Failover en failback met behulp van Azure Site Recovery
Met Azure Site Recovery kan uw organisatie flexibiliteit hebben, ofwel handmatig een failover naar een secundaire Azure-regio uitvoeren of een failback uitvoeren naar een bron-VM. De eenvoudigste manier om dit proces te beheren, is door dit handmatig in Azure Portal te doen. U hebt ook andere opties om automatisering in te schakelen als uw bedrijf de activering van een failover wil automatiseren. Deze opties omvatten technologieën zoals scripting via PowerShell of het instellen van runbooks in Azure Automation om failovers te organiseren.
Volg deze stappen om een volledige failover van een beveiligde VM uit te voeren in een secundaire regio in uw abonnement. Na voltooiing van de failover gaat u failback-overschakeling van die VM uitvoeren.
In deze les gaat u failover en failback verkennen, verkennen hoe u een virtuele machine waarvoor failover-overschakeling is uitgevoerd opnieuw beveiligt en gaat u de status van het opnieuw beveiligen bijhouden.
Wat is een failover?
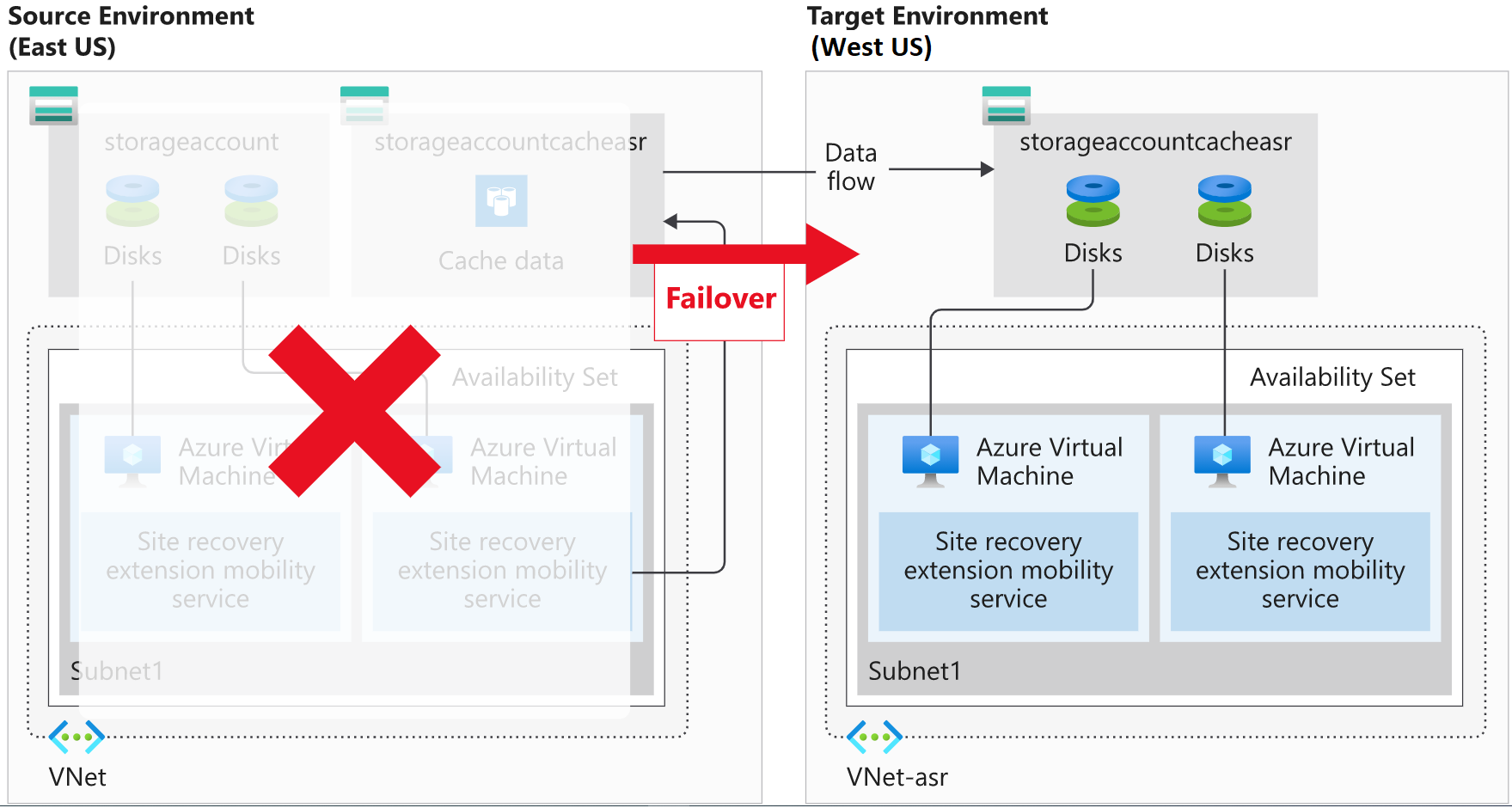
Een failover vindt plaats wanneer wordt besloten om een DR-plan voor uw organisatie uit te voeren. De bestaande productieomgeving, beveiligd door Site Recovery, wordt gerepliceerd in een andere regio. De doelomgeving wordt de feitelijke productieomgeving en wordt de omgeving waarin de productieservices van uw organisatie worden uitgevoerd. Als de doelregio eenmaal actief is, mag de bronomgeving niet meer worden gebruikt. U dwingt dit af door de bron-VM's uitgeschakeld te houden.
