Stretch-clusters implementeren
Normaal gesproken bieden failoverclusters bescherming tegen hoge beschikbaarheid tegen gelokaliseerde fouten in een of meer clusterknooppunten die zich op dezelfde fysieke locatie bevinden. U kunt stretch-clusters gebruiken wanneer het nodig is om de equivalente functionaliteit op meerdere fysieke locaties te bieden.
Wat zijn stretch-clusters?
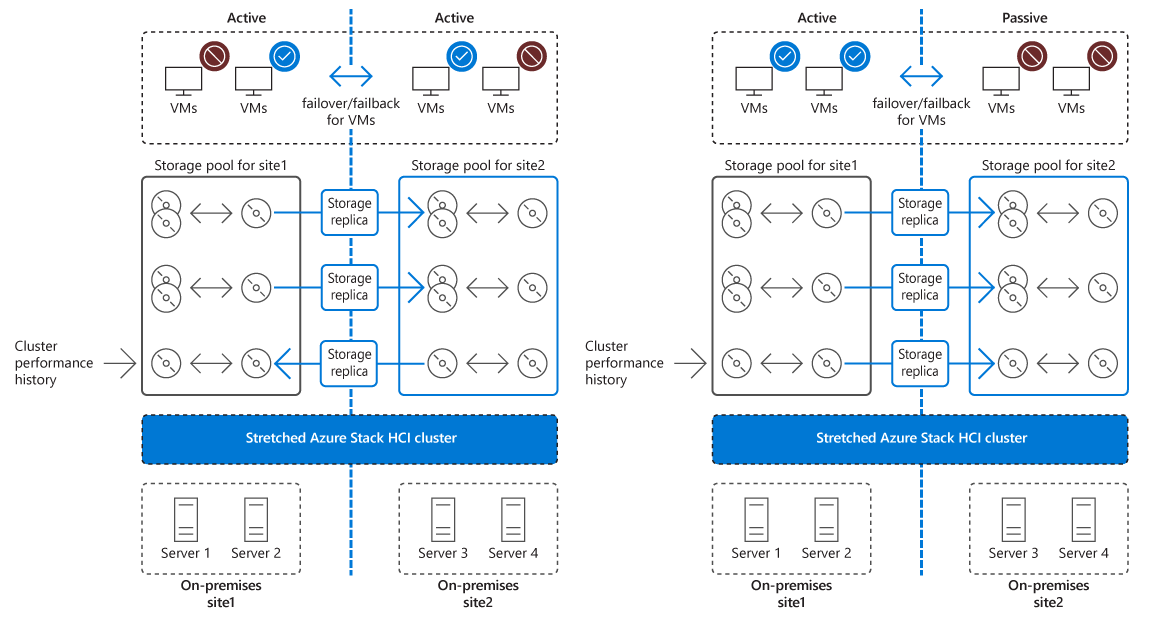
Een stretch-cluster implementeert hoge beschikbaarheid en herstel na noodgevallen op twee afzonderlijke fysieke locaties. Beide locaties hosten een afzonderlijk opslagsysteem, met een synchrone, synchrone replicatie van de primaire site naar de secundaire site. Als een fout van invloed is op de beschikbaarheid van de primaire site om downtime te minimaliseren, worden de werkbelastingen automatisch overgezet naar knooppunten op de secundaire site. Voor geplande onderhoudsgebeurtenissen op de primaire site kunt u Hyper-V livemigratie gebruiken om workloads naadloos over te zetten naar de andere site, waardoor downtime helemaal wordt voorkomen.
Het gebruik van stretch-clusters biedt verschillende voordelen ten opzichte van het handmatig onderhouden van een site voor herstel na noodgevallen:
- Automatische replicatie en automatische failover van geclusterde workloads.
- Beheeroverhead verminderen.
- Minimaliseer de mogelijkheid van menselijke fouten, wat inherent is aan handmatige processen.
Aan de andere kant zijn stretch-clusters complexer om te ontwerpen en te implementeren. Ze vereisen doorgaans ook een extra investering in opslag- en netwerkinfrastructuur.
