Apache Phoenix gebruiken in HDInsight HBase
HBase-clusters in HDInsight worden geleverd met Apache Phoenix. Apache Phoenix is een open source, zeer parallelle relationele databaselaag die is gebouwd op Apache HBase. Met Apache Phoenix kunt u SQL-achtige query's gebruiken via HBase. Er worden onderliggende JDBC-stuurprogramma's gebruikt om gebruikers in staat te stellen SQL-tabellen te maken, te verwijderen en te wijzigen. U kunt ook afzonderlijk en bulksgewijs weergaven en reeksen maken, en rijen upsert. Phoenix maakt gebruik van noSQL native compilatie in plaats van MapReduce te gebruiken om query's te compileren, waardoor toepassingen met lage latentie kunnen worden gemaakt boven op HBase. Phoenix voegt coprocessors toe ter ondersteuning van door de client geleverde code in de adresruimte van de server, waarbij de code wordt uitgevoerd die is gekoppeld aan de gegevens. Deze aanpak minimaliseert de overdracht van client-/servergegevens. Zie de Documentatie van Apache Phoenix voor meer informatie.
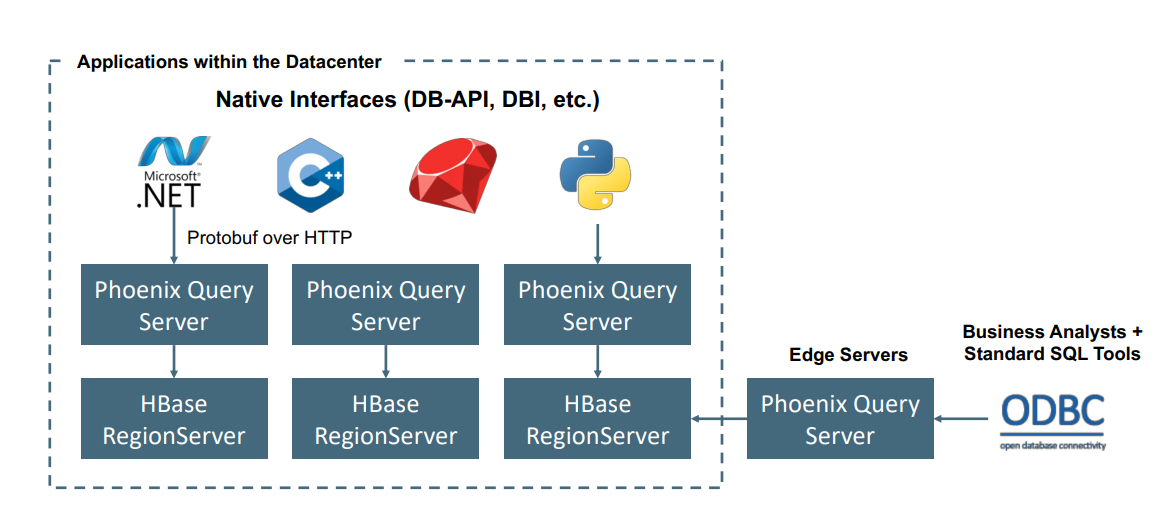
Apache Phoenix in HDInsight HBase wordt doorgaans gebruikt om selfserviceanalyse in te schakelen en inzichten te extraheren, zoals hieronder wordt weergegeven. Phoenix kan worden aangesloten op elk ODBC-compatibel BI-hulpprogramma en ad-hoc SQL-analyses inschakelen op HBase.
