Onbalans van gegevens
Wanneer onze gegevenslabels meer dan een andere categorie hebben, zeggen we dat we een onevenwichtige gegevens hebben. Denk er bijvoorbeeld aan dat we in ons scenario objecten proberen te identificeren die zijn gevonden door dronesensoren. Onze gegevens zijn onevenwichtig omdat er enorm verschillende aantallen wandelaars, dieren, bomen en rotsen in onze trainingsgegevens zijn. We kunnen dit zien door deze gegevens te tabuleren:
| Label | Wandelaar | Dierlijke | Structuur | Steen |
|---|---|---|---|---|
| Tellen | 400 | 200 | 800 | 800 |
Of plotten:
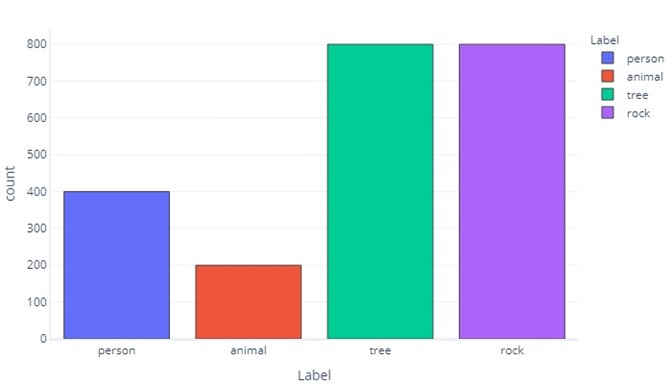
Let op hoe de meeste gegevens bomen of rotsen zijn. Een evenwichtige gegevensset heeft dit probleem niet.
Als we bijvoorbeeld proberen te voorspellen of een object een wandelaar, dier, boom of steen is, willen we idealiter een gelijk aantal categorieën, zoals:
| Label | Wandelaar | Dierlijke | Structuur | Steen |
|---|---|---|---|---|
| Tellen | 550 | 550 | 550 | 550 |
Als we gewoon proberen te voorspellen of een object een wandelaar was, willen we idealiter een gelijk aantal wandelaar en niet-wandelaarobjecten:
| Label | Wandelaar | Niet-wandelaar |
|---|---|---|
| Tellen | 1100 | 1100 |
Waarom is er sprake van onevenwichtigheid in gegevens?
Gegevensonbalansen zijn belangrijk omdat modellen deze onevenwichtigheden kunnen nabootsen wanneer het niet wenselijk is. Stel dat we een logistiek regressiemodel hebben getraind om objecten te identificeren als wandelaar of niet-wandelaar. Als de trainingsgegevens sterk worden gedomineerd door 'wandelaar'-labels, zou training het model vertekenen om bijna altijd 'wandelaar'-labels te retourneren. In de echte wereld kunnen we echter merken dat de meeste dingen die de drones tegenkomen bomen zijn. Het vertekende model zou waarschijnlijk veel van deze bomen labelen als wandelaars.
Dit verschijnsel vindt plaats omdat kostenfuncties standaard bepalen of het juiste antwoord is gegeven. Dit betekent dat voor een vertekende gegevensset de eenvoudigste manier voor een model om optimale prestaties te bereiken, kan zijn om de geleverde functies virtueel te negeren en altijd of bijna altijd hetzelfde antwoord te retourneren. Dit kan verwoestende gevolgen hebben. Stel dat ons wandelaar-/niet-wandelaarmodel is getraind op gegevens waarbij slechts één per 1000 steekproeven een wandelaar bevat. Een model dat heeft geleerd om 'not-hiker' elke keer te retourneren, heeft een nauwkeurigheid van 99,9%! Deze statistiek lijkt uitstekend te zijn, maar het model is nutteloos, omdat het ons nooit zal vertellen of iemand op de berg staat en we zullen ze niet redden als er een lawine optreedt.
