Inzicht in data-warehouses
Een data warehouse is een gecentraliseerd, gestructureerd archief dat is ontworpen voor analytische query's en rapportage. In tegenstelling tot operationele databases die dagelijkse zakelijke transacties verwerken, voegt een data warehouse gegevens uit meerdere bronnen samen in een indeling die is geoptimaliseerd voor analyse.
Het bouwen van een moderne data warehouse omvat meestal het volgende:
- Gegevensopname: gegevens van bronsystemen verplaatsen naar het magazijn.
- Data storage : de gegevens opslaan in een indeling die is geoptimaliseerd voor analyse.
- Gegevensverwerking : de gegevens transformeren in een indeling die gereed is voor gebruik door analytische hulpprogramma's.
- Gegevensanalyse en -levering : de gegevens analyseren om inzichten te verkrijgen en ze aan het bedrijf te leveren.
Een data warehouse ontwerpen
Datawarehouses bevatten tabellen die zijn ingedeeld in een schema dat is geoptimaliseerd voor multidimensionale modellering. In deze benadering groepeert u numerieke gegevens met betrekking tot gebeurtenissen op verschillende kenmerken. U kunt bijvoorbeeld het totale bedrag analyseren dat is betaald voor verkoopopdrachten die hebben plaatsgevonden op een specifieke datum of in een bepaalde winkel.
Tabellen in een data warehouse
U organiseert data warehouse tabellen ter ondersteuning van een efficiënte analyse van grote hoeveelheden gegevens. Deze organisatie, ook wel dimensionale modellering genoemd, omvat het structureren van tabellen in feitentabellen en dimensietabellen.
Feitentabellen bevatten de numerieke gegevens die u wilt analyseren. Feitentabellen hebben doorgaans een groot aantal rijen en zijn de primaire gegevensbron voor analyse. Een feitentabel kan bijvoorbeeld het totale bedrag bevatten dat is betaald voor verkooporders die plaatsvonden op een specifieke datum of in een bepaalde winkel.
Dimensietabellen bevatten beschrijvende informatie over de gegevens in de feitentabellen. Dimensietabellen hebben doorgaans een paar rijen en bieden context voor de gegevens in de feitentabellen. Een dimensietabel kan bijvoorbeeld informatie bevatten over de klanten die verkooporders hebben geplaatst.
Naast kenmerkkolommen bevat een dimensietabel een unieke sleutelkolom die elke rij in de tabel uniek identificeert. In feite is het gebruikelijk dat een dimensietabel twee belangrijke kolommen bevat:
- Een surrogaatsleutel is een unieke id voor elke rij in de dimensietabel. Het is vaak een geheel getal dat het databasebeheersysteem automatisch genereert wanneer u een nieuwe rij invoegt.
- Een alternatieve sleutel is vaak een natuurlijke of zakelijke sleutel die een specifiek exemplaar van een entiteit in het transactionele bronsysteem identificeert, zoals een productcode of een klant-id.
U hebt zowel surrogaat- als alternatieve sleutels in een data warehouse nodig, omdat ze verschillende doeleinden dienen. Surrogaatsleutels zijn specifiek voor de data warehouse en helpen consistentie en nauwkeurigheid te behouden. Alternatieve sleutels zijn specifiek voor het bronsysteem en helpen traceerbaarheid te behouden tussen de data warehouse en het bronsysteem.
Speciale typen dimensietabellen
Speciale typen dimensies bieden extra context en maken uitgebreidere gegevensanalyse mogelijk.
Tijddimensies bieden informatie over de periode waarin een gebeurtenis heeft plaatsgevonden. Met deze tabel kunnen gegevensanalisten gegevens met tijdelijke intervallen aggregeren. Een tijddimensie kan bijvoorbeeld kolommen bevatten voor het jaar, het kwartaal, de maand en de dag van een verkooporder.
Langzaam veranderende dimensies volgen wijzigingen in dimensiekenmerken in de loop van de tijd, zoals wijzigingen in het adres van een klant of de prijs van een product. Ze zijn belangrijk in een data warehouse omdat u in de loop van de tijd wijzigingen in gegevens kunt analyseren en begrijpen. Langzaam veranderende dimensies zorgen ervoor dat gegevens up-to-datum en nauwkeurig blijven, wat belangrijk is voor het nemen van goede zakelijke beslissingen.
Data warehouse-schemaontwerpen
In de meeste transactionele databases die worden gebruikt in zakelijke toepassingen, worden de gegevens genormaliseerd om duplicatie te verminderen. In een data warehouse worden de dimensiegegevens echter gedenormaliseerd* om het aantal joins te verminderen dat nodig is om een query uit te voeren op de gegevens.
Vaak maakt een data warehouse gebruik van een sterschema, waarin een feitentabel rechtstreeks betrekking heeft op de dimensietabellen, zoals in dit voorbeeld wordt weergegeven:
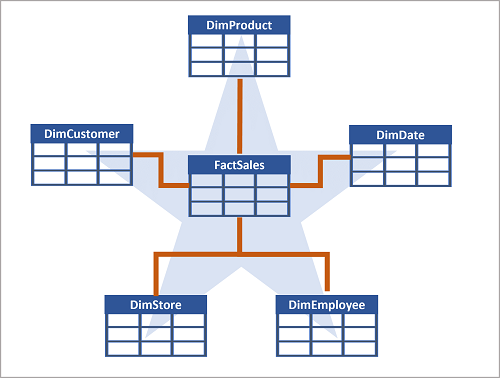
U kunt dimensiekenmerken gebruiken om getallen in feitentabellen op verschillende niveaus te groeperen. U kunt bijvoorbeeld de totale omzet voor een hele regio of slechts voor één klant vinden. U kunt de informatie voor elk niveau opslaan in dezelfde dimensietabel.
Tip
Zie Wat is een stervormig schema? voor meer informatie over het ontwerpen van stervormige schema's voor Fabric.
Als er veel niveaus of kenmerken zijn die door verschillende dingen worden gedeeld, kan het zinvol zijn om in plaats daarvan een snowflake-schema te gebruiken. Hier volgt een voorbeeld:
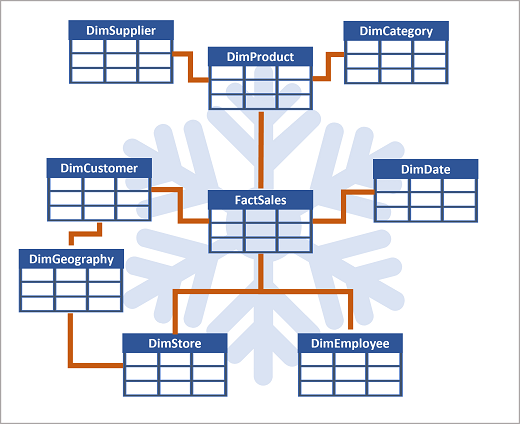
In dit geval splitst de tabel DimProduct (normaliseert) in afzonderlijke dimensietabellen voor productcategorieën en leveranciers.
- Elke rij in de tabel DimProduct bevat sleutelwaarden voor de bijbehorende rijen in de tabellen DimCategory en DimSupplier.
Een DimGeography-tabel bevat informatie over waar klanten en winkels zich bevinden.
- Elke rij in de tabellen DimCustomer en DimStore bevat een sleutelwaarde voor de bijbehorende rij in de tabel DimGeography .