Gestructureerd streamen van Spark beschrijven
Spark structured streaming is een populair platform voor in-memory verwerking. Het heeft een uniform paradigma voor batch en streaming. Alles wat u leert en gebruikt voor batch, kunt u gebruiken voor streaming, zodat u eenvoudig kunt groeien van batchverwerking van uw gegevens tot het streamen van uw gegevens. Spark Streaming is gewoon een engine die op Apache Spark wordt uitgevoerd.

Structured Streaming maakt een langlopende query waarin u bewerkingen toepast op de invoergegevens, zoals selectie, projectie, aggregatie, vensters en het samenvoegen van het streaming DataFrame met referentie-DataFrames. Vervolgens voert u de resultaten uit naar bestandsopslag (Azure Storage-blobs of Data Lake Storage) of naar een gegevensarchief met behulp van aangepaste code (zoals SQL Database of Power BI). Structured Streaming biedt ook uitvoer naar de console voor het lokaal opsporen van fouten en naar een tabel in het geheugen, zodat u de gegevens kunt zien die zijn gegenereerd voor foutopsporing in HDInsight.
Streams als tabellen
Gestructureerde Spark-streaming vertegenwoordigt een gegevensstroom als een tabel die niet-gebonden is, dat wil gezegd, de tabel blijft groeien naarmate er nieuwe gegevens binnenkomen. Deze invoertabel wordt continu verwerkt door een langlopende query en de resultaten die naar een uitvoertabel worden verzonden:

In Structured Streaming komen gegevens binnen op het systeem en worden ze onmiddellijk opgenomen in een invoertabel. U schrijft query's (met behulp van dataframe- en gegevensset-API's) die bewerkingen uitvoeren op deze invoertabel. De queryuitvoer levert een andere tabel op, de resultatentabel. De resultatentabel bevat de resultaten van uw query, waaruit u gegevens tekent voor een extern gegevensarchief, zoals een relationele database. De timing van wanneer gegevens uit de invoertabel worden verwerkt, wordt bepaald door het triggerinterval. Standaard is het triggerinterval nul, dus Structured Streaming probeert de gegevens te verwerken zodra deze binnenkomen. In de praktijk betekent dit dat zodra Structured Streaming klaar is met het verwerken van de uitvoering van de vorige query, er een andere verwerkingsbewerking wordt gestart op nieuwe ontvangen gegevens. U kunt de trigger zo configureren dat deze met een interval wordt uitgevoerd, zodat de streaminggegevens worden verwerkt in batches op basis van tijd.
De gegevens in de resultatentabellen bevatten mogelijk alleen de gegevens die nieuw zijn sinds de laatste keer dat de query is verwerkt (toevoegmodus) of de tabel kan telkens worden vernieuwd wanneer er nieuwe gegevens zijn, zodat de tabel alle uitvoergegevens bevat sinds de streamingquery is gestart (volledige modus).
Toevoegmodus
In de toevoegmodus zijn alleen de rijen toegevoegd aan de resultatentabel omdat de laatste queryuitvoering aanwezig is in de resultatentabel en naar externe opslag zijn geschreven. Met de eenvoudigste query worden bijvoorbeeld alleen alle gegevens uit de invoertabel gekopieerd naar de resultatentabel, ongewijzigd. Telkens wanneer een triggerinterval is verstreken, worden de nieuwe gegevens verwerkt en worden de rijen weergegeven die aangeven dat nieuwe gegevens worden weergegeven in de resultatentabel.
Denk aan een scenario waarin u gegevens over aandelenkoersen verwerkt. Stel dat de eerste trigger één gebeurtenis heeft verwerkt op het moment 00:01 voor MSFT-aandelen met een waarde van 95 dollar. In de eerste trigger van de query wordt alleen de rij met tijd 00:01 weergegeven in de resultatentabel. Op het moment 00:02 wanneer een andere gebeurtenis binnenkomt, is de enige nieuwe rij de rij met tijd 00:02 en bevat de resultatentabel dus slechts die ene rij.