Bias in een verwarringsmatrix
Verwarringsmatrices zijn de sleutel tot het identificeren van onevenwichtige gegevens of modelvooroordelen. In een ideaal scenario hebben de testgegevens een ongeveer even aantal labels en worden de voorspellingen van het model ook ongeveer verspreid over de labels. Voor 1000 voorbeelden ziet een model dat onbevoorrecht is, maar vaak antwoorden verkeerd krijgt, er ongeveer als volgt uit:
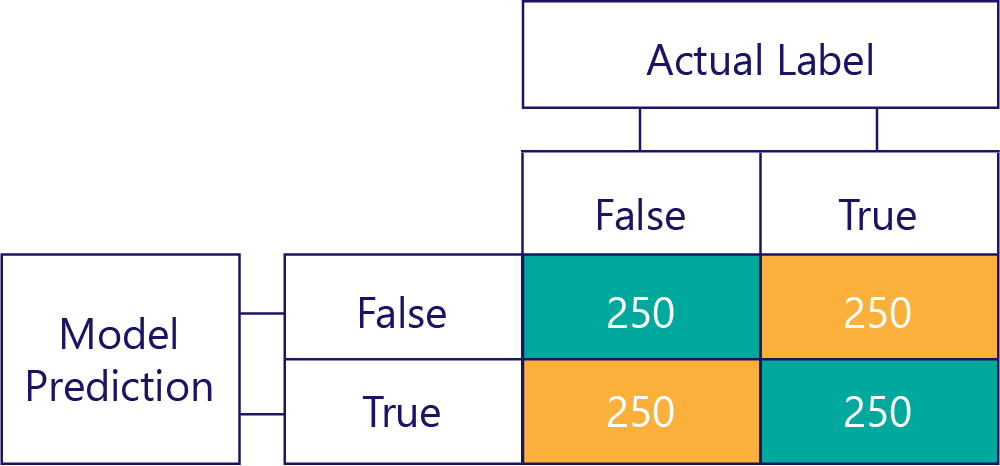
We kunnen zien dat de invoergegevens onbevoordeeld zijn, omdat de rijsom hetzelfde is (500 elk), waarmee wordt aangegeven dat de helft van de labels waar is en de helft onwaar is. Op dezelfde manier kunnen we zien dat het model onbevoorwaardeerde antwoorden geeft, omdat het de helft van de tijd waar retourneert en de andere helft van de tijd onwaar is.
