Incidentenopvolging
Incidenten hebben een levenscyclus. Als u het meest effectief wilt reageren, moet u de evolutie van het incident zelf en de evolutie van uw reactie hierop kunnen volgen, vanaf het begin van die levenscyclus.
Beoordelen wat u weet
Een goede manier om uw procedure voor het bijhouden van incidenten te evalueren met behulp van een specifiek incident is om uzelf een reeks vragen te stellen:
- Wanneer wist je het probleem voor het eerst? Als u de tijd wilt beperken die nodig is om incidenten te herstellen, moet u beginnen met het vastleggen van informatie vanaf het moment dat u op de hoogte bent van de problemen.
- Hoe hebt u het probleem ontdekt? Heeft uw bewakingssysteem u gewaarschuwd over het incident? Hebt u er eerst over gehoord van uw klanten die rechtstreeks of via sociale media klagen?
- Als u net ontdekt wat het probleem is, bent u dan de eerste die het weet? Als dat het zo is, wie moet u op de hoogte stellen? Zo niet, wie is er nog meer op de hoogte van het probleem?
- Als anderen zich ervan bewust zijn, wat wordt er dan (als er iets gebeurt) aan gedaan? Gaat iedereen ervan uit dat iemand anders ernaar kijkt of dat iemand actie heeft ondernomen om dit aan te pakken?
- Hoe slecht is het? We hebben mogelijk geen idee van ernst of impact, en er is geen plek voor ons om erachter te komen hoe slecht het probleem echt is en wie wordt beïnvloed.
Dit kunnen moeilijke vragen zijn om te beantwoorden als er niets wordt bijgehouden.
Standaardiseren waar incidentgegevens worden bijgehouden
Er zijn veel mogelijke locaties waar u uw lijst met incidenten (actief, inactief of anderszins) en alle huidige informatie daarover kunt bewaren en delen. Dit kan net zo eenvoudig zijn als een gedeeld bestandsgebied met Word-documenten en zo complex als zeer complexe software en services voor het bijhouden van incidenten. Tussen deze twee extremen bevinden zich ticketingsystemen en werkvolgsystemen die u voor deze taak kunt gebruiken. Welk systeem u kiest, is eigenlijk minder belangrijk dan hoe u het gebruikt. Ongeacht het systeem dat u gebruikt, iedereen die mogelijk verbinding heeft met incidenten (technici, klantondersteuning, beheer, public relations, juridische zaken, enzovoort) moet weten waar het systeem moet worden gevonden, hoe een incident moet worden gegenereerd en hoe u toegang krijgt tot de gegevens indien nodig. Een van de manieren om te mislukken met het bijhouden van incidenten is door de mensen die het zal ondersteunen niet te weten hoe ze het systeem kunnen bereiken ('wat was de URL voor ons systeem opnieuw?') wanneer ze het nodig hebben.
In deze module gebruiken we de werkitemfunctionaliteit van Azure DevOps voor ons bijhoudsysteem.
Een gespreksbrug maken
Om enkele van de vragen in de voorgaande sectie 'Evalueer wat u weet' te beantwoorden en om het proces van incidentrespons te starten, moet u een manier hebben om met anderen te communiceren over het incident. Idealiter is dit een soort "teamsamenwerking" elektronisch medium voor gesprekken, hoewel telefoonbruggen ook werken. Vergadergesprekken/telefoonbruggen hebben minder de voorkeur, omdat het moeilijker is om de incidentcommunicatie met terugwerkende kracht te controleren (vandaar de eerder genoemde rol 'Scribe').
Welk medium u ook kiest, u moet ervoor zorgen dat u een uniek kanaal maakt dat strikt beperkt is tot discussie over dit incident en niets anders. Het is belangrijk om irrelevante discussies buiten dit kanaal te houden, omdat u de gegevens moet kunnen gebruiken en deze later in uw incidentbeoordeling moet kunnen analyseren.
In deze module gebruiken we Microsoft Teams als onze methode voor incidentcommunicatie.
