Informatie extraheren uit documenten
Opmerking
Zie het tabblad Tekst en afbeeldingen voor meer informatie.
De bedrijfsprocessen van vandaag zijn sterk afhankelijk van gegevens in documenten zoals formulieren, ontvangsten en facturen. Handmatige verwerking kan vertragingen en fouten veroorzaken, waardoor automatisering van gegevensextractie belangrijker is dan ooit.
Hoe Azure Content Understanding werkt
Azure Content Understanding volgt een modelgestuurde extractiewerkstroom waarin ongestructureerde inhoud wordt opgenomen, geanalyseerd en geretourneerd als gestructureerde gegevens.
Inhoud opnemen: u verzendt inhoud naar Azure Content Understanding.
Door AI gemaakte analyse: de service maakt gebruik van een combinatie van: Optical Character Recognition (OCR), spraakherkenning, begrip van natuurlijke taal en multimodale AI-modellen om de inhoud te analyseren.
Gestructureerde uitvoer: de service retourneert gestructureerde resultaten (bijvoorbeeld in JSON) die overeenkomen met uw model, waardoor de gegevens eenvoudig kunnen worden opgeslagen, gezocht of geïntegreerd in downstreamsystemen.
Opmerking
JSON (JavaScript Object Notation) is een op tekst gebaseerde gegevensindeling die wordt gebruikt voor het opslaan en uitwisselen van gestructureerde gegevens tussen systemen. Het is eenvoudig voor mensen om te lezen en schrijven, en eenvoudig voor machines om te parseren en genereren.
Schema's begrijpen
MET OCR (optische tekenherkenning) kan een computer tekst 'lezen' uit afbeeldingen, zoals gescande documenten, foto's van ontvangstbewijzen of afbeeldingen van afgedrukte pagina's, en deze tekst omzetten in bewerkbare en doorzoekbare digitale tekst. Eenvoudige OCR helpt afgedrukte tekst te herkennen, is gericht op tekstextractie en begrijpt geen betekenis, context of relaties tussen woorden.
De documentanalysemogelijkheden van Azure Content Understanding gaan verder dan eenvoudige op OCR gebaseerde tekstextractie om op schema's gebaseerde extractie van velden en hun waarden op te nemen. De schemagestuurde benadering is wat Azure Content Understanding onderscheidt van basisservices voor OCR of transcriptie.
In een schema wordt beschreven welke informatie u wilt extraheren en hoe deze informatie moet worden gestructureerd. Wanneer u een schema definieert, geeft u velden op die moeten worden geëxtraheerd. Een schema bevat de specifieke velden of entiteiten die u belangrijk vindt.
Stel dat u een schema definieert dat de algemene velden bevat die doorgaans in een factuur worden gevonden, zoals:
- Naam van leverancier
- Factuurnummer
- Factuurdatum
- Klantnaam
- Aangepast adres
- Items - de bestelde items, die elk omvatten:
- Artikelbeschrijving
- Prijs per eenheid
- Bestelde hoeveelheid
- Regelitem totaal
- Subtotaal factuur
- Belasting
- Verzendkosten
- Factuurtotaal
Stel nu dat u deze informatie moet extraheren uit de volgende factuur:
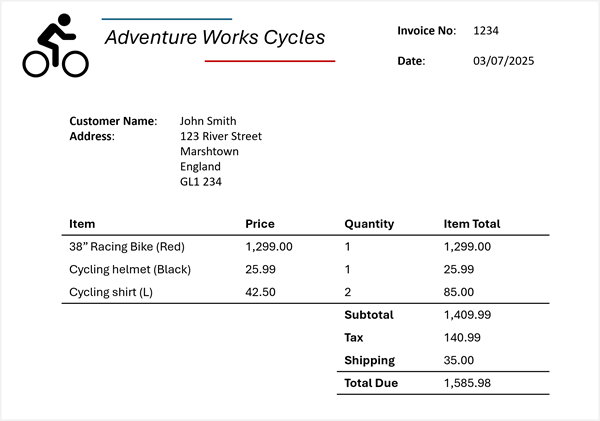
Azure Content Understanding kan het factuurschema toepassen op uw factuur en de bijbehorende velden identificeren, zelfs wanneer ze zijn gelabeld met verschillende namen (of helemaal niet gelabeld). De resulterende analyse produceert een resultaat als volgt:

Het schema definieert ook de veldstructuur. Schema's ondersteunen gestructureerde en geneste velden, niet alleen platte tekst. Voorbeeld:
-
Itemsis een verzameling - Elk item heeft
description,unit price,quantityenline total
Door gestructureerde velden te identificeren, kan Azure Content Understanding relaties tussen waarden begrijpen, iets wat OCR alleen niet kan doen.
In het factuurvoorbeeld kunt u voor elk gedetecteerd veld geneste waarden extraheren:
- Naam van leverancier: Adventure Works Cycles
- Factuurnummer: 1234
- Factuurdatum: 03-07-2025
- Klantnaam: John Smith
- Aangepast adres: 123 River Street, Marshtown, Engeland, GL1 234
-
Items:
- Item 1:
- Beschrijving van item: 38" Racefiets (rood)
- Eenheidsprijs: 1299,00
- Bestelde hoeveelheid: 1
- Regelitem totaal: 1299,00
- Item 2:
- Itembeschrijving: Fietshelm (zwart)
- Eenheidsprijs: 25,99
- Bestelde hoeveelheid: 1
- Totaal van regelitem: 25,99
- Item 3:
- Beschrijving van item: Fietshemd (L)
- Eenheidsprijs: 42,50
- Bestelde hoeveelheid: 2
- Regelitem totaal: 85,00
- Item 1:
- Factuursubtotaal: 1409,99
- Belasting: 140,99
- Verzendkosten: 35.00
- Factuurtotaal: 1585,98
Azure Content Understanding extraheert verwachte betekenis, niet alleen labels. Schema's worden semantisch toegepast, wat betekent:
- Velden kunnen worden geëxtraheerd, zelfs als labels verschillen
- Velden kunnen worden geëxtraheerd, zelfs als labels ontbreken
Factuurnummer, Factuur #of een niet-gelabeld nummer kunnen bijvoorbeeld allemaal worden toegewezen InvoiceNumber als de analyse bepaalt dat ze hetzelfde concept vertegenwoordigen.
Begrip van analyzers
Een analyse is een eenheid in Azure Content Understanding die invoer gebruikt, AI-analyse toepast en gestructureerde resultaten produceert. Analyses passen consistent dezelfde extractielogica toe op alle binnenkomende inhoud. Zodra het is geconfigureerd, zorgt een analyzer ervoor dat een schema consistent wordt hergebruikt voor elk analyseverzoek. Analyzers produceren ook voorspelbare JSON-resultaten. De gestructureerde resultaten maken downstreamverwerking (opslag, zoeken, automatisering) eenvoudiger.
Azure Content Understanding biedt vooraf gedefinieerde analyses voor algemene scenario's en biedt ondersteuning voor aangepaste analyses die zijn afgestemd op uw behoeften. Op hoog niveau:
- U kiest of maakt een analyzer.
- De analyse bevat een schema voor het definiëren van velden en structuur.
- U verzendt inhoud voor analyse
- De service past het schema toe
- U ontvangt gestructureerde JSON-resultaten die overeenkomen met het schema
Azure Content Understanding gebruiken in de Foundry-portal
Opmerking
Foundry Portal heeft een klassieke gebruikersinterface (UI) en een nieuwe gebruikersinterface.
Nadat u een Microsoft Foundry-resource hebt gemaakt, kunt u de klassieke Foundry-portalinterface gebruiken om Azure Content Understanding te testen. De Foundry-portal biedt voorbeelden van inhoud en stelt u in staat om uw eigen materiaal te uploaden voor analyse.
U kunt de visuele interface gebruiken om een brondocument te selecteren en standaardvelden met informatie te extraheren. Wanneer u bijvoorbeeld Azure Content Understanding op een afbeelding van een document probeert uit te proberen, retourneert de service de documenttekst- en tekstindelingsgegevens.

De analyse van Azure Content Understanding identificeert tekstwaarden in documenten en wijst deze toe aan specifieke velden. Op basis van een factuur retourneert de service bijvoorbeeld de velden (zoals Adres van leverancier) en de gegevens in de velden (zoals 123 456th Street).

In De Foundry-portal kunt u ook de JSON-resultaten van de verwerking bekijken.

Een clienttoepassing bouwen met Azure Content Understanding
U kunt de Content Understanding-API gebruiken om een lichtgewicht clienttoepassing te bouwen waarmee gegevens programmatisch worden geëxtraheerd.
Opmerking
Een clienttoepassing is een softwareprogramma dat wordt uitgevoerd op het apparaat van een gebruiker en services of gegevens aanvraagt van een ander systeem, meestal een server, via een netwerk. De client is het onderdeel van een toepassing waarmee gebruikers communiceren, terwijl de server het zware werk achter de schermen uitvoert. Toepassingen kunnen gegevens of acties aanvragen van een service en een gestructureerd antwoord ontvangen met behulp van een API.
Wanneer u de Content Understanding-API gebruikt, kunt u een vooraf gedefinieerde analyse kiezen of een aangepaste analyse maken. Vooraf gebouwde analysatoren omvatten: prebuilt-invoice, prebuilt-imageSearch, prebuilt-audioSearch, en prebuilt-videoSearch. Wanneer u inhoud verzendt voor analyse naar de analyse, is de analyse asynchroon, wat betekent dat u het resultaat later krijgt wanneer deze gereed is. Omdat de analyse asynchroon is, moet u de Operation-Location URL (of ) analyzerResults totdat de taak is voltooid.
De Azure Content Understanding Python SDK gebruiken
Laten we eens kijken naar het proces van het gebruik van de Python SDK om een factuur van een URL te analyseren.
- Installeer de Azure Content Understanding Python SDK.
python -m pip install azure-ai-contentunderstanding
Identificeer uw Foundry-resource-eindpunt en API-sleutel of Microsoft Entra-id. Uw eindpunt ziet er doorgaans als volgt uit:
https://<your-resource-name>.services.ai.azure.com/Maak en voer de code van de clienttoepassing uit. Dit
analzyer_idis de ID van de vooraf gebouwde analyzer. Hier vindt u een lijst met vooraf gedefinieerde waarden voor analyse-id's.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
De resulterende uitvoer is JSON met de geëxtraheerde markdown, velden, gegevens in de velden en betrouwbaarheidsscore. Voorbeeld:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
Leer vervolgens hoe u Azure Content Understanding Analyzers gebruikt om gestructureerde gegevens te extraheren uit audio en video.