Gegevenssets testen en trainen
De gegevens die we gebruiken om een model te trainen, worden vaak een trainingsgegevensset genoemd. We hebben dit al in actie gezien. Frustrerend, wanneer we het model in de echte wereld gebruiken, weten we niet zeker hoe goed ons model werkt. Deze onzekerheid komt doordat onze trainingsgegevensset mogelijk verschilt van gegevens in de echte wereld.
Wat is overfitting?
Een model is overfit als het beter werkt op de trainingsgegevens dan op andere gegevens. De naam verwijst naar het feit dat het model zo goed past dat het de details van de trainingsset in de herinnering heeft gekregen in plaats van brede regels te vinden die van toepassing zijn op andere gegevens. Overfitting is gebruikelijk, maar niet wenselijk. Aan het einde van de dag maken we alleen uit hoe goed ons model werkt op echte gegevens.
Hoe kunnen we overfitting voorkomen?
We kunnen overfitting op verschillende manieren voorkomen. De eenvoudigste manier is om een eenvoudiger model te hebben of om een gegevensset te gebruiken die een betere weergave is van wat er in de echte wereld wordt gezien. Als u deze methoden wilt begrijpen, kunt u een scenario overwegen waarin echte gegevens er als volgt uitzien:
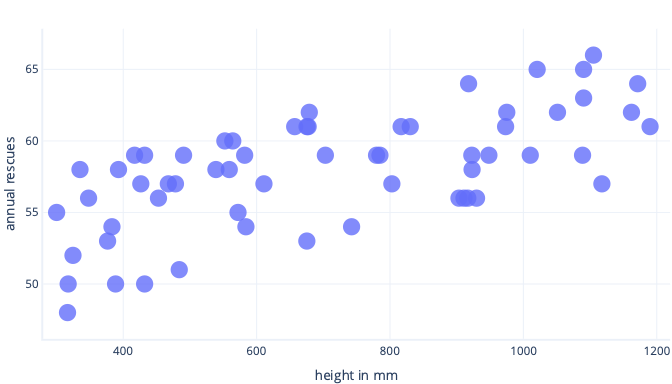
Stel dat we informatie verzamelen over slechts vijf honden en dat gebruiken als onze trainingsgegevensset om aan een complexe lijn te voldoen. Als we dit kunnen doen, kunnen we het heel goed aanpassen:
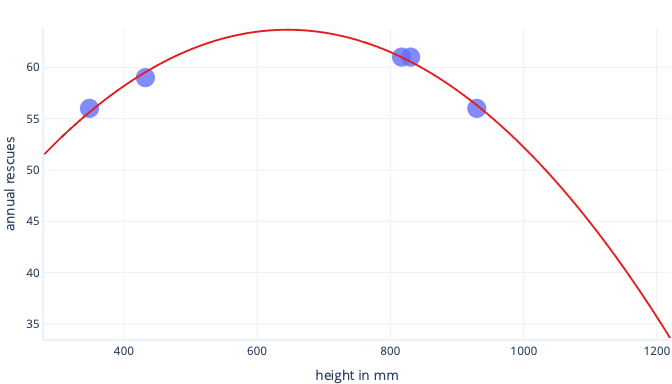
Wanneer dit echter in de echte wereld wordt gebruikt, zullen we merken dat het voorspellingen doet die onjuist blijken te zijn:
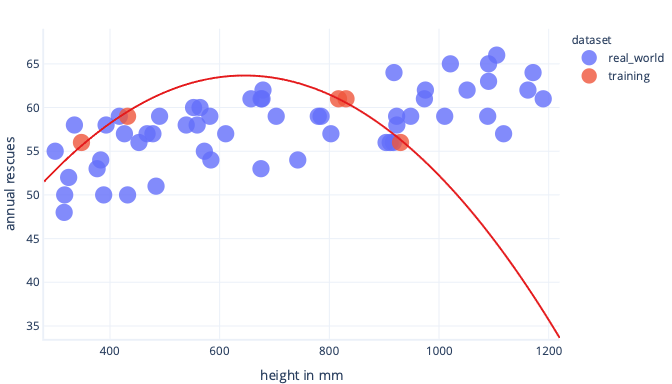
Als we een representatievere gegevensset en een eenvoudiger model hebben, blijkt de lijn die we aanpassen betere (hoewel niet perfecte) voorspellingen te maken:
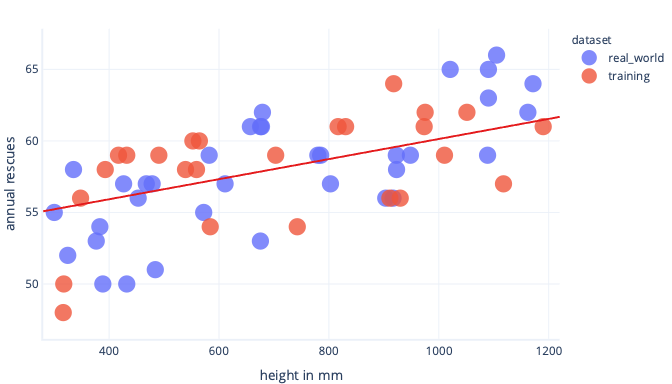
Een gratis manier om overfitting te voorkomen, is om te stoppen met trainen nadat het model algemene regels heeft geleerd, maar voordat het model overfit is. Hiervoor moet wel worden gedetecteerd wanneer we ons model gaan overfitten. We kunnen dit doen met behulp van een testgegevensset.
Wat is een testgegevensset?
Een testgegevensset, ook wel een validatiegegevensset genoemd, is een set gegevens die vergelijkbaar is met de trainingsgegevensset. Testgegevenssets worden meestal gemaakt door een grote gegevensset te nemen en te splitsen. Het ene gedeelte wordt de trainingsgegevensset genoemd en het andere wordt de testgegevensset genoemd.
De taak van de trainingsgegevensset is het trainen van het model; We hebben al training gezien. De taak van de testgegevensset is om te controleren hoe goed het model werkt; het draagt niet rechtstreeks bij aan training.
Oké, maar wat is het punt?
Het punt van een testgegevensset is tweevoudig.
Ten eerste, als de testprestaties tijdens de training stoppen, kunnen we stoppen; Er is geen punt om door te gaan. Als we doorgaan, kunnen we het model aanmoedigen om meer te weten te komen over de trainingsgegevensset die zich niet in de testgegevensset bevindt, wat overfitting is.
Ten tweede kunnen we een testgegevensset gebruiken na de training. Dit geeft ons een indicatie van hoe goed het uiteindelijke model werkt wanneer er 'echte' gegevens worden weergegeven die het nog niet eerder heeft gezien.
Wat betekent dat voor kostenfuncties?
Wanneer we zowel trainings- als testgegevenssets gebruiken, berekenen we uiteindelijk twee kostenfuncties.
De eerste kostenfunctie maakt gebruik van de trainingsgegevensset, net zoals we eerder hebben gezien. Deze kostenfunctie wordt doorgegeven aan de optimizer en wordt gebruikt om het model te trainen.
De tweede kostenfunctie wordt berekend met behulp van de testgegevensset. We gebruiken dit om te controleren hoe goed het model werkt in de echte wereld. Het resultaat van de kostenfunctie wordt niet gebruikt om het model te trainen. Om dit te berekenen, onderbreken we de training, kijken we hoe goed het model presteert op een testgegevensset en hervatten we de training.