De lancering van incidenttracking automatiseren
Laten we de stukken bekijken die we tot nu toe hebben samengesteld. We hebben een:
- Rooster van de mensen die worden gebeld (en een rotatie die voor hen is gedefinieerd).
- Rol die we kunnen toewijzen aan de personen die aan een incident werken.
- Specifieke plaats waar we het incident gaan declareren en bijhouden.
- Uniek kanaal voor de mensen die aan dat incident werken om erover te communiceren.
U kunt en moet het maken en beheren van al deze dingen zo veel mogelijk automatiseren. Wanneer er een urgent probleem optreedt, wilt u niet alle stappen uit uw hoofd hoeven te leren om een incident te melden, de juiste mensen erbij te betrekken en het proces te volgen. Het enige dat u echt wilt, is op de 'go'-knop drukken zodat het werk direct kan beginnen om het probleem aan te pakken.
Logic Apps gebruiken voor automatisering zonder code
Een manier om uw eerste antwoord te automatiseren, is met behulp van Logic Apps, waarmee u de taak van het plannen, automatiseren en organiseren van taken, bedrijfsprocessen en werkstromen kunt vereenvoudigen.
Logic Apps is een Azure-cloudservice voor het bouwen van integratieoplossingen. Het gebruikt -connectors om geautomatiseerde werkstromen te maken. triggers starten de Logic App wanneer een specifieke gebeurtenis plaatsvindt of wanneer gegevens voldoen aan opgegeven criteria. Acties zijn de bewerkingen die vervolgens worden uitgevoerd in de werkstroom van de logische app.
In ons voorbeeld gebruiken we de volgende logic app-connectors voor het bijhouden van incidenten:
- Azure Boards (een onderdeel van Azure DevOps), waarmee u problemen/incidenten kunt maken en bijhouden.
- Azure Storage-, waar u informatie kunt opslaan en ophalen over wie er wordt gebeld, zodat u de juiste personen kunt toewijzen om op het incident te reageren. In ons voorbeeld gebruiken we Azure Table Storage omdat het een zeer eenvoudige sleutelwaardearchief biedt waarmee u eenvoudig een lijst met technici en hun status op oproep kunt opslaan.
