Verschillende typen clustering evalueren
Een clusteringmodel trainen
Er zijn meerdere algoritmen die u kunt gebruiken voor clustering. Een van de meest gebruikte algoritmen is K-Means-clustering die, in de eenvoudigste vorm, bestaat uit de volgende stappen:
- De functiewaarden worden gevectoriseerd om n-dimensionale coördinaten te definiëren (waarbij n het aantal functies is). In het bloemvoorbeeld hebben we twee kenmerken: aantal bloemblaadjes en aantal bladeren. De functievector heeft dus twee coördinaten die we kunnen gebruiken om de gegevenspunten in tweedimensionale ruimte conceptueel te tekenen.
- U bepaalt hoeveel clusters u wilt gebruiken om de bloemen te groeperen. Noem deze waarde k. Als u bijvoorbeeld drie clusters wilt maken, gebruikt u een k-waarde van 3. K-punten worden vervolgens uitgezet op willekeurige coördinaten. Deze punten worden de middelpunten voor elk cluster, dus ze worden zwaartepunten genoemd.
- Elk gegevenspunt (in dit geval een bloem) wordt toegewezen aan het dichtstbijzijnde zwaartepunt.
- Elk zwaartepunt wordt verplaatst naar het midden van de gegevenspunten die eraan zijn toegewezen op basis van de gemiddelde afstand tussen de punten.
- Nadat het zwaartepunt is verplaatst, kunnen de gegevenspunten zich nu dichter bij een ander zwaartepunt bevinden, zodat de gegevenspunten opnieuw worden toegewezen aan clusters op basis van het nieuwe dichtstbijzijnde zwaartepunt.
- De stappen voor de zwaartepuntsverplaatsing en het opnieuw toewijzen van clusters worden herhaald totdat de clusters stabiel worden of een vooraf bepaald maximum aantal iteraties wordt bereikt.
In de volgende animatie ziet u dit proces:

Hiërarchische clustering
Hiërarchische clustering is een ander type clustering-algoritme waarin clusters zelf behoren tot grotere groepen, die tot nog grotere groepen behoren, enzovoort. Het resultaat is dat gegevenspunten clusters kunnen zijn in verschillende mate van precisie: met een groot aantal zeer kleine en nauwkeurige groepen of een klein aantal grotere groepen.
Als we bijvoorbeeld clustering toepassen op de betekenis van woorden, krijgen we mogelijk een groep met bijvoeglijke naamwoorden die specifiek zijn voor emoties ('boos', 'gelukkig' enzovoort). Deze groep behoort tot een groep met alle mensgerelateerde bijvoeglijke naamwoorden ('gelukkig', 'knap', 'jong'), die behoort tot een nog hogere groep met alle bijvoeglijke naamwoorden ('gelukkig', 'groen', 'knap', 'hard', enzovoort).
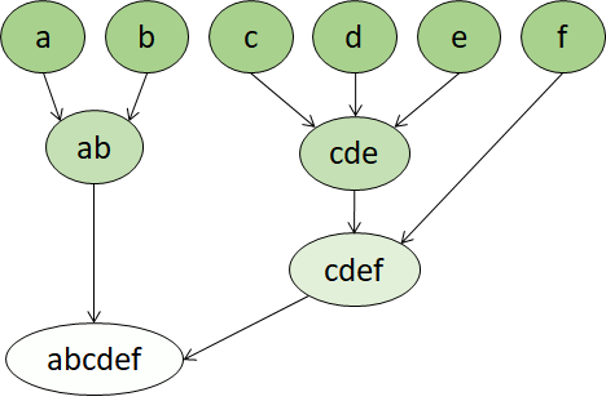
Hiërarchische clustering is handig om niet alleen gegevens in groepen op te breken, maar om inzicht te krijgen in de relaties tussen deze groepen. Een groot voordeel van hiërarchische clustering is dat het aantal clusters niet van tevoren hoeft te worden gedefinieerd. En het kan soms meer interpreteerbare resultaten bieden dan niet-hierarchische benaderingen. De belangrijkste nadelen zijn dat deze benaderingen langer kunnen duren om te berekenen dan eenvoudigere benaderingen, en soms zijn ze niet geschikt voor grote gegevenssets.