De opties voor hoge beschikbaarheid van Windows Server-bestandsserver verkennen
Bestandsservices vertegenwoordigen een van de meest voorkomende typen Windows Server-workloads. In veel gevallen is hun beschikbaarheid essentieel voor bedrijfsactiviteiten. Windows Server biedt verschillende methoden om ervoor te zorgen dat de beschikbaarheid wordt gegarandeerd.
Opties voor hoge beschikbaarheid van Windows File Server
Als u tolerante bestandsservices op Windows Server wilt implementeren, kunt u gebruikmaken van hoge beschikbaarheid die inherent is aan failoverclusteringrollen. U kunt ook tolerantie bieden door inhoud te repliceren van volumes die bestandsshares hosten met Opslagreplica.
Opties voor failoverclustering van Windows Server-bestandsserver
U kunt een geclusterde bestandsserver implementeren en configureren met een van de volgende methoden:
- Bestandsserver voor algemeen gebruik. Dit is de traditionele bestandsserverfunctie die sinds de introductie van failoverclustering in het Windows Server-besturingssysteem beschikbaar is. Vanuit het oogpunt van beschikbaarheid en schaalbaarheid werkt de geclusterde rol in de actief-passieve modus, wat betekent dat de bijbehorende bestandsshares, ook wel geclusterde bestandsshares genoemd, beschikbaar zijn op een van de clusterknooppunten. Als dit knooppunt uitvalt, wordt het eigendom van de rol en de bijbehorende resources overgenomen op een ander knooppunt, waardoor de beschikbaarheid van de gedeelde mappen behouden blijft. Clients hebben echter altijd toegang tot deze via één knooppunt. Dit type implementatie van bestandsservers is geschikt voor scenario's voor informatiemedewerkers. Deze term vertegenwoordigt standaard bedrijfsscenario's, waarbij gebruikers afhankelijk zijn van bestandsshares voor het opslaan van hun thuismappen, zwervende profielen, gedeelde gegevens van afdelingen, waaronder documenten, spreadsheets en andere typen ongestructureerde of semi-gestructureerde gegevens.
- SOFS voor toepassingsgegevens. Dit geclusterde bestandsservertype is bedoeld voor servertoepassingsgegevens, zoals bestanden van virtuele Microsoft Hyper-V-machines of SQL Server-databasebestanden. Het biedt superieure betrouwbaarheid, beschikbaarheid, beheerbaarheid en prestaties, met de geclusterde rol die in de actief-actieve modus werkt. Dit betekent dat alle bestandsshares, waarnaar in dit geval wordt verwezen als scale-out bestandsshares, tegelijkertijd beschikbaar zijn op alle clusterknooppunten. Deze benadering is optimaal bij het implementeren van Hyper-V via Server Message Block (SMB) of Microsoft SQL Server via SMB.
Opslagreplica
Opslagreplica is een Windows Server-technologie die unidirectionele, opslagagnostische replicatie mogelijk maakt tussen opslagvolumes die zich op zelfstandige of geclusterde servers bevinden voor hoge beschikbaarheid of herstel na noodgevallen. U kunt synchrone of asynchrone replicatie kiezen, afhankelijk van de netwerklatentie en de afstand tussen de servers. Met Opslagreplica is alleen het bronvolume toegankelijk tijdens normale bedrijfsactiviteiten. In het geval van een fout kunt u een failover naar het doelvolume uitvoeren en online brengen.
Opslagreplica ondersteunt drie scenario's:
- Server-naar-server.
- Cluster-naar-cluster.
- Stretch-cluster.
Met de clusterscenario's kunt u bestandsserver implementeren voor algemeen gebruik of SOFS. Met server-naar-serverreplicatie biedt Opslagreplica tolerantie voor traditionele, zelfstandige bestandsshares.
Synchrone en asynchrone replicatie
Opslagreplica ondersteunt twee typen replicatie:
- Synchrone replicatie repliceert volumes tussen sites die relatief dicht bij elkaar liggen. Replicatie is crashconsistent, wat zorgt voor nul gegevensverlies op bestandssysteemniveau tijdens een failover.
- Asynchrone replicatie maakt replicatie mogelijk over langere afstanden in gevallen waarin de latentie van een netwerkrondje langer is dan 5 milliseconden (ms), maar het is onderhevig aan gegevensverlies. De omvang van het gegevensverlies is afhankelijk van de vertraging van de replicatie tussen de bron- en doelvolumes.
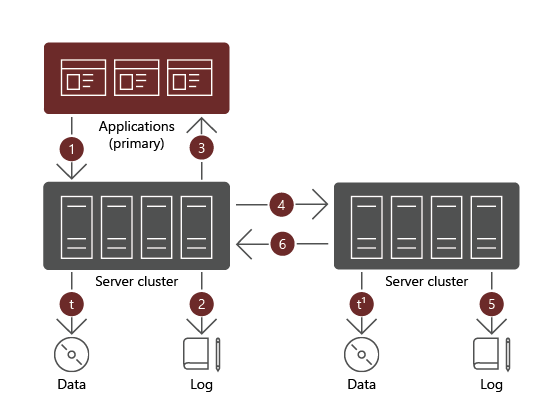
Wanneer u synchrone replicatie gebruikt, moet een gegevensschrijfbewerking op beide volumes zijn voltooid. Als dat niet het geval is, moet de werkbelasting die de schrijfbewerking start, dezelfde bewerking opnieuw uitvoeren. Bij synchrone replicatie zijn de gegevens op beide volumes identiek.
Gebruik synchrone replicatie wanneer het noodzakelijk is dat u gegevensverlies vermijdt. Synchrone replicatie vereist een lage netwerklatentie om te wachten op de bevestiging van de externe schrijfbewerking. Deze vereiste beperkt de afstand tussen de servers of clusters die elk volume hosten.
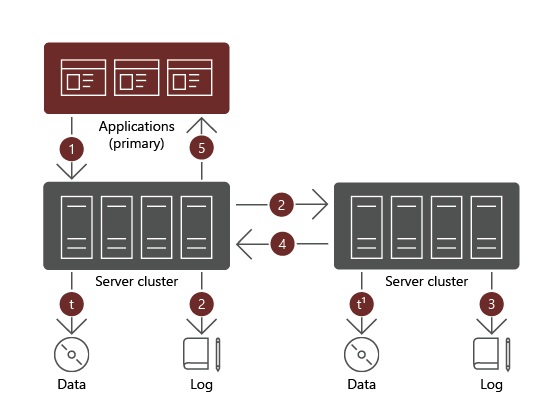
Wanneer u asynchrone replicatie gebruikt, ontvangt de werkbelasting die de schrijfbewerking start, een bevestiging wanneer een gegevensschrijfbewerking is voltooid op het primaire volume. De werkbelasting die de schrijfbewerking start, ontvangt een bevestiging en kan doorgaan met een andere I/O-bewerking. De bijbehorende schrijfbewerkingen worden achteraf uitgevoerd op het secundaire volume, zonder dat dit van invloed is op het primaire volume.