- Microsoft Teams, waarmee u een nieuw, uniek incidentkanaal kunt maken om de gesprekken van uw technische teams in realtime bij te houden wanneer ze communiceren over specifieke incidenten. Hiermee kunt u de interacties met betrekking tot de tijdlijn van gebeurtenissen later behouden bij het uitvoeren van een incidentbeoordeling.
Laten we dit nu allemaal aan elkaar koppelen met een logische app. Bekijk eerst de volledige app, zoals weergegeven in logic apps Designer, waarna we deze stapsgewijs doorlopen.
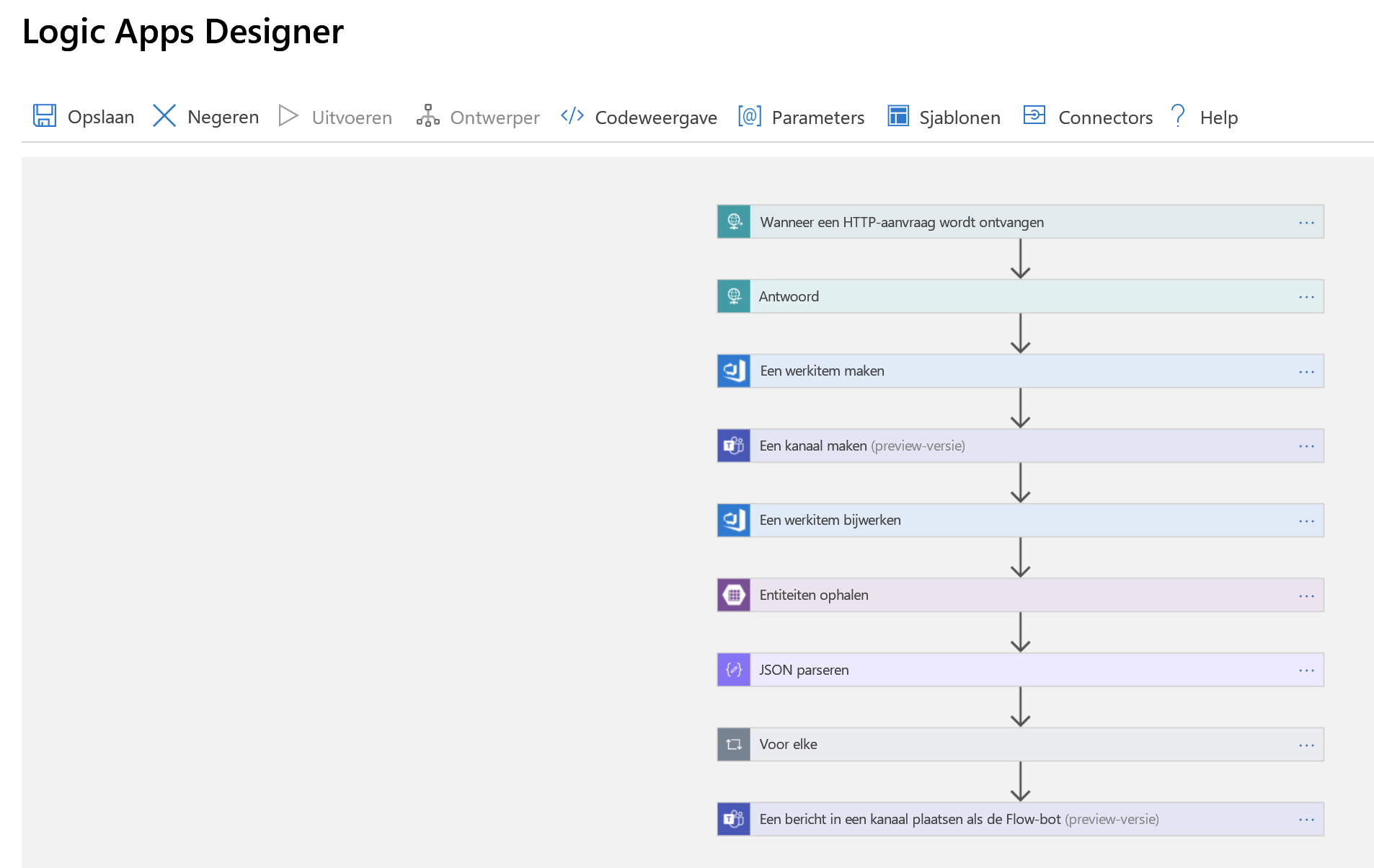
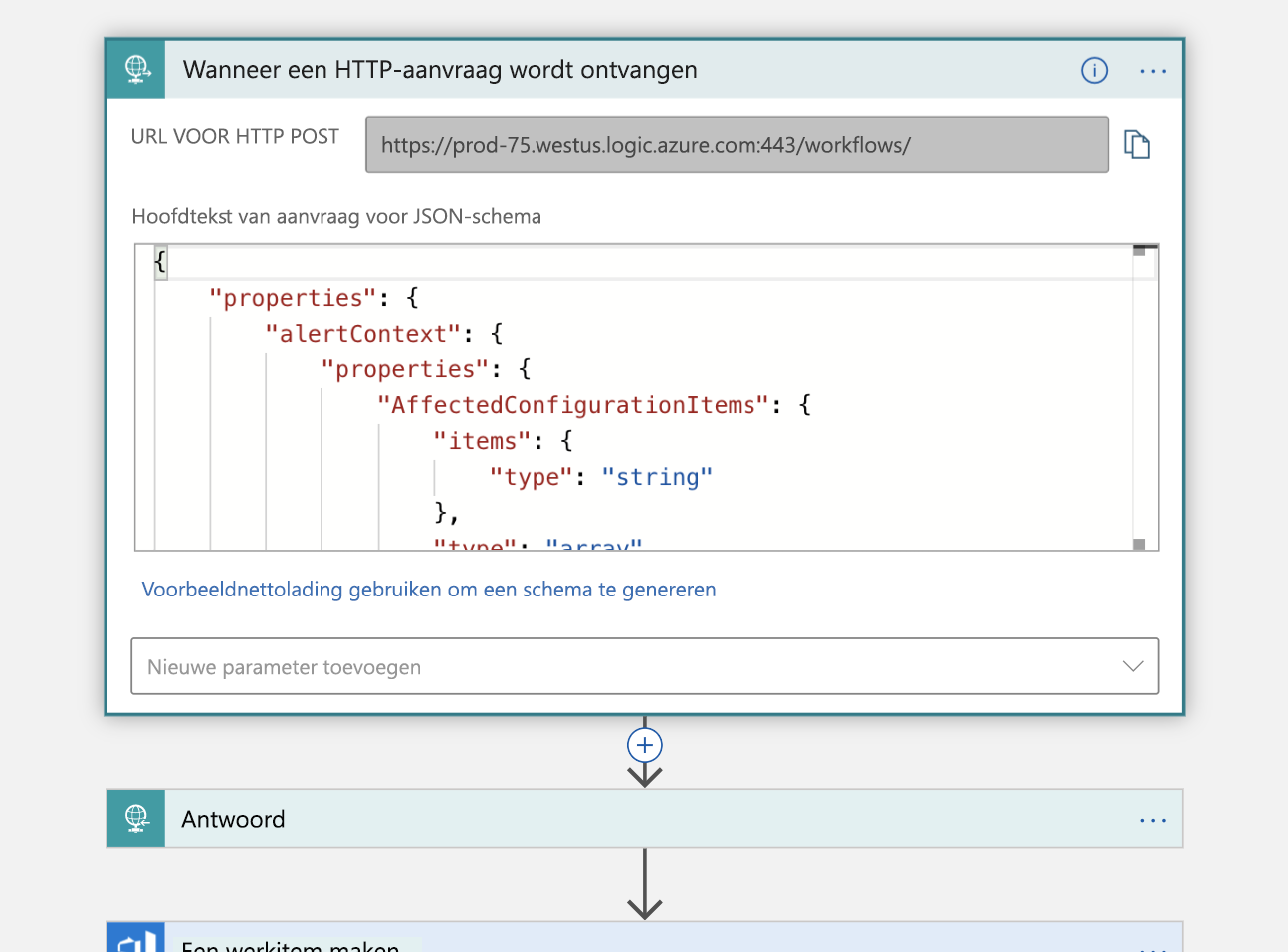
De eerste stap is het verwerken van een trigger, die HTTP-aanvraag die we hebben vermeld. Er wordt een HTTP POST-aanvraag verzonden naar onze logische app die een JSON-nettolading bevat met informatie over het incident dat we willen declareren. We parseren die payload en sturen een bevestiging terug dat we deze hebben ontvangen.