Overzicht van Opslagreplica
Stretch-clusters maken gebruik van Opslagreplica, een Windows Server-functie die replicatie van volumes tussen servers of clusters biedt voor herstel na noodgevallen. Met behulp van Opslagreplica kunnen stretch-clusters opslagvolumes synchroniseren die zijn gekoppeld aan stretch-clusterknooppunten op twee afzonderlijke locaties.
Opslagreplica ondersteunt synchrone en asynchrone replicatie:
- Synchrone replicatie repliceert gegevens via een netwerk met lage latentie, binnen milliseconden van retourtijd, waardoor er tijdens een failover geen gegevensverlies op bestandssysteemniveau is.
- Asynchrone replicatie repliceert gegevens over langere afstanden die onderhevig zijn aan hogere latenties, maar zonder een garantie dat beide sites identieke kopieën van de gegevens hebben op het moment van een failover.
Belangrijk
Stretch-clusters vereisen synchrone replicatie. Deze vereiste legt de limiet op van 5 ms retournetwerklatentie tussen twee groepen clusterknooppunten in de gerepliceerde sites. Afhankelijk van de kenmerken van de fysieke netwerkverbinding wordt deze beperking doorgaans omgezet in een afstand van ongeveer 20-30 mijl.
Functies van Opslagreplica
De belangrijkste functies van Storage Replica worden weergegeven in de volgende tabel.
| Feature | Beschrijving |
|---|---|
| Replicatie op blokniveau | Met replicatie op blokniveau is het niet mogelijk om bestanden te vergrendelen. |
| Eenvoud | U kunt vertrouwen op Het Windows-beheercentrum om u te begeleiden bij het maken van een replicatierelatie tussen twee servers. Als u een stretch-cluster wilt implementeren, kunt u een wizard Failoverclusterbeheer gebruiken. |
| Gebruik van Server Message Block (SMB) 3.0 | Opslagreplica is afhankelijk van SMB 3.x, geïntroduceerd in Windows Server 2012 en aanzienlijk verbeterd in volgende versies van Windows Server. Alle geavanceerde kenmerken van SMB, zoals SMB meerdere kanalen en SMB Direct, zijn beschikbaar voor Opslagreplica. |
| Veiligheid | Opslagreplica bevat een breed scala aan beveiligingsmechanismen, waaronder pakketondertekening, AES-128-GCM volledige gegevensversleuteling, ondersteuning voor versleutelingsversnelling van derden en preventie van man-in-the-middle-aanvalsintegriteit. Opslagreplica is ook afhankelijk van Kerberos AES256 voor alle verificatie tussen knooppunten. |
| Netwerkbeperkingen | In gevallen waarin er meerdere netwerkpaden tussen gerepliceerde volumes zijn, kunt u Opslagreplica-verkeer configureren voor het gebruik van aangewezen netwerkadapters. Hierdoor kunt u potentiële impact van het replicatieverkeer op productieworkloads minimaliseren. |
| Dunne provisie | U kunt thin provisioning implementeren in Opslagruimten Direct, waardoor de initiële replicatietijden worden geminimaliseerd. |
Vereisten voor het implementeren van stretch-clusters
De vereisten voor het implementeren van stretched clusters zijn:
Clusterknooppunten moeten lid zijn van hetzelfde of vertrouwde AD DS-forest.
Elk clusterknooppunt moet ten minste 2 GB RAM en twee CPU-kernen per server hebben.
Op elk clusterknooppunt moet Windows Server 2025 Datacenter of Windows Server 2016 Datacenter-editie worden uitgevoerd. Het is mogelijk windows Server 2025 Standard-editie te gebruiken, maar een dergelijke configuratie ondersteunt alleen replicatie van één volume van maximaal 2 terabytes (TB).
Elk clusterknooppunt moet minimaal 1 Gigabit Ethernet-adapter hebben voor synchrone replicatie, hoewel Remote Direct Memory Access (RDMA) de voorkeur heeft.
Twee sets volumes (één voor gegevens en de andere voor logboeken) op de primaire en secundaire site, met de volgende instellingen:
Schijven moeten worden geïnitialiseerd als GUID Partition Table (GPT), in plaats van master boot record (MBR).
- Volumes moeten worden geformatteerd met ReFS of NTFS.
- De grootten en sectorgrootten van de gegevensvolumes moeten overeenkomen.
- De grootten en sectorgrootten van de logboekvolumes moeten overeenkomen.
