebruikt.
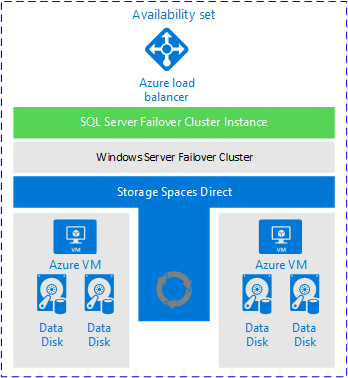
Waarom is deze architectuur de moeite waard om rekening mee te houden?
FCI's zijn nog steeds een populaire beschikbaarheidsoplossing.
Het verhaal over gedeelde opslag wordt verbeterd met functies zoals Azure Shared Disk.
Deze architectuur voldoet aan de meeste RTO en RPO voor hoge beschikbaarheid (hoewel dr niet wordt verwerkt).
Deze architectuur biedt een eenvoudige, gestandaardiseerde methode voor toepassingen voor toegang tot het geclusterde exemplaar van SQL Server.
Deze architectuur biedt verbeterde beschikbaarheid tijdens patchscenario's.
Voorbeeld van herstel na noodgevallen 1: een beschikbaarheidsgroep met meerdere regio's of hybride AlwaysOn
Als u AG's gebruikt, kunt u de beschikbaarheidsgroep configureren in meerdere Azure-regio's of mogelijk als een hybride architectuur. Dit betekent dat alle knooppunten die de replica's bevatten, deelnemen aan dezelfde WSFC. Hierbij wordt uitgegaan van een goede netwerkverbinding, met name als dit een hybride configuratie is. Een van de grootste overwegingen is de witness-resource voor de WSFC. Voor deze architectuur moeten AD DS en DNS ook beschikbaar zijn in elke regio en mogelijk on-premises als dit een hybride oplossing is. In de onderstaande afbeelding ziet u hoe één AG die is geconfigureerd via twee locaties, eruitziet met Behulp van Windows Server.

Waarom is deze architectuur de moeite waard om rekening mee te houden?
Deze architectuur is een bewezen oplossing; het is niet anders dan het hebben van twee datacenters vandaag in een AG-topologie.
Deze architectuur werkt met Standard- en Enterprise-edities van SQL Server.
AG's bieden uiteraard redundantie met extra kopieën van gegevens.
Deze architectuur maakt gebruik van één functie die zowel hoge beschikbaarheid als D/R biedt
Voorbeeld van herstel na noodgevallen 2 : gedistribueerde beschikbaarheidsgroep
Een gedistribueerde beschikbaarheidsgroep is een Enterprise Edition-functie die alleen is geïntroduceerd in SQL Server 2016. Het is anders dan een traditionele ag. In plaats van één onderliggende WSFC te hebben waarbij alle knooppunten replica's bevatten die deelnemen aan één AG, zoals beschreven in het vorige voorbeeld, bestaat een gedistribueerde AG uit meerdere AG's. De primaire replica met de lees-schrijfdatabase wordt de globale primaire replica genoemd. De primaire beschikbaarheidsgroep wordt een doorstuurserver genoemd en houdt de secundaire replica('s) van die AG gesynchroniseerd. In wezen is dit een AG van AG's.
Deze architectuur maakt het gemakkelijker om zaken als quorum af te handelen, omdat elk cluster een eigen quorum zou onderhouden, wat betekent dat het ook een eigen witness heeft. Een gedistribueerde beschikbaarheidsgroep werkt als u Azure gebruikt voor alle resources of als u een hybride architectuur gebruikt.
In de onderstaande afbeelding ziet u een voorbeeld van een gedistribueerde AG-configuratie. Er zijn twee WSFCs. Stel dat elk zich in een andere Azure-regio bevindt of zich on-premises bevindt en de andere zich in Azure bevindt. Elke WSFC heeft een AG met twee replica's. De globale primaire in AG 1 houdt de secundaire replica van AG 1 gesynchroniseerd en de doorstuurserver, die ook de primaire van AG 2 is. Deze replica houdt de secundaire replica van AG 2 gesynchroniseerd.
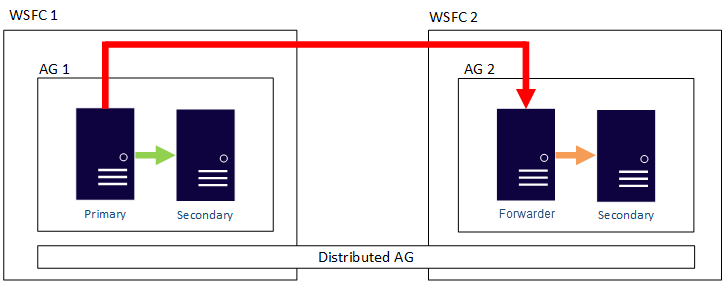
Waarom is deze architectuur de moeite waard om rekening mee te houden?
Deze architectuur scheidt de WSFC als een single point of failure als alle knooppunten de communicatie verliezen
In deze architectuur wordt niet alle secundaire replica's gesynchroniseerd.
Deze architectuur kan failback van de ene locatie naar de andere bieden.
Voorbeeld van herstel na noodgevallen 3 : logboekverzending
Logboekverzending is een van de oudste HADR-methoden voor het configureren van herstel na noodgevallen voor SQL Server. Zoals hierboven beschreven, is de maateenheid de back-up van het transactielogboek. Tenzij de switch naar een warme stand-by is gepland om ervoor te zorgen dat er geen gegevens verloren gaan, zal het gegevensverlies waarschijnlijk plaatsvinden. Als het gaat om herstel na noodgevallen, is het altijd het beste om uit te gaan van gegevensverlies, zelfs als dit minimaal is. In de onderstaande afbeelding in de Microsoft-documentatie ziet u een voorbeeld van een topologie voor het verzenden van logboeken.
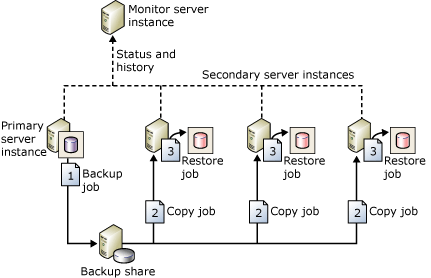
Waarom is deze architectuur de moeite waard om rekening mee te houden?
Logboekverzending is een functie die al meer dan 20 jaar bestaat
Logboekverzending is eenvoudig te implementeren en te beheren omdat deze is gebaseerd op back-up en herstel.
Logboekverzending is tolerant voor netwerken die niet robuust zijn.
Logboekverzending voldoet aan de meeste RTO- en RPO-doelen voor dr.
Logboekverzending is een goede manier om CCI's te beschermen.
Voorbeeld van herstel na noodgevallen 4 - Azure Site Recovery
Voor degenen die geen noodoplossing op basis van SQL Server willen implementeren, is Azure Site Recovery een mogelijke optie. De meeste dataprofessionals geven echter de voorkeur aan een databasegerichte benadering, omdat deze doorgaans een lagere RPO heeft.
De onderstaande afbeelding, in de Microsoft-documentatie. toont waar u in Azure Portal replicatie voor Azure Site Recovery zou configureren.
Waarom is deze architectuur de moeite waard om rekening mee te houden?
Azure Site Recovery werkt met meer dan alleen SQL Server.
Azure Site Recovery kan voldoen aan RTO en mogelijk RPO.
Azure Site Recovery wordt geleverd als onderdeel van het Azure-platform.