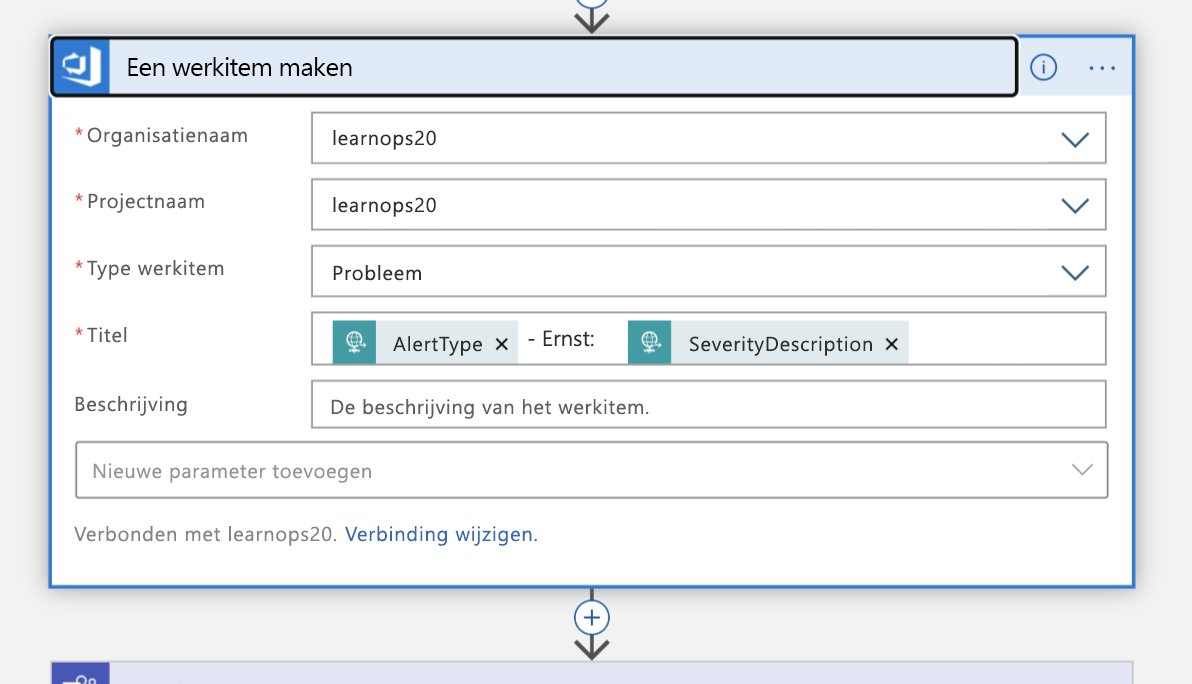
Met deze informatie maken we een nieuw werkitem in onze Azure DevOps-organisatie die dit incident vertegenwoordigt.
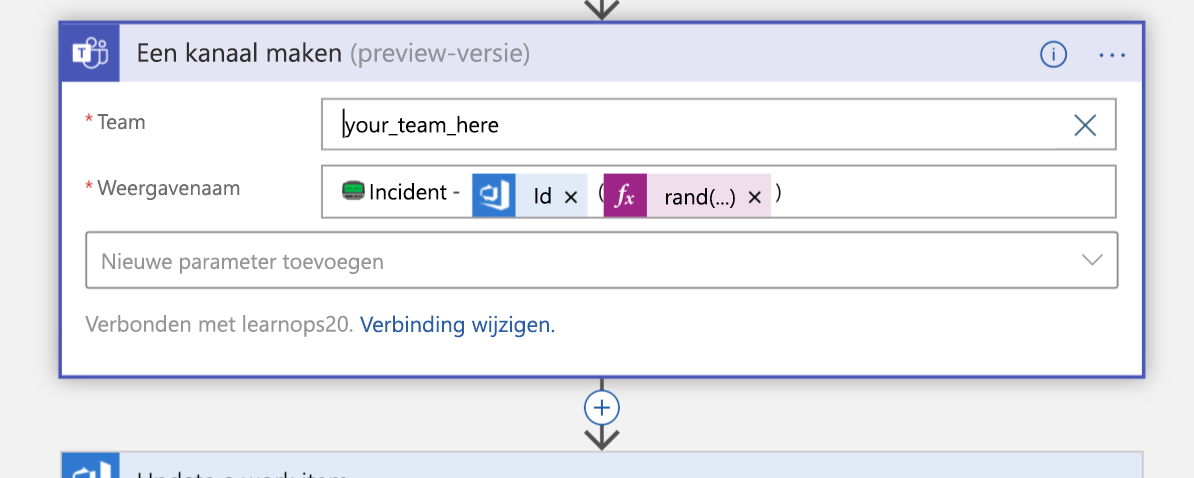
Vervolgens wordt er een nieuw Teams-kanaal voor het incident gemaakt:
Zodra het kanaal is gemaakt, wordt het werkitem dat we zojuist hebben gemaakt bijgewerkt met een koppeling naar het nieuwe kanaal. Hierdoor blijft alle informatie op dezelfde plaats (het werkitem) en kunnen mensen die het later bekijken, weten waar ze naartoe kunnen als ze aan dat kanaal willen deelnemen.