Uitschakeling van de bron-VM's heeft nog een voordeel. Het gebruik van een uitgeschakelde VM leidt tot minimaal gegevensverlies omdat de failover pas door Site Recovery wordt geactiveerd als alle gegevens naar schijf zijn geschreven. We selecteren het herstelpunt Laatste punt in de tijd (laagste RPO) om deze gegevens te gebruiken en een zo laag mogelijke RPO te krijgen.
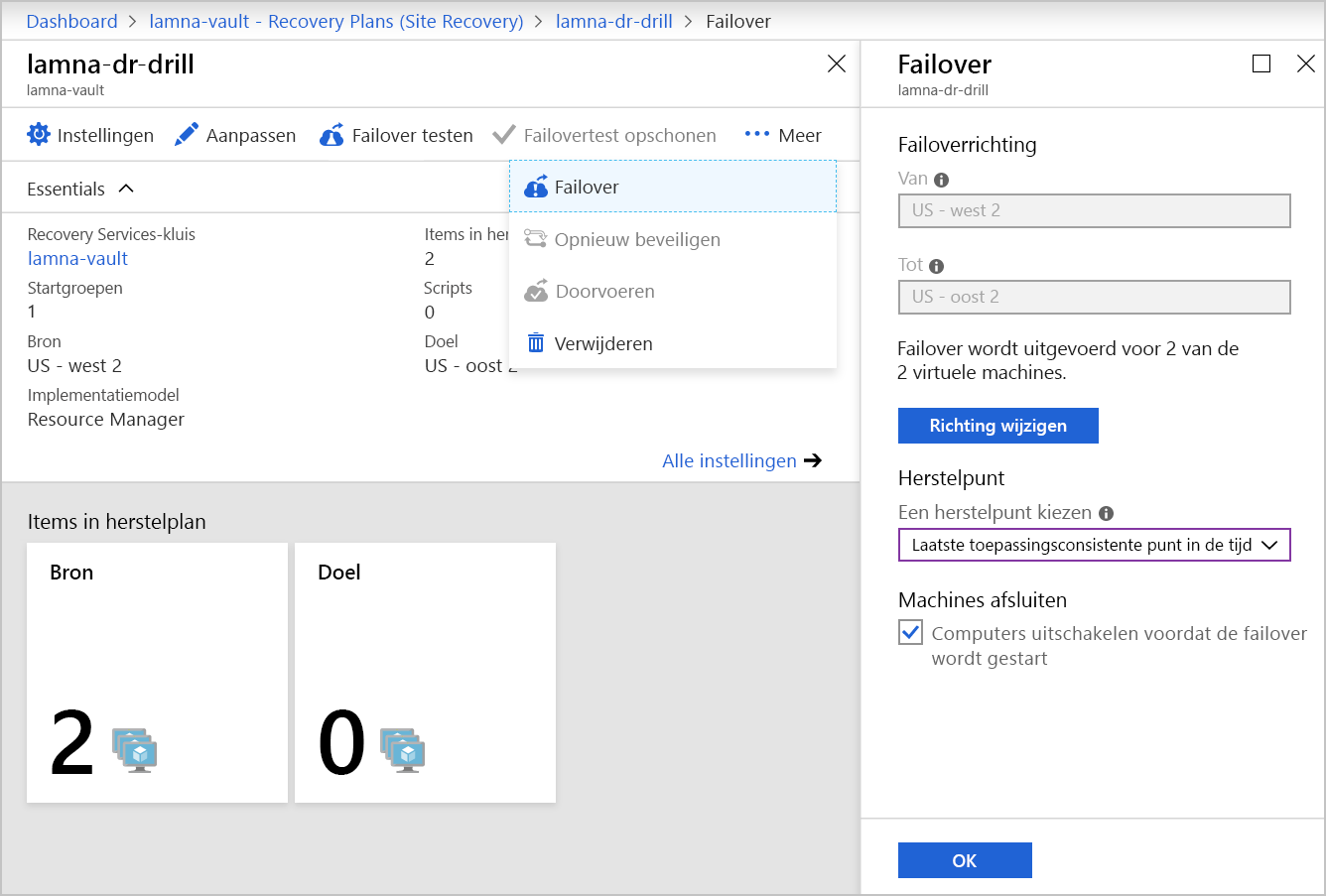
Wat is opnieuw beveiligen en waarom is het belangrijk?
