De architectuur, onderdelen en functionaliteit van gegevensontdubbeling definiëren
De meeste organisaties en bedrijven, waaronder Contoso, moeten omgaan met het verwerken en opslaan van een toenemend aantal gegevens. Hoewel er oplossingen zijn waarmee u gegevens naar de cloud kunt offloaden en archiveren, is het in veel gevallen nodig om deze te onderhouden in on-premises datacenters. Efficiënt beheer van het opslaan van dergelijke gegevens vereist juiste hulpprogramma's. Wanneer u Windows Server gebruikt, hebt u de mogelijkheid om voor dit doel gegevensontdubbeling te gebruiken.
Wat is Gegevensontdubbeling?
Gegevensontdubbeling is een functieservice van Windows Server waarmee duplicaties in gegevens worden geïdentificeerd en verwijderd zonder de gegevensintegriteit in gevaar te brengen. Dit bereikt de doelstellingen van het opslaan van meer gegevens en het gebruik van minder fysieke schijfruimte.
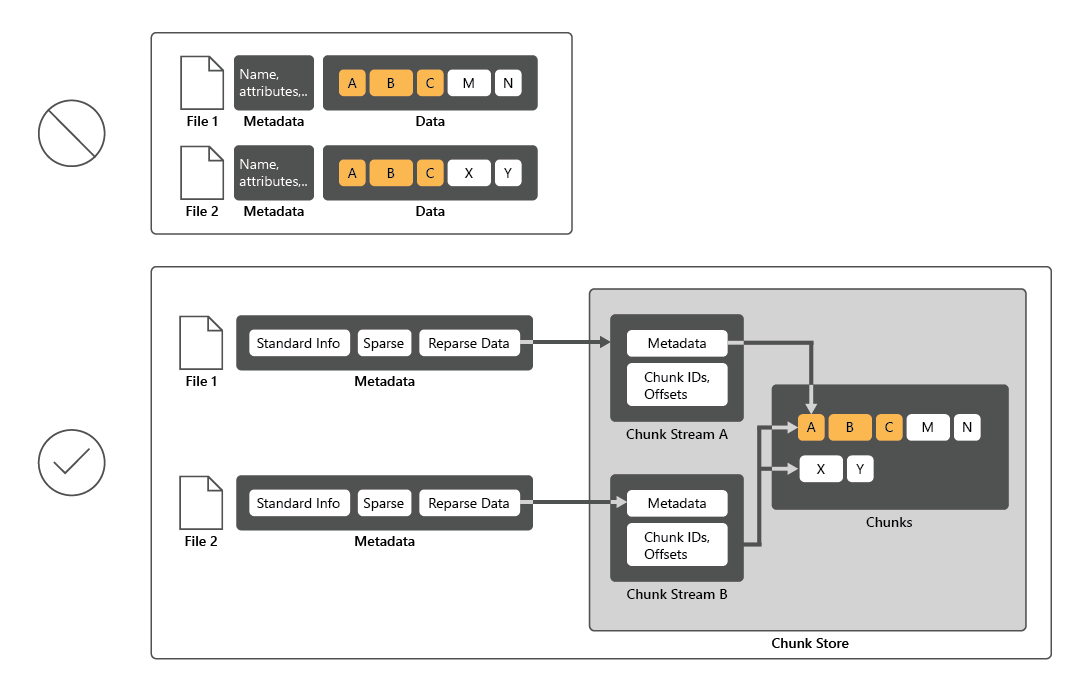
Als u het schijfgebruik wilt verminderen, scant Gegevensontdubbeling bestanden, verdeelt u deze bestanden in segmenten en behoudt u slechts één kopie van elk segment. Na ontdubbeling worden bestanden niet meer opgeslagen als onafhankelijke gegevensstromen. In plaats daarvan vervangt Gegevensontdubbeling de bestanden door stubs die verwijzen naar gegevensblokken die worden opgeslagen in een gemeenschappelijk segmentarchief. Het proces voor het openen van ontdubbelde gegevens is volledig transparant voor gebruikers en apps.
In veel gevallen verhoogt gegevensduplicatie de algehele schijfprestaties, omdat meerdere bestanden één segment in cache in het geheugen kunnen delen. Op deze manier is het mogelijk om gegevens op te halen uit deze bestanden door minder leesbewerkingen uit te voeren, wat een kleine invloed op de prestaties compenseert bij het lezen van ontdubbelde bestanden. Gegevensontdubbeling heeft geen invloed op de prestaties van schijfschrijfbewerkingen, omdat deze van toepassing is op gegevens die zich al op de schijf bevinden.
Wat zijn de onderdelen van Gegevensontdubbeling?