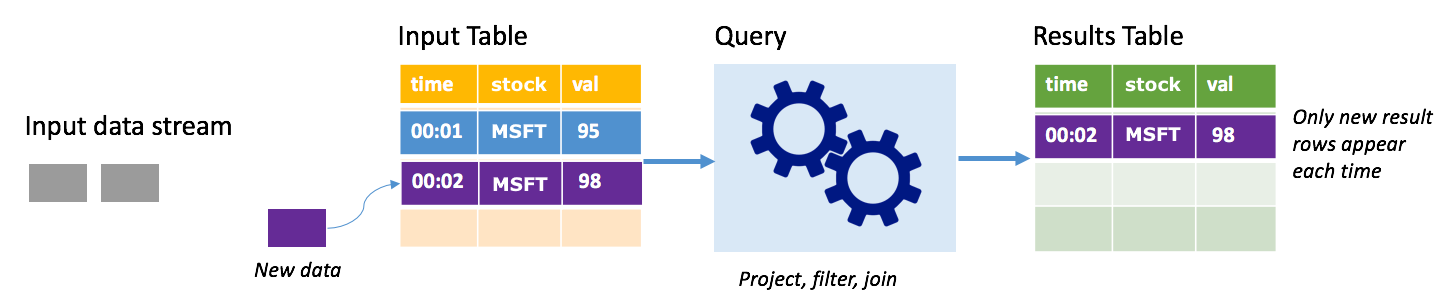
Wanneer u de toevoegmodus gebruikt, past uw query projecties toe (waarbij u de kolommen selecteert waar het om gaat), filteren (alleen rijen kiezen die voldoen aan bepaalde voorwaarden) of samenvoegen (de gegevens uitbreiden met gegevens uit een statische opzoektabel). Met de toevoegmodus kunt u eenvoudig alleen de relevante nieuwe gegevens naar externe opslag pushen.
Volledige modus
Houd rekening met hetzelfde scenario, deze keer met behulp van de volledige modus. In de volledige modus wordt de volledige uitvoertabel vernieuwd op elke trigger, zodat de tabel gegevens bevat die niet alleen afkomstig zijn van de meest recente triggeruitvoering, maar van alle uitvoeringen. U kunt de volledige modus gebruiken om de gegevens ongewijzigd van de invoertabel naar de resultatentabel te kopiëren. Bij elke geactiveerde uitvoering worden de nieuwe resultaatrijen samen met alle vorige rijen weergegeven. In de tabel met uitvoerresultaten worden uiteindelijk alle gegevens opgeslagen die zijn verzameld sinds de query is gestart en zou u uiteindelijk onvoldoende geheugen meer hebben. De volledige modus is bedoeld voor gebruik met statistische query's die de binnenkomende gegevens op een bepaalde manier samenvatten, dus bij elke trigger wordt de resultatentabel bijgewerkt met een nieuwe samenvatting.
Stel dat er tot nu toe vijf seconden aan gegevens zijn verwerkt en dat het tijd is om de gegevens voor de zesde seconde te verwerken. De invoertabel bevat gebeurtenissen voor tijd 00:01 en tijd 00:03. Het doel van deze voorbeeldquery is om de gemiddelde prijs van het aandeel om de vijf seconden te geven. Bij de implementatie van deze query wordt een aggregatie toegepast die alle waarden gebruikt die binnen elk venster van vijf seconden vallen, de aandelenkoers gemiddelden en een rij produceert voor de gemiddelde aandelenkoers gedurende dat interval. Aan het einde van het eerste venster van 5 seconden zijn er twee tuples: (00:01, 1, 95) en (00:03, 1, 98). Voor het venster 00:00-00:05 produceert de aggregatie dus een tuple met de gemiddelde aandelenkoers van $ 96,50. In het volgende venster van 5 seconden is er slechts één gegevenspunt op het moment 00:06, dus de resulterende aandelenkoers is $ 98. Op tijd 00:10, met behulp van de volledige modus, bevat de resultatentabel de rijen voor zowel Windows 00:00-00:05 als 00:05-00:10 omdat de query alle samengevoegde rijen uitvoert, niet alleen de nieuwe rijen. Daarom blijft de resultatentabel groeien naarmate er nieuwe vensters worden toegevoegd.
