Hoe Azure Data Factory werkt
Hier vindt u informatie over de onderdelen en onderling verbonden systemen van Azure Data Factory. U leert ook meer over hoe het werkt. Zo kunt u bepalen hoe u Azure Data Factory het beste kunt gebruiken om te voldoen aan de vereisten van uw organisatie.
Azure Data Factory is een verzameling onderling verbonden systemen die een end-to-end gegevensanalyseplatform bieden. In deze les krijgt u informatie over de volgende Azure Data Factory-functies:
- Verbinding maken en verzamelen
- Transformeren en verrijken
- Continue integratie en levering (CI/CD) en publiceren
- Controleren
U krijgt ook informatie over de belangrijkste onderdelen van Azure Data Factory. De volgende stappen moeten worden uitgevoerd:
- Pijplijnen
- Activiteiten
- Gegevenssets
- Gekoppelde services
- Gegevensstromen
- Integration Runtimes
Azure Data Factory-functies
Azure Data Factory bestaat uit verschillende functies die uw data engineers voorzien van een volledig platform voor gegevensanalyse.
Verbinding maken en verzamelen
Het eerste deel van het proces is het verzamelen van de vereiste gegevens uit de juiste gegevensbronnen. Deze kunnen zich op verschillende locaties bevinden, waaronder on-premises bronnen en in de cloud. De gegevens kunnen het volgende zijn:
- gestructureerd
- Ongestructureerd
- semi-gestructureerd
Bovendien kunnen deze verschillende gegevens op verschillende snelheden en intervallen aankomen. Met Azure Data Factory kunt u de kopieeractiviteit gebruiken om gegevens van verschillende bronnen naar één gecentraliseerd gegevensarchief in de cloud te verplaatsen. Nadat u de gegevens hebt gekopieerd, gebruikt u andere systemen om deze te transformeren en te analyseren.
De kopieeractiviteit voert de volgende stappen op hoog niveau uit:
Gegevens lezen uit het brongegevensarchief.
Voer de volgende taken uit op de gegevens:
- Serialisatie/deserialisatie
- Compressie/decompressie
- Toewijzen van kolommen
Notitie
Er zijn mogelijk extra taken.
Gegevens schrijven naar het doelgegevensarchief (ook wel de sink genoemd).
Dit proces wordt samengevat in de volgende afbeelding:

Transformeren en verrijken
Nadat u de gegevens naar een centrale cloudlocatie hebt gekopieerd, kunt u de gegevens naar behoefte verwerken en transformeren. U gebruikt azure Data Factory-toewijzingsgegevensstromen om dit te bereiken. Met gegevensstromen kunt u grafieken voor gegevenstransformatie maken die worden uitgevoerd in Spark. U hoeft echter geen inzicht te hebben in Spark-clusters of Spark-programmering.
Tip
Hoewel dit niet nodig is, kunt u uw transformaties liever handmatig codeeren. Zo ja, dan ondersteunt Azure Data Factory externe activiteiten voor het uitvoeren van uw transformaties.
CI/CD en publiceren
Met ondersteuning voor CI/CD kunt u uw ETL-processen stapsgewijs ontwikkelen en leveren voordat u publiceert. Azure Data Factory biedt CI/CD van uw gegevenspijplijnen met behulp van:
- Azure DevOps
- GitHub
Notitie
Continue integratie betekent dat elke wijziging die in uw codebasis is aangebracht, automatisch zo snel mogelijk wordt getest. Continue levering volgt deze test en pusht wijzigingen in een faserings- of productiesysteem.
