Opnamepatronen ontwerpen voor een modern datawarehouse
Gegevensopname kan op verschillende manieren plaatsvinden. Het primaire onderdeel van Azure Synapse Analytics voor het opnemen van gegevens is het gebruik van de kopieergegevensactiviteit in Azure Synapse Pipelines. Dit type activiteit wordt gewoonlijk bewaard in een Execute Pipeline-activiteit met andere functies, zoals een opzoekbewerking of een gesplitste gegevensactiviteit.
U kunt ook een verbinding maken binnen een Gegevensstroom die verwijst naar een brondatabase die wordt gebruikt als uitgangspunt voor het opnemen van gegevens en het gebruik van de gegevens binnen aanvullende transformatieactiviteiten.
Hieronder ziet u een voorbeeld van beide.
Gegevensopname
Selecteer de hub Integreren .

Vouw Pijplijnen uit en selecteer 1 hoofdpijplijn (1). Wijs de activiteiten (2) aan die aan de pijplijn kunnen worden toegevoegd en geef het pijplijncanvas (3) aan de rechterkant weer.

Onze Synapse-werkruimte bevat 16 pijplijnen waarmee we stappen voor gegevensverplaatsing en transformatie van gegevens uit verschillende bronnen kunnen organiseren.
De lijst Activiteiten bevat een groot aantal activiteiten die u naar het pijplijncanvas aan de rechterkant kunt slepen en neerzetten.
Hier ziet u dat we drie (onderliggende) pijplijnen hebben:

Selecteer de activiteit Alle pijplijnuitvoeringen aanpassen (1). Selecteer het tabblad Instellingen (2). Geef aan dat de aangeroepen pijplijn Alles aanpassen (3) is en selecteer Vervolgens Openen (4).

Zoals u kunt zien, zijn er vijf onderliggende pijplijnen. Met deze eerste uitvoering van pijplijnactiviteit worden nieuwe campagnegegevens van de fabrikant opgeschoond en opgenomen voor het rapport Campagneanalyse.
Selecteer de activiteit Campagneanalyse (1), selecteer het tabblad Instellingen (2), kijk of de aangeroepen pijplijn is ingesteld op Alles aanpassen (3) en selecteer Vervolgens Openen (4).

Bekijk hoe reiniging en opname in de pijplijn plaatsvinden door op elke activiteit te klikken.

Selecteer de hub Ontwikkelen .
Vouw gegevensstromen uit en selecteer vervolgens de ingest_data_from_sap_hana_to_azure_synapse gegevensstroom.
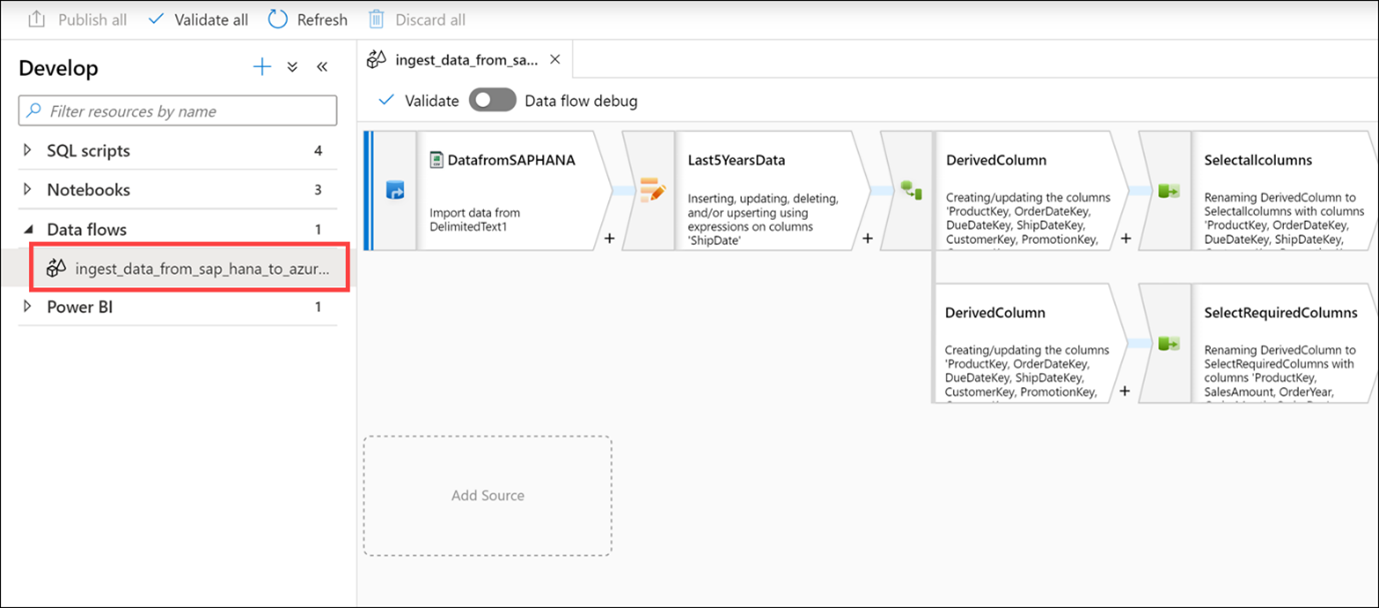
Zoals eerder vermeld, zijn gegevensstromen krachtige werkstromen voor gegevenstransformatie die gebruikmaken van de kracht van Apache Spark, maar die zijn geschreven met behulp van een codevrije GUI. Het werk dat u in de gebruikersinterface uitvoert, wordt omgezet in code die wordt uitgevoerd door een beheerd Spark-cluster, automatisch zonder dat u code hoeft te schrijven of het cluster te beheren.
De gegevensstroom voert de volgende functies uit:
- Extraheert gegevens uit de SAP HANA-gegevensbron (Select DatafromSAPHANA step).
- Haalt alleen de rijen op voor een upsert-activiteit, waarbij de waarde ShipDate groter is dan 2014-01-01 (Stap Last5YearsData selecteren).
- Hiermee worden gegevenstypetransformaties op de bronkolommen uitgevoerd met behulp van een activiteit afgeleide kolom (selecteer de bovenste afgeleidekolomactiviteit).
- In het bovenste pad van de gegevensstroom selecteren we alle kolommen en laden we de gegevens in de AggregatedSales_SAPHANANew Synapse-pooltabel (Selecteer de activiteit Selectallcolumns en de activiteit LoadtoAzureSynapse).
- In het onderste pad van de gegevensstroom selecteren we een subset van de kolommen (Selecteer de activiteit SelectRequiredColumns).
- Vervolgens groeperen we op vier van de kolommen (Selecteer de activiteit TotalSalesByYearMonthDay) en maken we som en gemiddelde aggregaties in de kolom SalesAmount (Selecteer de optie Aggregates).
- Ten slotte worden de samengevoegde gegevens geladen in de AggregatedSales_SAPHANA Synapse-pooltabel (selecteer de loadtoSynapse-activiteit).