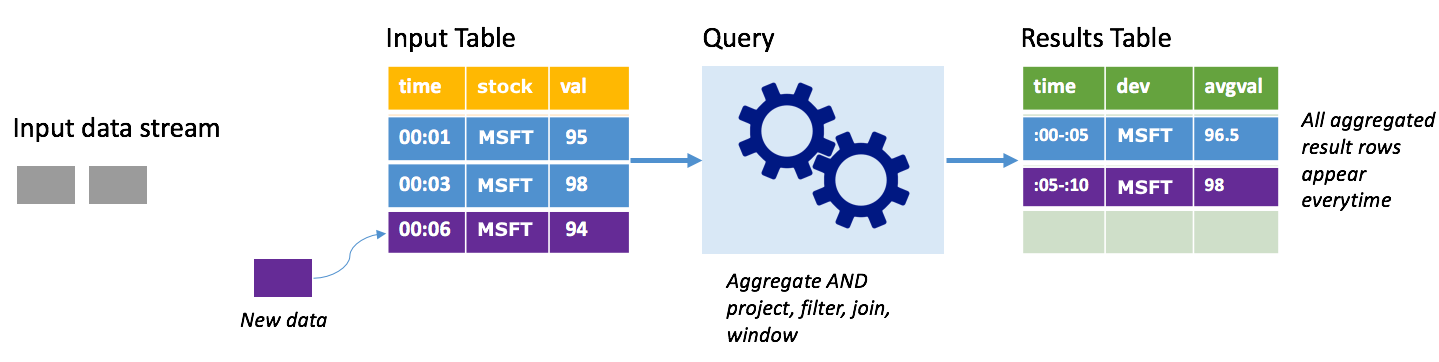
Niet alle query's die de volledige modus gebruiken, zorgen ervoor dat de tabel zonder grenzen groeit. Houd in het vorige voorbeeld rekening met het gemiddelde van de aandelenkoers per venster, in plaats van de gemiddelde koers per venster, in plaats daarvan op voorraad. De resultatentabel bevat een vast aantal rijen (één per voorraad) met de gemiddelde aandelenkoers voor de aandelen voor alle gegevenspunten die van dat apparaat zijn ontvangen. Wanneer er nieuwe aandelenkoersen worden ontvangen, wordt de resultatentabel bijgewerkt, zodat de gemiddelden in de tabel altijd actueel zijn.
Wat zijn de voordelen van gestructureerd streamen met Spark?
In de financiële sector is de timing van transacties zeer belangrijk. In een aandelenhandel bijvoorbeeld het verschil tussen wanneer de aandelenhandel plaatsvindt op de aandelenmarkt of wanneer u de transactie ontvangt, of wanneer de gegevens alle zaken lezen. Voor financiële instellingen zijn ze afhankelijk van deze kritieke gegevens en de bijbehorende timing.
Gebeurtenistijd, late gegevens en watermerken
Spark structured streaming kent het verschil tussen een gebeurtenistijd en de tijd waarop de gebeurtenis door het systeem is verwerkt. Elke gebeurtenis is een rij in de tabel en gebeurtenistijd is een kolomwaarde in de rij. Hierdoor kunnen aggregaties op basis van vensters (bijvoorbeeld het aantal gebeurtenissen elke minuut) slechts een groepering en aggregatie in de kolom gebeurtenistijd zijn. Elk tijdvenster is een groep en elke rij kan deel uitmaken van meerdere vensters/groepen. Daarom kunnen dergelijke op gebeurtenissen gebaseerde aggregatiequery's consistent worden gedefinieerd op zowel een statische gegevensset als op een gegevensstroom, waardoor het leven van een data engineer veel eenvoudiger wordt.