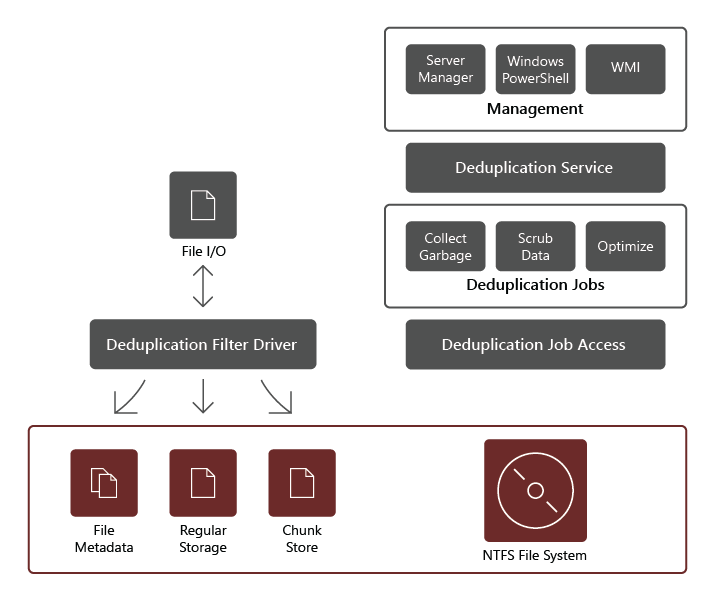
De functieservice voor gegevensontdubbeling bestaat uit de volgende onderdelen:
- Filterstuurprogramma. Met dit onderdeel worden leesaanvragen omgeleid naar de segmenten die deel uitmaken van het bestand dat wordt aangevraagd. Er is één filterstuurprogramma voor elk volume.
- Ontdubbelingsservice. Met dit onderdeel worden de volgende taken beheerd:
- Ontdubbeling en compressie. Deze taken verwerken bestanden volgens het beleid voor gegevensontdubbeling voor het volume. Als het bestand na de eerste optimalisatie van een bestand vervolgens wordt gewijzigd en voldoet aan de drempelwaarde voor gegevensontdubbelingsbeleid voor optimalisatie, wordt het bestand opnieuw geoptimaliseerd.
- Garbagecollection. Met deze taak worden verwijderde of gewijzigde gegevens op het volume verwerkt, zodat gegevenssegmenten waarnaar niet meer wordt verwezen, worden opgeschoond, wat vrije schijfruimte oplevert. Garbagecollection wordt standaard wekelijks uitgevoerd, maar u kunt ook overwegen deze aan te roepen nadat u veel bestanden hebt verwijderd.
- Schrobben. Deze taak is afhankelijk van dergelijke tolerantiefuncties als controlesomvalidatie en consistentiecontrole van metagegevens om problemen met gegevensintegriteit te identificeren en, indien mogelijk, automatisch op te lossen.
Notitie
Vanwege de extra validatiemogelijkheden kan ontdubbeling vroege tekenen van gegevensbeschadiging detecteren en rapporteren.
- Optimalisatie ongedaan maken. Met deze taak wordt ontdubbeling omgekeerd op alle geoptimaliseerde bestanden op het volume. Enkele veelvoorkomende scenario's voor het gebruik van dit type taak zijn het oplossen van problemen met ontdubbelde gegevens of migratie van gegevens naar een ander systeem dat geen ondersteuning biedt voor gegevensontdubbeling.
Notitie
Voordat u deze taak start, moet u de Disable-DedupVolume Windows PowerShell-cmdlet gebruiken om verdere activiteit voor gegevensontdubbeling op een of meer volumes uit te schakelen.
Notitie
Na het uitschakelen van gegevensontdubbeling blijft het volume in de ontdubbelde status en blijven de bestaande ontdubbelde gegevens toegankelijk; De server stopt echter met het uitvoeren van optimalisatietaken voor het volume en ontdubbelt de nieuwe gegevens niet. Daarna kunt u de taak voor het ongedaan maken van de optimalisatie gebruiken om de bestaande ontdubbelde gegevens op een volume ongedaan te maken. Aan het einde van een geslaagde de-optimalisatietaak worden alle metagegevens van gegevensontdubbeling van het volume verwijderd.
Belangrijk
Wanneer u de niet-optimalisatietaak gebruikt, controleert u of het volume dat als host fungeert voor deze gegevens voldoende vrije ruimte heeft, omdat alle ontdubbelde bestanden worden teruggezet naar de oorspronkelijke grootte.
Bereik van gegevensontdubbeling
Gegevensontdubbeling verwerkt alle gegevens op een geselecteerd volume, met enkele uitzonderingen, waaronder:
- Bestanden die niet voldoen aan het ontdubbelingsbeleid dat u configureert.
- Bestanden in mappen die u expliciet uitsluit van het bereik van ontdubbeling.
- Systeemstatusbestanden.
- Alternatieve gegevensstromen.
- Versleutelde bestanden.
- Bestanden met uitgebreide kenmerken.
- Bestanden kleiner dan 32 kB.
Notitie
Sinds Windows Server 2019 ondersteunt Resilient File System (ReFS) gegevensontdubbeling voor volumes van maximaal 64 terabytes (TB) in grootte en bestanden van maximaal 4 TB. Het is ook afhankelijk van een segmentarchief met variabele grootte dat optionele compressie omvat om de schijfruimte te maximaliseren, terwijl de architectuur met meerdere threads na verwerking de prestaties minimaal beïnvloedt.