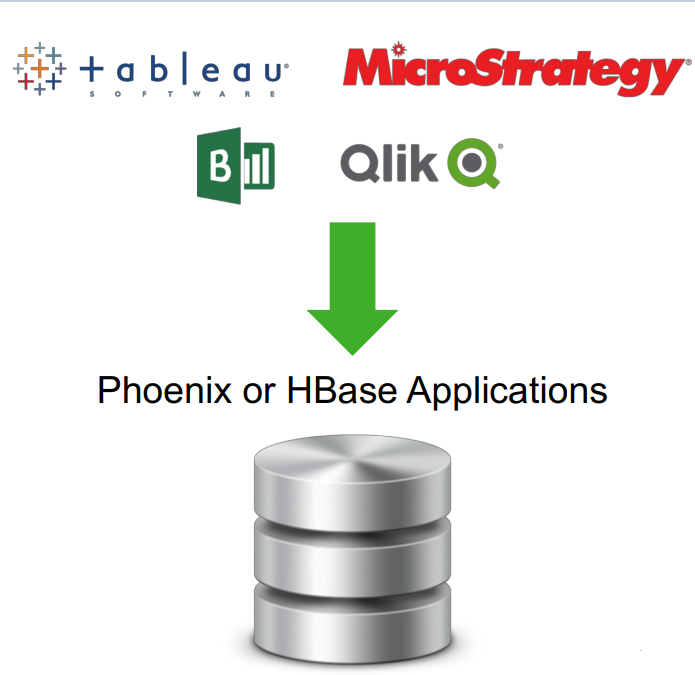
Het combineren van Apache HBase en Phoenix kan worden gebruikt als een gegevensarchief voor veranderlijke gegevens. De Apache Phoenix-query-engine op HBase wordt geleverd met enkele belangrijke functies.
Secundaire indexen
Records in HBase worden geopend met behulp van de primaire rijsleutel met behulp van één index die lexicografisch is gesorteerd op de primaire rijsleutel. Als u op een andere manier toegang probeert te krijgen tot records dan de primaire rij, kan dit leiden tot inefficiënt scannen van alle gegevens in de HBase-tabel. Met Apache Phoenix kunt u secundaire indexen maken voor kolommen en expressies om alternatieve rijsleutels te maken, zodat puntzoekacties of bereikscans langs deze nieuwe index kunnen worden uitgevoerd. Zie de documentatie van Apache Phoenix Secondary Indexes voor meer informatie.
De opdracht CREATE INDEX wordt gebruikt voor het maken van secundaire indexen in HBase, zoals hieronder wordt weergegeven.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Weergaven
Het beperken van het aantal fysieke tabellen in HBase en het beperken van het aantal regio's is een aanbevolen strategie. Weergaven in Phoenix helpen deze aanbeveling door het maken van meerdere virtuele tabellen die dezelfde onderliggende fysieke tabel op HBase delen. Zie de documentatie over Apache Phoenix Views voor meer informatie.
Gegeven de onderstaande tabeldefinitie in HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
U kunt de volgende weergave definiëren.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transacties
Hoewel HBase alleen met transacties op rijniveau werkt, maakt Apache Phoenix cross table- en cross row-transacties mogelijk met volledige ACID-ondersteuning door integratie met Apache Tephra.
Zie de documentatie voor Apache Phoenix Transactions voor meer informatie
In het volgende voorbeeld wordt een tabel met de naam my_table gemaakt en vervolgens de tabel gewijzigd om transacties in te schakelen.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Gezouten tabellen
Region Server-hotspotting in HBase kan optreden tijdens sequentiële schrijfbewerkingen als de rijsleutels monotonisch toenemen. Apache Phoenix kan de hotspot verlichten door een manier te bieden om de rijsleutel te zouten met een salting byte voor een bepaalde tabel. Raadpleeg de documentatie van Apache Phoenix Salted Table voor meer informatie.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Scan overslaan
Voor een bepaalde set rijen gebruikt Apache Phoenix Skip Scan voor het scannen binnen rijen via een bereikscan voor verbeterde prestaties. Skip Scan maakt gebruik van het SEEK_NEXT_USING_HINT HBase-filter. Er wordt informatie opgeslagen over welke set sleutels/bereiken sleutels wordt gezocht in elke kolom. Vervolgens wordt een sleutel (doorgegeven tijdens de filterevaluatie) gebruikt en wordt bepaald of deze zich in een van de combinaties of het bereik bevindt of niet. Als dat niet zo is, wordt opgegeven aan welke volgende hoogste sleutel moet worden sprongen. Zie de documentatie over Apache Phoenix Skip Scan voor meer informatie.
Prestatieoptimalisatie op Apache Phoenix is een optionele aangevraagde functie en is meestal afhankelijk van het optimaliseren van de HBase-prestaties eronder. Prestatieoptimalisatie is een complex onderwerp en valt buiten het bereik van deze cursus. Als u echter geïnteresseerd bent, kunt u de documentatie over best practices voor Apache Phoenix Performance raadplegen.