Oefening: Een machine learning-model trainen
U hebt sensorgegevens verzameld van productieapparaten die in orde zijn en apparaten die zijn mislukt. U wilt nu Model Builder gebruiken om een machine learning-model te trainen dat voorspelt of een machine al dan niet zal mislukken. Door machine learning te gebruiken om de bewaking van deze apparaten te automatiseren, kunt u uw bedrijf geld besparen door tijdig en betrouwbaarder onderhoud te bieden.
Een nieuw machine learning-modelitem (ML.NET) toevoegen
Als u het trainingsproces wilt starten, moet u een nieuw Machine Learning Model-item (ML.NET) toevoegen aan een nieuwe of bestaande .NET-toepassing.
Een C#-klassebibliotheek maken
Omdat u helemaal opnieuw begint, maakt u een nieuw C#-klassebibliotheekproject waarin u een machine learning-model toevoegt.
Start Visual Studio.
Selecteer een nieuw project maken in het startvenster.
Voer in het dialoogvenster Een nieuw project maken de klassebibliotheek in op de zoekbalk.
Selecteer Klassebibliotheek in de lijst met opties. Zorg ervoor dat de taal C# is en selecteer Volgende.
Voer PredictiveMaintenance in het tekstvak Projectnaam in. Laat de standaardwaarden voor alle andere velden staan en selecteer Volgende.
Selecteer .NET 6.0 (preview) in de vervolgkeuzelijst Framework en selecteer vervolgens Maken om uw C#-klassebibliotheek te maken.