Bovendien verwerkt dit model op natuurlijke wijze gegevens die later dan verwacht zijn aangekomen op basis van de gebeurtenistijd. Spark heeft volledige controle over het bijwerken van oude aggregaties wanneer er late gegevens zijn, en het opschonen van oude aggregaties om de grootte van tussenliggende statusgegevens te beperken. Bovendien ondersteunt Spark 2.1 watermerken, waarmee u de drempelwaarde voor late gegevens kunt opgeven en de engine de oude status kan opschonen.
Flexibiliteit om recente gegevens of alle gegevens te uploaden
Zoals besproken in de vorige les, kunt u ervoor kiezen om de modus Toevoegen of De modus Voltooid te gebruiken bij het werken met gestructureerde Spark-streaming, zodat uw resultatentabel alleen de meest recente gegevens of alle gegevens bevat.
Ondersteunt het verplaatsen van microbatches naar continue verwerking
Door het triggertype van een Spark-query te wijzigen, kunt u overstappen van het verwerken van microbatches naar continue verwerking zonder andere wijzigingen in uw framework. Hier volgen de verschillende soorten triggers die door Spark worden ondersteund.
- Niet opgegeven, dit is de standaardwaarde. Als er geen trigger expliciet is ingesteld, wordt de query uitgevoerd in microbatches en wordt deze continu verwerkt.
- Microbatch met vaste interval. De query wordt gestart met terugkerende intervallen die door de gebruiker zijn ingesteld. Als er geen nieuwe gegevens worden ontvangen, wordt er geen microbatchproces uitgevoerd.
- Eenmalige microbatch. De query voert één microbatch uit en stopt vervolgens. Dit is handig als u alle gegevens wilt verwerken sinds de vorige microbatch en kostenbesparingen kunt bieden voor taken die niet continu hoeven te worden uitgevoerd.
- Doorlopend met een vast controlepuntinterval. De query wordt uitgevoerd in een nieuwe modus voor continue verwerking met lage latentie met lage (~1 ms) end-to-end latentie met ten minste eenmaal fouttolerantiegaranties. Dit is vergelijkbaar met de standaardwaarde, die precies eenmaal garanties kan bereiken, maar alleen latenties van ~100 ms op het hoogste moment bereikt.
Batch- en streamingtaken combineren
Naast het vereenvoudigen van de verplaatsing van batch- naar streamingtaken, kunt u ook batch- en streamingtaken combineren. Dit is vooral handig wanneer u historische gegevens op lange termijn wilt gebruiken om toekomstige trends te voorspellen tijdens het verwerken van realtime informatie. Voor aandelen kunt u de prijs van het aandeel in de afgelopen vijf jaar naast de huidige prijs bekijken om wijzigingen te voorspellen die zijn aangebracht rond jaarlijkse of kwartaalomzetaankondigingen.
Tijdvensters voor gebeurtenissen
Mogelijk wilt u gegevens vastleggen in vensters, zoals een hoge aandelenkoers en een lage aandelenkoers binnen een venster van één dag, of een periode van één minuut, ongeacht het interval dat u kiest en dat door Spark gestructureerde streaming ook wordt ondersteund. Overlappende vensters worden ook ondersteund.
Controlepunten voor herstel van fouten
In het geval van een fout of opzettelijk afsluiten kunt u de vorige voortgang en status van een vorige query herstellen en doorgaan waar deze was gebleven. Dit wordt gedaan met behulp van controlepunten en write-ahead-logboeken. U kunt een query configureren met een controlepuntlocatie en de query slaat alle voortgangsgegevens op (dat wil bijvoorbeeld het bereik van offsets dat in elke trigger wordt verwerkt) en de actieve aggregaties naar de locatie van het controlepunt. Deze controlepuntlocatie moet een pad zijn in een met HDFS compatibel bestandssysteem en kan worden ingesteld als een optie in DataStreamWriter bij het starten van een query.