- De logboekvolumes moeten snellere opslag gebruiken dan gegevensvolumes.
- De logboekvolumes mogen niet worden gebruikt voor andere werkbelastingen.
Bidirectionele connectiviteit via ICMP (Internet Control Message Protocol), SMB (poort 445, plus poort 5445 voor SMB Direct) en Web Services-Management (WS-MAN) (poort 5985) tussen de twee sites.
Een netwerk tussen servers met voldoende bandbreedte om I/O-schrijfbewerkingen van de geclusterde workloads en minder dan 5 ms retourlatentie te vinden.
Overwegingen voor het implementeren van een stretch-cluster
Stretch-clusters zijn niet geschikt voor elke workload en elk scenario. Wanneer u een stretch-clusteroplossing ontwerpt, moet u duidelijk de vereisten en verwachtingen van de organisatie identificeren. Houd er bovendien rekening mee dat stretch-clusters meer beheeroverhead opleggen dan traditionele clusters waar alle knooppunten zich binnen dezelfde fysieke locatie bevinden. U moet ook zorgvuldig rekening houden met de optimale keuze van de quorumwitness om de beschikbaarheid te maximaliseren in het geval van een noodgeval dat van invloed is op een hele fysieke site.
Belangrijk
Stateful toepassingen en services zoals Microsoft SQL Server, Hyper-V, Microsoft Exchange Server en AD DS moeten hun eigen, systeemeigen tolerantiemechanismen gebruiken in plaats van te vertrouwen op stretch-clusters voor hoge beschikbaarheid.
Overwegingen voor failover en failback in een stretch-cluster
Als onderdeel van de planning voor de implementatie van een stretch-cluster moet u de failover- en failbackconfiguratie definiëren, rekening houdend met de volgende overwegingen:
- Infrastructuurafhankelijkheden. U moet de kritieke services, zoals AD DS, DNS en DHCP, duidelijk definiëren die beschikbaar moeten blijven na een failover naar de secundaire site.
- Quorummodel. Het is belangrijk om het quorummodel te kiezen dat de clusterfunctionaliteit behoudt na een failover.
- Servicepublicatie en naamomzetting. Als u services hebt die zijn gepubliceerd naar uw interne of externe gebruikers, zoals e-mail en webpagina's, moet u er rekening mee houden dat in sommige gevallen failover naar een andere site naam- of IP-adreswijzigingen vereist. Als dat het geval is, moet u een procedure hebben voor het wijzigen van DNS-records in de interne of openbare DNS. Om downtime te verminderen, raden we u aan om de TTL-waarde (Time to Live) van kritieke DNS-records te verminderen.
- Clientconnectiviteit. In geval van een noodgeval moet een failoverplan voldoen aan de connectiviteit van clienttoepassingen naar geclusterde workloads. Dit omvat zowel interne als externe clients.
- De failbackprocedure. U moet een failbackproces plannen en implementeren dat moet worden uitgevoerd nadat de primaire site weer online is. Failback is net zo belangrijk als een failover. Als u deze fout onjuist uitvoert, kunt u gegevensverlies en service-downtime veroorzaken.
Een stretch-cluster maken
U kunt een stretch-cluster maken met behulp van Windows Admin Center, Failoverclusterbeheer of Windows PowerShell. Windows Admin Center vereenvoudigt de implementatie van stretch-clusters door u te begeleiden bij het inrichtingsproces en het automatiseren van de meeste configuratietaken. Dit omvat ondersteuning voor:
- Hypergeconvergeerde clusters (failoverclustering, Hyper-V en Opslagruimten Direct).
- Opslagclusters (failoverclustering en Opslagruimten Direct).
Opmerking
Het maken van een stretch-cluster met failoverclusterbeheer of Windows PowerShell is complexer. Voor beide methoden moet elk van de tussenliggende implementatiestappen worden uitgevoerd. In de eenvoudigste termen begint dit met het maken van een traditioneel, niet-stretched failovercluster dat bestaat uit alle knooppunten in de primaire en de secundaire site. Nadat u het cluster hebt gemaakt en de validatie hebt voltooid, maakt u op elke site een afzonderlijke set opslagvolumes. Ten slotte configureert u Opslagreplica om opslagvolumes tussen de twee sites te repliceren.