Machine learning toevoegen aan uw project
Nadat uw klasbibliotheekproject is geopend in Visual Studio, is het tijd om er machine learning aan toe te voegen.
Klik in Visual Studio Solution Explorer met de rechtermuisknop op uw project.
Selecteer Machine Learning-model toevoegen>.
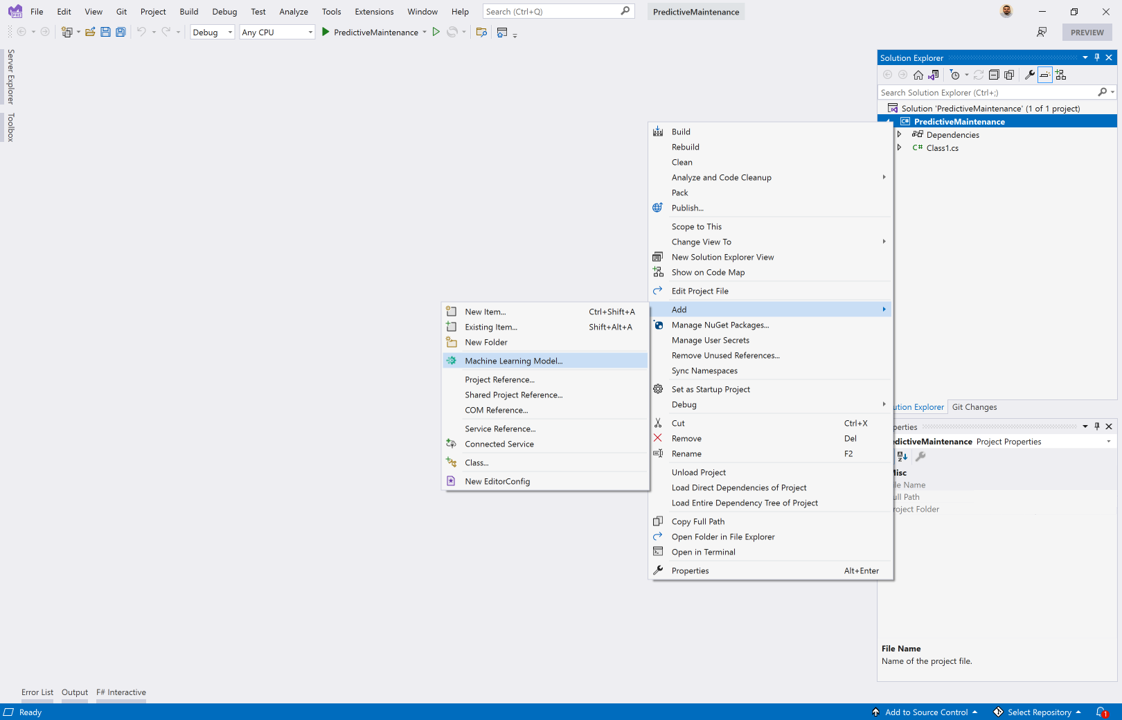
Selecteer Machine Learning-model (ML.NET) in de lijst met nieuwe items in het dialoogvenster Nieuw item toevoegen.
Gebruik in het tekstvak Naam de naam PredictiveMaintenanceModel.mbconfig voor uw model en selecteer Toevoegen.
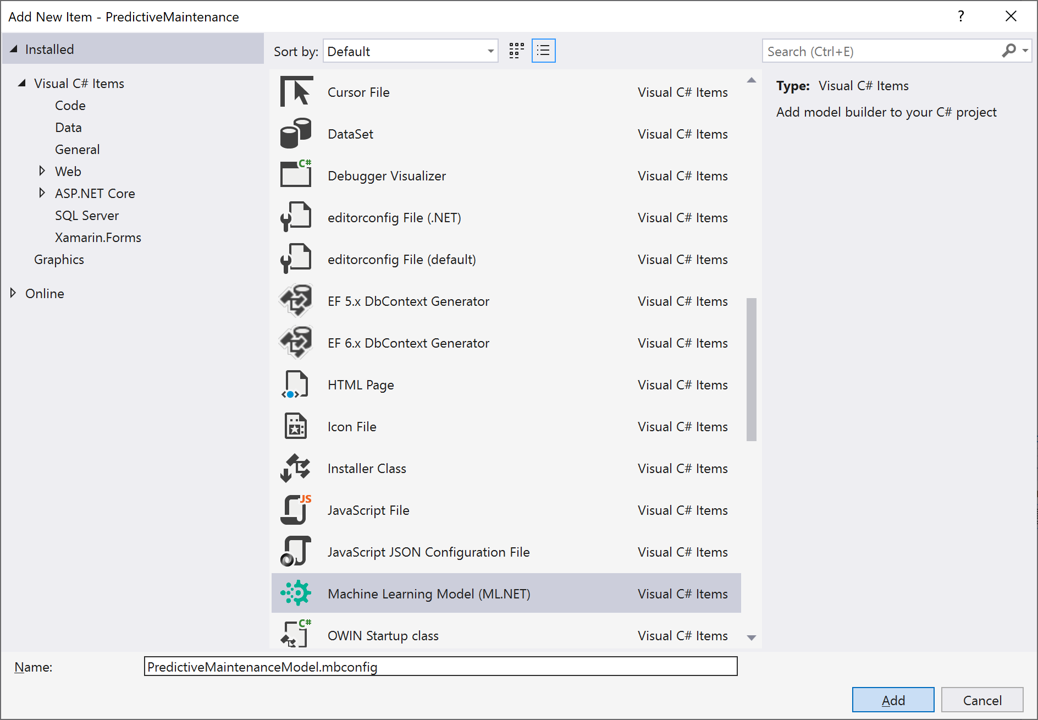


Na een paar seconden wordt een bestand met de naam PredictiveMaintenanceModel.mbconfig toegevoegd aan uw project.
Kies uw scenario
De eerste keer dat u een machine learning-model aan een project toevoegt, wordt het scherm Modelbouwer geopend. Nu is het tijd om uw scenario te selecteren.
Voor uw use-case probeert u te bepalen of een machine is verbroken of niet. Omdat er slechts twee opties zijn en u wilt bepalen in welke status een machine zich bevindt, is het scenario voor gegevensclassificatie het meest geschikt.
Selecteer in de stap Scenario van het scherm Modelbouwer het scenario voor gegevensclassificatie . Nadat u dit scenario hebt geselecteerd, bent u direct verder met de stap Omgeving .

Uw omgeving kiezen
Voor scenario's voor gegevensclassificatie worden alleen lokale omgevingen die gebruikmaken van uw CPU ondersteund.
- In de omgevingsstap van het scherm Modelbouwer is lokaal (CPU) standaard geselecteerd. Laat de standaardomgeving geselecteerd.
- Selecteer Volgende stap.