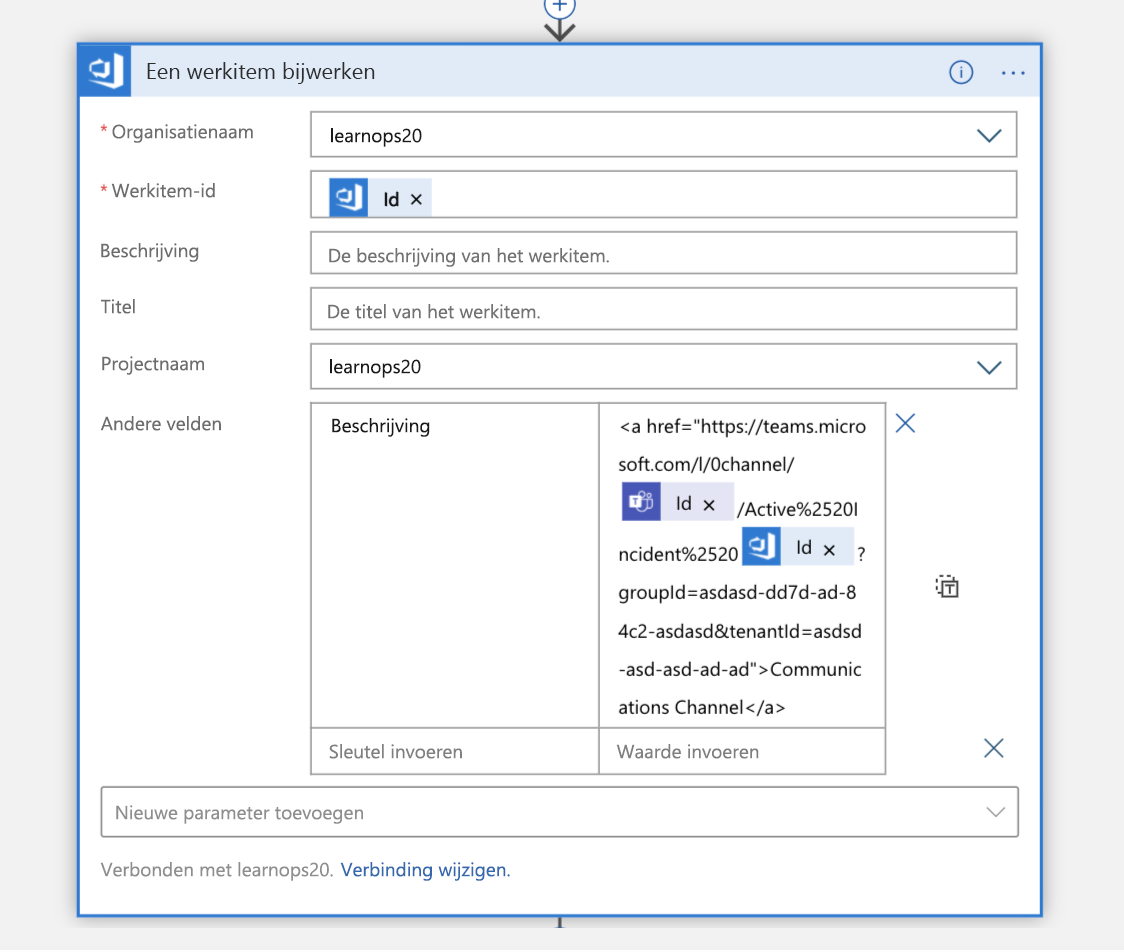
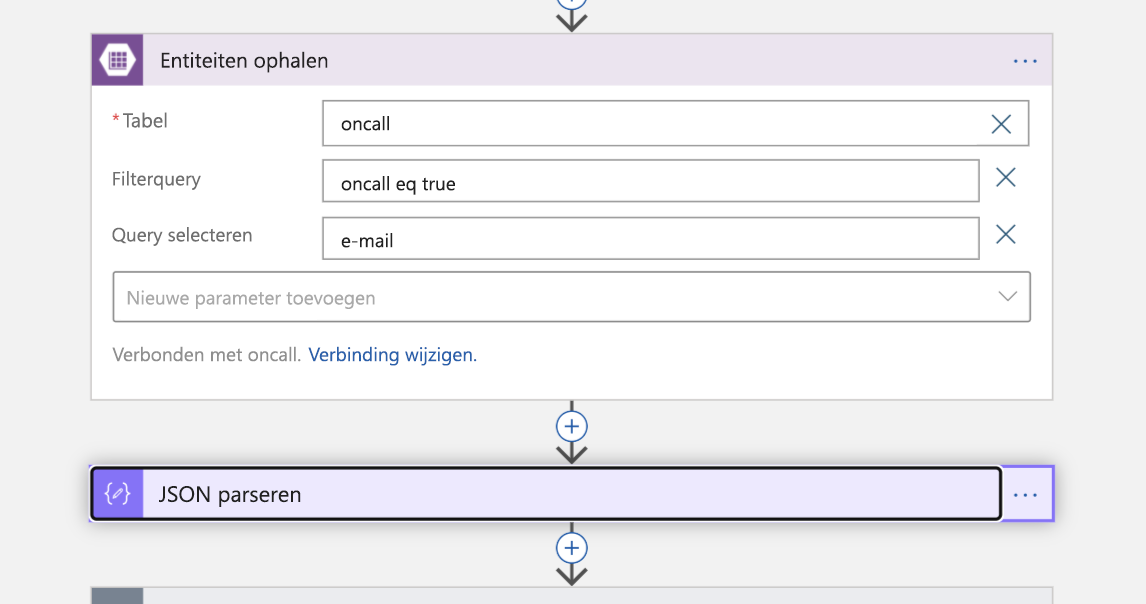
Nu is het tijd om de on-call persoon in de foto te brengen. We voeren een zoekopdracht uit in Azure Table Storage voor het e-mailadres van de technicus die wordt vermeld als on-call. Hiermee wordt een