Wanneer een FAILOVER van een VIRTUELE machine wordt uitgevoerd, is de replicatie die Site Recovery uitvoert niet meer actief. U moet de beveiliging opnieuw inschakelen om de VM te beveiligen waarvoor de failover-overschakeling is uitgevoerd. Omdat u de infrastructuur al in een andere regio hebt, kunt u de replicatie terug naar de bronregio starten. Door opnieuw te beveiligen kan uw nieuwe doelomgeving door Site Recovery terug worden gerepliceerd naar de bronomgeving van het begin.
U kunt de flexibiliteit van een failover van één VIRTUELE machine gebruiken of een failover-overschakeling uitvoeren met behulp van een herstelplan voor het opnieuw beveiligen van uw infrastructuur waarvoor een failover is uitgevoerd. U kunt elke VM afzonderlijk opnieuw beveiligen of meerdere VM's opnieuw beveiligen met behulp van een herstelplan.
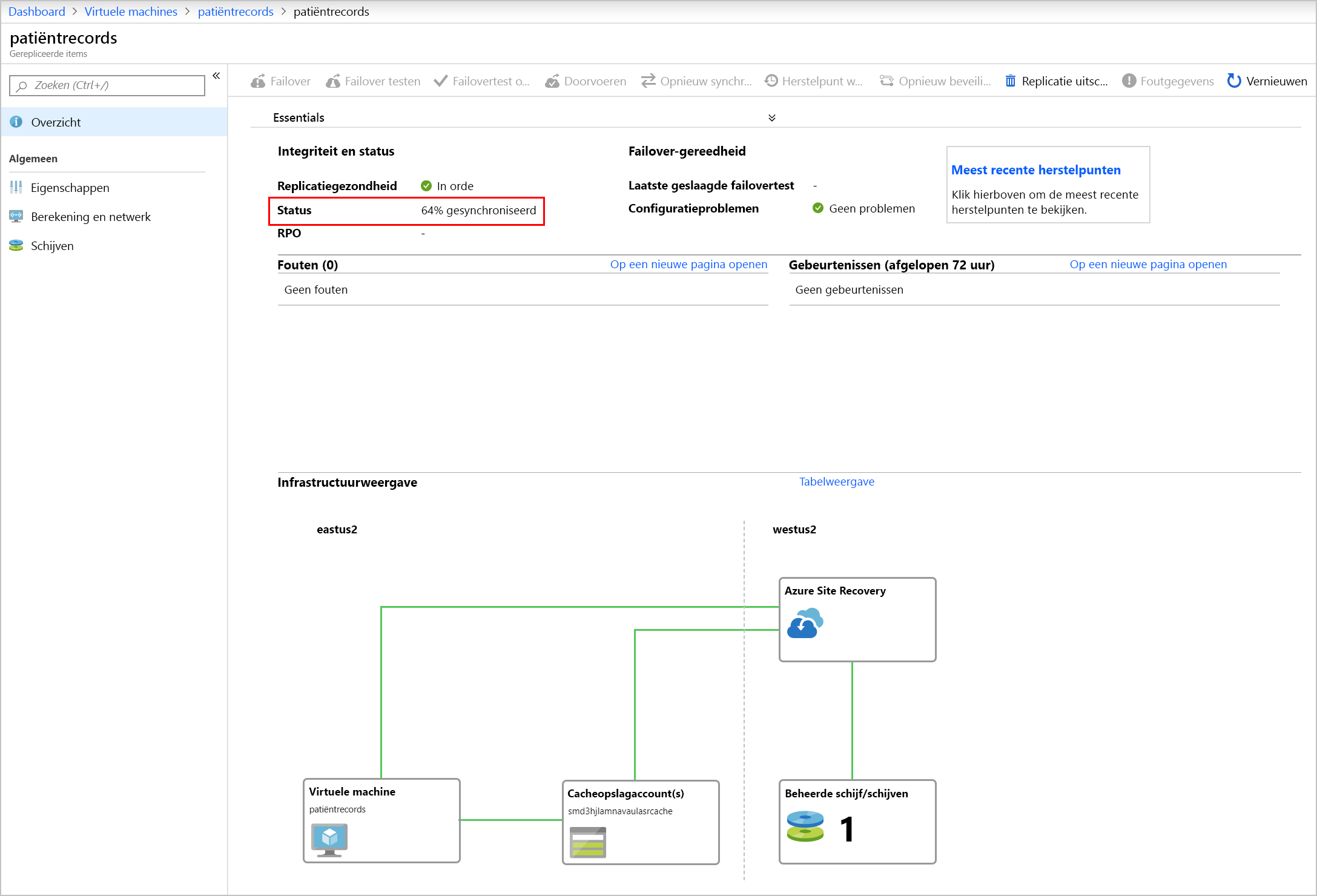
Opnieuw beveiligen kan tussen de 45 minuten en 2 uur duren, afhankelijk van de grootte en het type van de VM. In tegenstelling tot de andere Site Recovery-processen die u kunt bewaken door de voortgang van de taak te bekijken, moet u de voortgang van de beveiliging op VM-niveau bekijken. Dit komt doordat de synchronisatiefase niet als een sitehersteltaak wordt weergegeven.