Biased data bevat daarentegen meestal één type label, zoals:
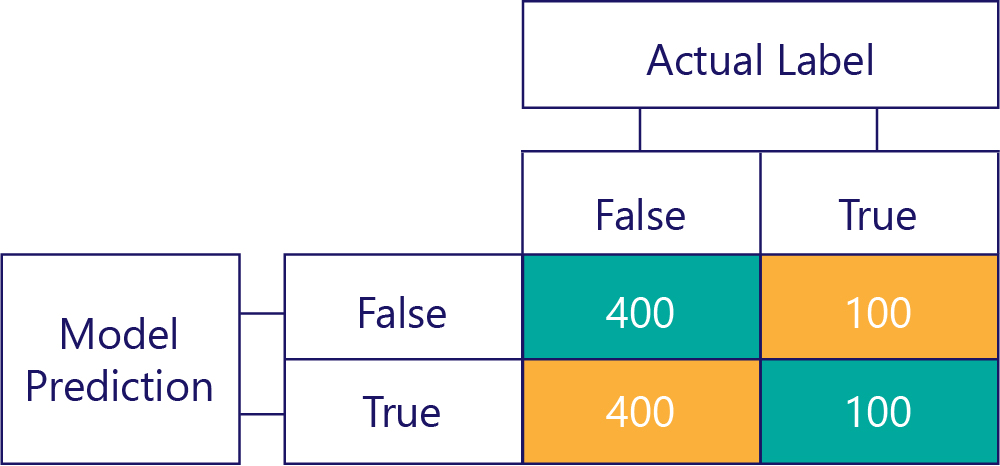
Op dezelfde manier produceert een vertekend model meestal één soort label, zoals:
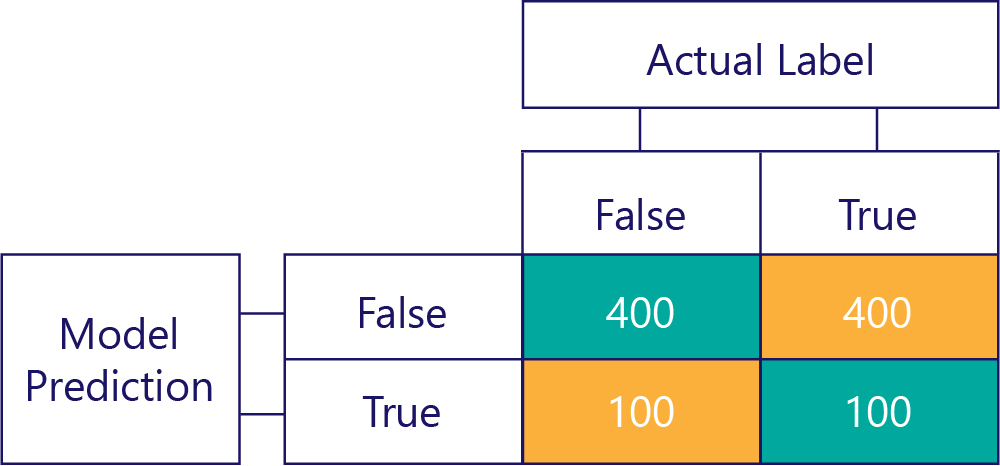
Modelvooroordelen zijn niet nauwkeurig
Houd er rekening mee dat vooroordelen niet nauwkeurig zijn. Sommige van de voorgaande voorbeelden zijn bijvoorbeeld vooroordelen en andere niet, maar ze geven allemaal een model weer waarmee het antwoord 50% van de tijd correct wordt opgehaald. Als extreem voorbeeld toont de onderstaande matrix een onvooruitgetekend model dat onnauwkeurig is:
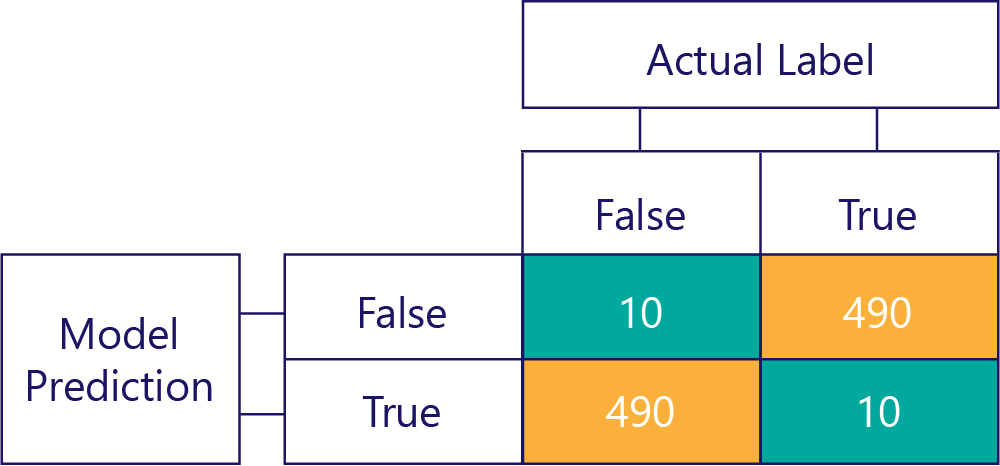
U ziet hoe het aantal rijen en kolommen allemaal wordt toegevoegd aan 500, wat aangeeft dat beide gegevens evenwichtig zijn en dat het model geen vooroordelen heeft. Dit model krijgt echter bijna alle antwoorden onjuist.