Nadat Azure Data Factory de onbewerkte gegevens heeft verfijnd, kunt u de gegevens laden in de analyse-engine waartoe uw zakelijke gebruikers toegang hebben vanuit hun business intelligence-hulpprogramma's, waaronder:
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Bijhouden
Nadat u uw pijplijn voor gegevensintegratie hebt gebouwd en geïmplementeerd, is het belangrijk dat u uw geplande activiteiten en pijplijnen kunt bewaken. Hiermee kunt u succes- en foutpercentages bijhouden. Azure Data Factory biedt ondersteuning voor pijplijnbewaking met behulp van een van de volgende opties:
- Azure Monitor
- API
- PowerShell
- Azure Monitor-logboeken
- Statusvensters in Azure Portal
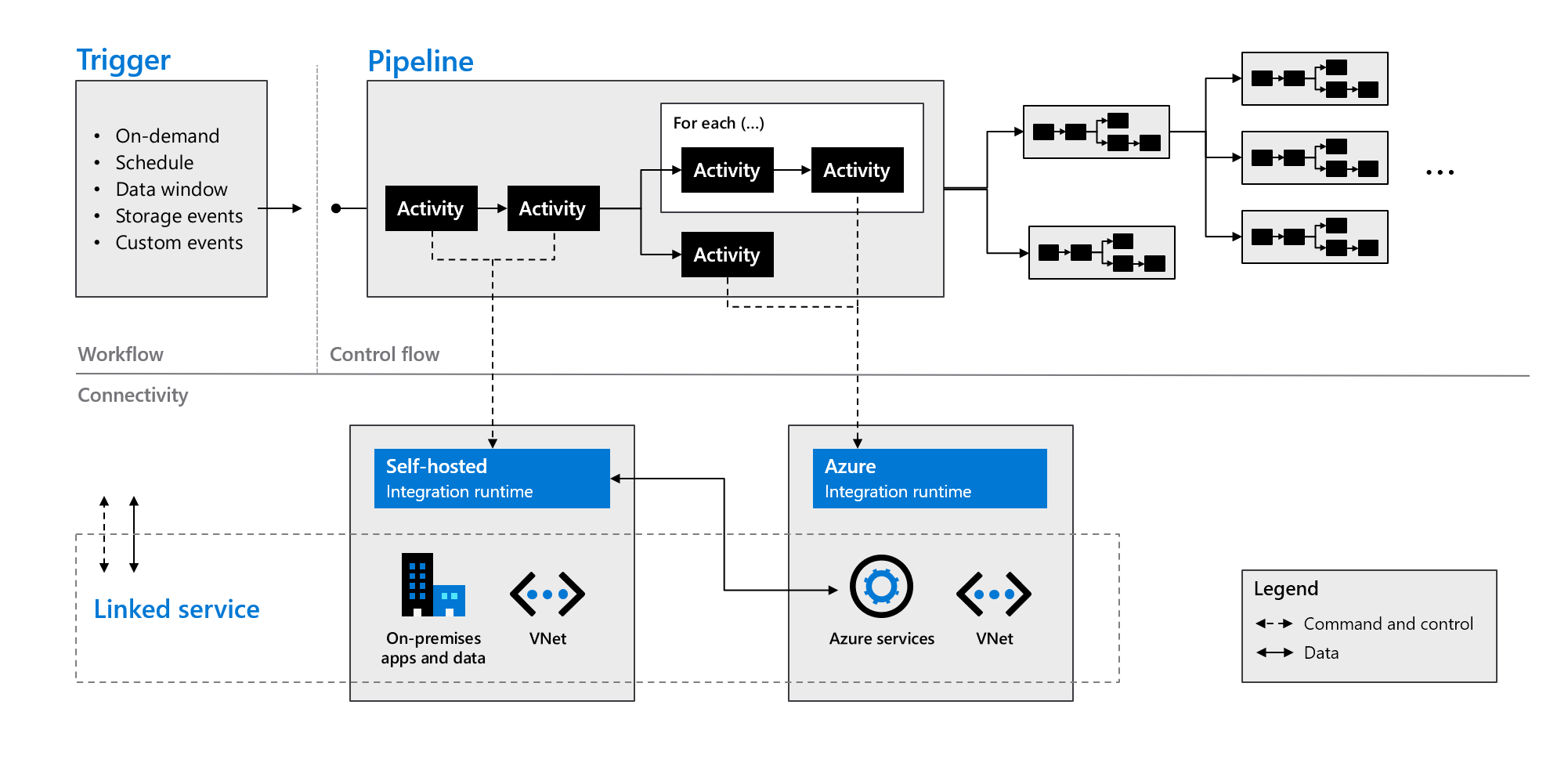
Azure Data Factory-onderdelen
Azure Data Factory bestaat uit de onderdelen die in de volgende tabel worden beschreven:
| Onderdeel | Beschrijving |
|---|---|
| Pijplijnen | Een logische groepering van activiteiten die een specifieke werkeenheid uitvoeren. Deze activiteiten voeren samen een taak uit. Het voordeel van het gebruik van een pijplijn is dat u de activiteiten eenvoudiger kunt beheren als een set in plaats van als afzonderlijke items. |
| Activiteiten | Eén verwerkingsstap in een pijplijn. Azure Data Factory ondersteunt drie soorten activiteiten: gegevensverplaatsing, gegevenstransformatie en controleactiviteiten. |
| Gegevenssets | Vertegenwoordig gegevensstructuren in uw gegevensarchieven. Deze verwijzen naar (of verwijzen) naar de gegevens die u in uw activiteiten wilt gebruiken als invoer of uitvoer. |
| Gekoppelde services | Definieer de vereiste verbindingsgegevens die nodig zijn voor Azure Data Factory om verbinding te maken met externe resources, zoals een gegevensbron. Azure Data Factory gebruikt deze voor twee doeleinden: om een gegevensarchief of een rekenresource weer te geven. |
| Gegevensstromen | Stel uw data engineers in staat om logica voor gegevenstransformatie te ontwikkelen zonder code te hoeven schrijven. Gegevensstromen worden uitgevoerd als activiteiten in Azure Data Factory-pijplijnen die gebruikmaken van uitgeschaalde Apache Spark-clusters. |
| Integration Runtimes | Azure Data Factory maakt gebruik van de rekeninfrastructuur om de volgende mogelijkheden voor gegevensintegratie te bieden in verschillende netwerkomgevingen: gegevensstroom, gegevensverplaatsing, activiteitsverzending en uitvoering van SSIS-pakketten. In Azure Data Factory biedt een integratieruntime de brug tussen de activiteit en gekoppelde services. |
Zoals aangegeven in de volgende afbeelding, werken deze onderdelen samen om een volledig end-to-end platform voor data engineers te bieden. Met Data Factory kunt u het volgende doen:
- Stel triggers op aanvraag in en plan gegevensverwerking op basis van uw behoeften.
- Koppel een pijplijn aan een trigger of start deze handmatig zo nodig.
- Verbinding maken gekoppelde services (zoals on-premises apps en gegevens) of Azure-services via integratieruntimes.
- Bewaak al uw pijplijnuitvoeringen op systeemeigen wijze in de Gebruikerservaring van Azure Data Factory of met behulp van Azure Monitor.