JSON-antwoord geretourneerd dat vervolgens wordt geparseerd.
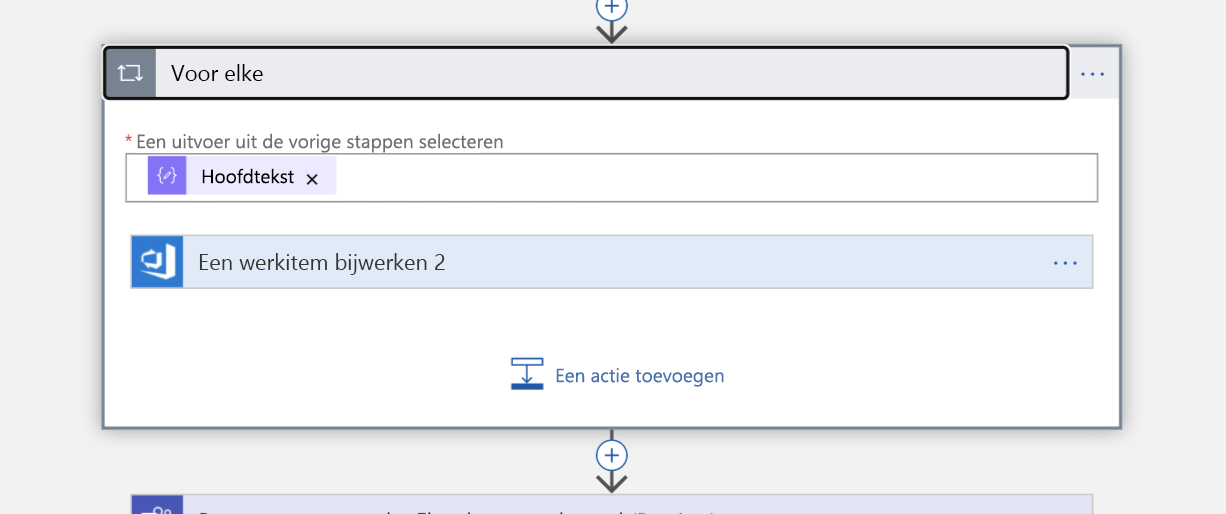
Omdat onze query een lijst retourneert, moeten we elk item in die lijst herhalen als de volgende stap. We wijzen het werkitem toe aan elke persoon (ze zijn nu 'eigenaren' van het incident).