Uw gegevens laden en voorbereiden
Nu u uw scenario en trainingsomgeving hebt geselecteerd, is het tijd om de gegevens te laden en voor te bereiden die u hebt verzameld met behulp van Model Builder.
Uw gegevens voorbereiden
Open het bestand in de teksteditor van uw keuze.
De oorspronkelijke kolomnamen bevatten speciale haakjes. Als u problemen met het parseren van de gegevens wilt voorkomen, verwijdert u de speciale tekens uit de kolomnamen.
Oorspronkelijke koptekst:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFBijgewerkte header:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFSla het bestand ai4i2020.csv op met uw wijzigingen.
Kies uw gegevensbrontype
De gegevensset voorspeld onderhoud is een CSV-bestand.
Selecteer in de stap Gegevens van het scherm Modelbouwer het bestand (csv, tsv, txt) voor het gegevensbrontype.
Geef de locatie van uw gegevens op
Selecteer de knop Bladeren en gebruik de verkenner om de locatie van uw ai4i2020.csv-gegevensset op te geven.
De labelkolom kiezen
Kies Machinefout in de kolom om de vervolgkeuzelijst (Label) te voorspellen.

Geavanceerde gegevensopties kiezen
Standaard worden alle kolommen die niet het label zijn, gebruikt als functies. Sommige kolommen bevatten redundante informatie en andere kolommen informeren de voorspelling niet. Gebruik de geavanceerde gegevensopties om deze kolommen te negeren.
Selecteer Geavanceerde gegevensopties.
Selecteer in het dialoogvenster Geavanceerde gegevensopties het tabblad Kolominstellingen .
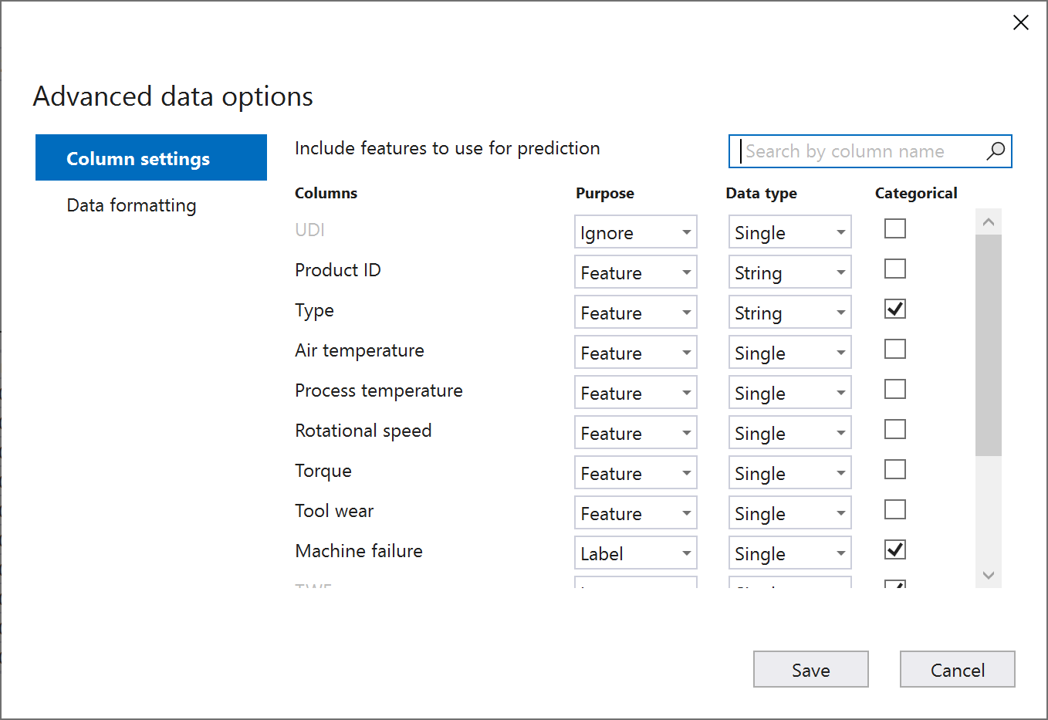
Configureer de kolominstellingen als volgt:
Kolommen Doel Gegevenstype Categorische gegevens UDI Negeren Eén Product-id Functie String Type Functie String X Luchttemperatuur Functie Eén Procestemperatuur Functie Eén Rotatiesnelheid Functie Eén Koppel aanbrengen Functie Eén Slijtage van gereedschap Functie Eén Computerfout Label Eén X TWF Negeren Eén X HDF Negeren Eén X PWF Negeren Eén X OSF Negeren Eén X RNF Negeren Eén X Selecteer Opslaan.
Selecteer volgende stap in de stap Gegevens van het scherm Modelbouwer.