Natuurlijk is ons doel om modellen nauwkeurig en onbevoorwaardeerd te laten zijn, zoals:
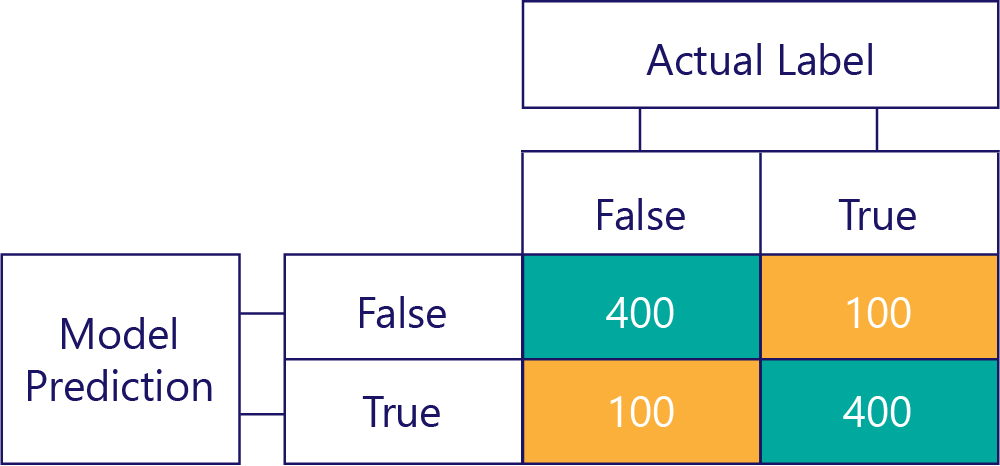
... maar we moeten ervoor zorgen dat onze nauwkeurige modellen niet worden vooroordelen, simpelweg omdat de gegevens:
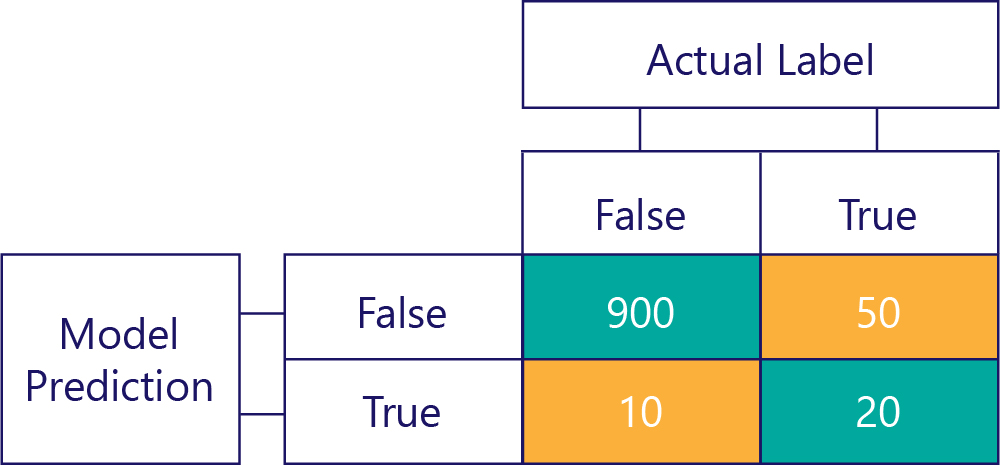
In dit voorbeeld ziet u hoe de werkelijke labels meestal onwaar zijn (linkerkolom, waarbij een onbalans van gegevens wordt weergegeven) en dat het model ook vaak onwaar retourneert (bovenste rij, met modelvooroordelen). Dit model is niet goed in het correct geven van 'True'-antwoorden.
De gevolgen van onevenwichtige gegevens vermijden
Enkele van de eenvoudigste manieren om de gevolgen van onevenwichtige gegevens te voorkomen, zijn:
- Vermijd dit door betere gegevensselectie.
- Uw gegevens opnieuwsampleen, zodat deze duplicaten van de minderheidslabelklasse bevatten.
- Breng wijzigingen aan in de kostenfunctie, zodat deze prioriteit geeft aan minder algemene labels. Als er bijvoorbeeld een verkeerde reactie op Tree wordt gegeven, kan de kostenfunctie 1 retourneren; als het verkeerde antwoord op Hiker wordt gedaan, kan het 10 retourneren.
In de volgende oefening gaan we deze methoden verkennen.