In de afbeelding ziet u de status van het beveiligde item, waarbij het gesynchroniseerd percentage is gemarkeerd.
Wat is een failback?
Een failback is het omgekeerde van een failover. Dat is wanneer een failover naar een secundaire regio is voltooid en deze regio nu de productieomgeving is. De omgeving waarnaar is overschakeld, is opnieuw beveiligd en de bronomgeving is nu de replica ervan. In een failbackscenario wordt door Site Recovery failover-overschakeling uitgevoerd terug naar de bron-VM's.
Het proces voor het voltooien van een failback is hetzelfde als dat van een failover, zelfs tot aan hergebruik van het herstelplan. Als u failover selecteert in uw herstelplan, wordt van ingesteld op de doelregio en naar ingesteld op de bronregio.
Failovers beheren
In Site Recovery kunnen op aanvraag failovers worden uitgevoerd. Testfailovers zijn geïsoleerd, wat inhoudt dat deze geen gevolgen hebben voor productieservices. Dankzij deze flexibiliteit kunt u een failover uitvoeren zonder de gebruikers van dat systeem te onderbreken. De flexibiliteit werkt ook andersom: een failback op aanvraag kan namelijk ook worden uitgevoerd als onderdeel van een geplande test of als onderdeel van een volledig aangeroepen proces voor herstel na noodgeval.
De herstelplannen in Site Recovery maken ook aanpassing en sequentiëring van failover en failback mogelijk. Met de plannen kunt u machines en workloads groeperen.
Flexibiliteit kan ook van toepassing zijn op de manier waarop u het failoverproces wilt activeren. Handmatige failovers kunnen eenvoudig worden uitgevoerd via Azure Portal. Bij het uitvoeren van PowerShell-scripts of het gebruik van runbooks in Azure Automation beschikt u over automatiseringsopties.
Problemen met een failover oplossen
Hoewel Site Recovery is geautomatiseerd, kunnen er toch fouten optreden. De volgende lijst bevat de drie meest voorkomende problemen. Zie de koppeling in de les Samenvatting voor een volledige lijst met problemen en oplossingen.
Problemen met Azure-resourcequota
Via Site Recovery moeten resources worden gemaakt in verschillende regio's. Als dit niet mogelijk is met uw abonnement, mislukt de replicatie. Deze fout treedt ook op als het abonnement niet de juiste quotumlimieten heeft om VM's te maken met dezelfde grootte als de bron-VM's.
U kunt dit corrigeren door contact op te leggen met de ondersteuning van Azure-facturering en te vragen dat ze de juiste grootte-VM's maken in de benodigde doelregio.
Er zijn een of meer schijven zijn beschikbaar voor de beveiliging
Deze fout treedt op als u het instellen van Site Recovery voor uw VM's hebt voltooid. Vervolgens hebt u extra schijven toegevoegd of geïnitialiseerd.
U kunt deze fout oplossen door replicatie toe te voegen voor de zojuist toegevoegde schijven, of u kunt de schijfwaarschuwing negeren.
Vertrouwde basiscertificaten
Controleer of de nieuwste basiscertificaten zijn geïnstalleerd zodat veilige communicatie met en verificatie van VM's voor replicatie mogelijk is in Site Recovery. Deze fout treedt op als voor uw VM's niet de nieuwste updates zijn toegepast. Werk zowel Windows- als Linux-VM's bij voordat replicatie kan worden ingeschakeld door Site Recovery.
De correctie verschilt voor elk besturingssysteem. Windows is net zo eenvoudig als ervoor zorgen dat automatische Windows-updates zijn ingeschakeld en updates worden toegepast. Voor elke Linux-distributie moet u de richtlijnen van de distributeur volgen.