Uw model trainen
Gebruik Model Builder en AutoML om uw model te trainen.
De trainingstijd instellen
Model Builder stelt automatisch in hoe lang u moet trainen op basis van de grootte van uw bestand. Geef in dit geval een hoger aantal voor de trainingstijd om Model Builder te helpen meer modellen te verkennen.
- Stel in de stap Trainen van het scherm Modelbouwer tijd in op trainen (seconden) op 30.
- Selecteer Trainen.
Het trainingsproces bijhouden

Nadat het trainingsproces is gestart, verkent Model Builder verschillende modellen. Uw trainingsproces wordt bijgehouden in de trainingsresultaten en in het uitvoervenster van Visual Studio. De trainingsresultaten bieden informatie over het beste model dat tijdens het trainingsproces is gevonden. Het uitvoervenster bevat gedetailleerde informatie, zoals de naam van het gebruikte algoritme, hoe lang het duurde om te trainen en de metrische prestatiegegevens voor dat model.
Mogelijk wordt dezelfde algoritmenaam meerdere keren weergegeven. Dit gebeurt omdat Naast het proberen van verschillende algoritmen, Model Builder verschillende hyperparameterconfiguraties voor deze algoritmen probeert.
Uw model evalueren
Gebruik metrische evaluatiegegevens en -gegevens om te testen hoe goed uw model presteert.
Uw model inspecteren
Met de stap Evalueren op het scherm Modelbouwer kunt u de metrische evaluatiegegevens en het algoritme controleren die zijn gekozen voor het beste model. Houd er rekening mee dat het ok is als uw resultaten afwijken van de resultaten die in deze module worden genoemd, omdat het gekozen algoritme en de hyperparameters mogelijk anders zijn.
Uw model testen
In de sectie Uw model uitproberen van de stap Evalueren kunt u nieuwe gegevens opgeven en de resultaten van uw voorspelling evalueren.

In de sectie Voorbeeldgegevens geeft u invoergegevens op voor uw model om voorspellingen te doen. Elk veld komt overeen met de kolommen die worden gebruikt om uw model te trainen. Dit is een handige manier om te controleren of het model zich gedraagt zoals verwacht. Model Builder vult standaard vooraf voorbeeldgegevens in met de eerste rij uit uw gegevensset.
We gaan uw model testen om te zien of het de verwachte resultaten produceert.
Voer in de sectie Voorbeeldgegevens de volgende gegevens in. Deze komt uit de rij in uw gegevensset met UID 161.
Kolom Weergegeven als Product-id L47340 Type L Luchttemperatuur 298.4 Procestemperatuur 308.2 Rotatiesnelheid 1282 Koppel aanbrengen 60.7 Slijtage van gereedschap 216 Selecteer Voorspellen.
Voorspellingsresultaten evalueren
In de sectie Resultaten wordt de voorspelling weergegeven die uw model heeft gemaakt en het betrouwbaarheidsniveau van die voorspelling.
Als u de kolom Machinefout van UID 161 in uw gegevensset bekijkt, ziet u dat de waarde 1 is. Dit is hetzelfde als de voorspelde waarde met het hoogste vertrouwen in de sectie Resultaten .
Desgewenst kunt u uw model blijven uitproberen met verschillende invoerwaarden en de voorspellingen evalueren.
Gefeliciteerd. U hebt een model getraind om machinefouten te voorspellen. In de volgende les leert u meer over modelverbruik.