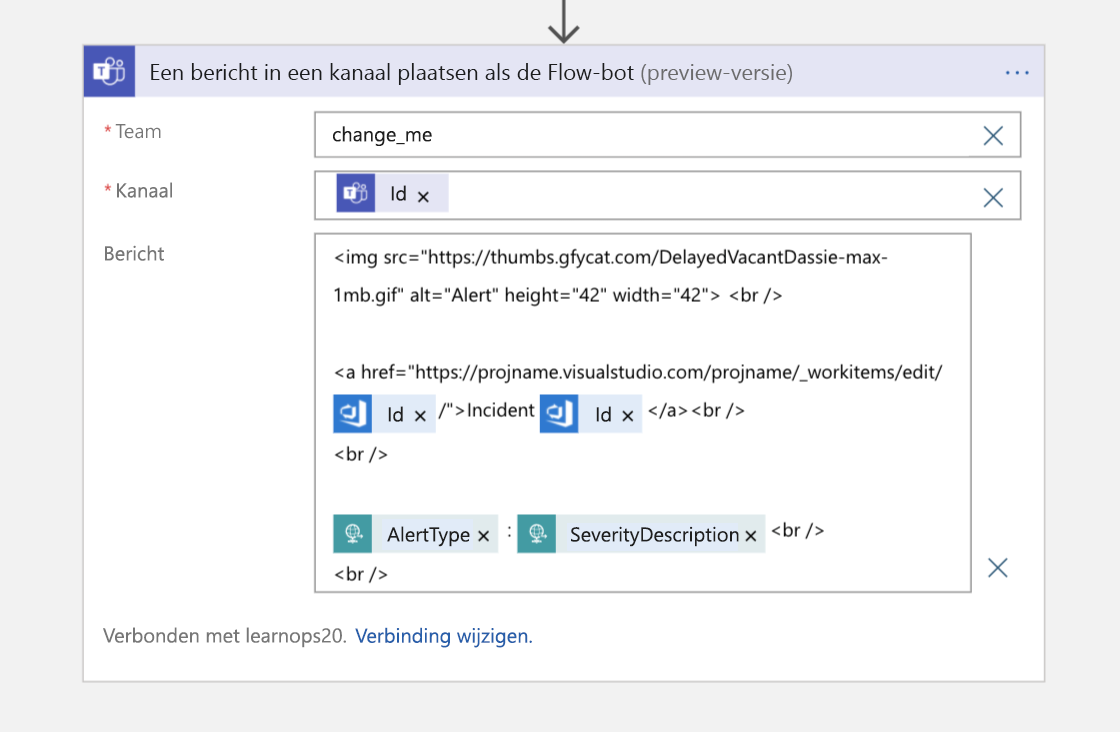
Vervolgens sturen we als laatste stap een bericht naar het Teams-kanaal met een aanwijzer terug naar het werkitem voor personen die deelnemen aan het kanaal en willen we weten waar de gezaghebbende informatie voor dat incident is opgeslagen.
Dat is slechts één voorbeeld van hoe we het instellen van de mechanismen voor incidenttracking en communicatie kunnen automatiseren. In de volgende les gaan we dieper in op aspecten van communicatie rond een incident.