Convolutionele neurale netwerken
Hoewel u deep learning-modellen kunt gebruiken voor elk type machine learning, zijn ze met name handig voor het omgaan met gegevens die bestaan uit grote matrices met numerieke waarden, zoals afbeeldingen. Machine learning-modellen die met afbeeldingen werken, vormen de basis voor een gebied met kunstmatige intelligentie, computer vision genoemd, en deep learning-technieken zijn de afgelopen jaren verantwoordelijk geweest voor het stimuleren van geweldige ontwikkelingen op dit gebied.
Het hart van het succes van deep learning op dit gebied is een soort model dat een convolutionele neurale netwerk of CNN wordt genoemd. Een CNN werkt doorgaans door functies uit afbeeldingen te extraheren en deze functies vervolgens in een volledig verbonden neuraal netwerk te leveren om een voorspelling te genereren. De functieextractielagen in het netwerk hebben het effect van het verminderen van het aantal functies van de potentieel enorme matrix met afzonderlijke pixelwaarden tot een kleinere functieset die labelvoorspelling ondersteunt.
Lagen in een CNN
CNN's bestaan uit meerdere lagen, die elk een specifieke taak uitvoeren bij het extraheren van functies of het voorspellen van labels.
Convolutielagen
Een van de belangrijkste laagtypen is een convolutionele laag waarmee belangrijke functies in afbeeldingen worden geëxtraheerd. Een convolutionele laag werkt door een filter toe te passen op afbeeldingen. Het filter wordt gedefinieerd door een kernel die bestaat uit een matrix met gewichtswaarden.
Een 3x3-filter kan bijvoorbeeld als volgt worden gedefinieerd:
1 -1 1
-1 0 -1
1 -1 1
Een afbeelding is ook slechts een matrix met pixelwaarden. Als u het filter wilt toepassen, 'overlay' u deze op een afbeelding en berekent u een gewogen som van de overeenkomende pixelwaarden voor afbeeldingen onder de filterkernel. Het resultaat wordt vervolgens toegewezen aan de middelste cel van een equivalente 3x3-patch in een nieuwe matrix met waarden die dezelfde grootte hebben als de afbeelding. Stel dat een afbeelding van 6 x 6 de volgende pixelwaarden heeft:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Het toepassen van het filter op het 3x3-gedeelte linksboven van de afbeelding werkt als volgt:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Het resultaat wordt als volgt toegewezen aan de bijbehorende pixelwaarde in de nieuwe matrix:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Het filter wordt nu verplaatst (samengevoegde), meestal met behulp van een stap grootte van 1 (dus één pixel naar rechts verplaatsen) en de waarde voor de volgende pixel wordt berekend
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Nu kunnen we dus de volgende waarde van de nieuwe matrix invullen.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Het proces wordt herhaald totdat we het filter hebben toegepast op alle 3x3-patches van de afbeelding om een nieuwe matrix met waarden als deze te produceren:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Vanwege de grootte van de filterkernel kunnen we geen waarden berekenen voor de pixels aan de rand; Daarom passen we doorgaans alleen een opvullingswaarde toe (vaak 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
De uitvoer van de convolutie wordt doorgaans doorgegeven aan een activeringsfunctie. Dit is vaak een functie Rectified Linear Unit (ReLU) die ervoor zorgt dat negatieve waarden worden ingesteld op 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
De resulterende matrix is een functieoverzicht van functiewaarden die kunnen worden gebruikt om een machine learning-model te trainen.
Opmerking: de waarden in de functiekaart kunnen groter zijn dan de maximumwaarde voor een pixel (255), dus als u de functiekaart als afbeelding wilt visualiseren, moet u de functiewaarden tussen 0 en 255 normaliseren .
Het convolutieproces wordt weergegeven in de onderstaande animatie.

- Een afbeelding wordt doorgegeven aan de convolutionele laag. In dit geval is de afbeelding een eenvoudige geometrische vorm.
- De afbeelding bestaat uit een matrix van pixels met waarden tussen 0 en 255 (voor kleurenafbeeldingen is dit meestal een driedimensionale matrix met waarden voor rode, groene en blauwe kanalen).
- Een filterkernel wordt over het algemeen geïnitialiseerd met willekeurige gewichten (in dit voorbeeld hebben we waarden gekozen om het effect te benadrukken dat een filter kan hebben op pixelwaarden; maar in een echte CNN worden de aanvankelijke gewichten meestal gegenereerd op basis van een willekeurige Gaussiaanse verdeling). Dit filter wordt gebruikt om een functieoverzicht uit de afbeeldingsgegevens te extraheren.
- Het filter wordt samengevoegd over de afbeelding, waarbij functiewaarden worden berekend door een som van de gewichten toe te passen die worden vermenigvuldigd met de bijbehorende pixelwaarden in elke positie. Er wordt een reLU-activeringsfunctie (Rectified Linear Unit) toegepast om ervoor te zorgen dat negatieve waarden zijn ingesteld op 0.
- Na convolutie bevat de featuremap de geëxtraheerde kenmerkwaarden, die vaak belangrijke visuele eigenschappen van de afbeelding benadrukken. In dit geval markeert de functiekaart de randen en hoeken van de driehoek in de afbeelding.
Normaal gesproken past een convolutionele laag meerdere filterkernels toe. Elk filter produceert een andere functietoewijzing en alle functietoewijzingen worden doorgegeven aan de volgende laag van het netwerk.
Poollagen
Nadat u functiewaarden hebt geëxtraheerd uit afbeeldingen, worden poollagen (of downsampling) gebruikt om het aantal functiewaarden te verminderen terwijl de belangrijkste differentiërende functies behouden blijven die zijn geëxtraheerd.
Een van de meest voorkomende soorten pooling is maximale pooling waarbij een filter wordt toegepast op de afbeelding en alleen de maximale pixelwaarde in het filtergebied wordt behouden. Als u bijvoorbeeld een 2x2-pooling-kernel toepast op de volgende patch van een afbeelding, zou het resultaat 155 zijn.
0 0
0 155
Houd er rekening mee dat het effect van het 2x2-poolfilter is om het aantal waarden van 4 tot en met 1 te verminderen.
Net als bij convolutionele lagen werken poollagen door het filter toe te passen op de hele functiekaart. In de onderstaande animatie ziet u een voorbeeld van maximale pooling voor een afbeeldingskaart.

- De kenmerkenkaart die door een filter in een convolutionele laag is geëxtraheerd bevat een array met functiewaarden.
- Een poolkernel wordt gebruikt om het aantal functiewaarden te verminderen. In dit geval is de kernelgrootte 2x2, waardoor er een array wordt geproduceerd met een kwart van het aantal functiewaarden.
- De poolingkernel wordt over de kenmerkmap geconvolveerd en behoudt alleen de hoogste pixelwaarde op elke locatie.
Lagen laten vallen
Een van de moeilijkste uitdagingen in een CNN is het vermijden van overfitting, waarbij het resulterende model goed presteert met de trainingsgegevens, maar niet goed generaliseert naar nieuwe gegevens waarop het niet is getraind. Een techniek die je kunt gebruiken om overfitting te beperken, is door lagen op te nemen waarin het trainingsproces willekeurig kenmerkkaarten (of 'dropouts') uitschakelt. Dit lijkt misschien contra-intuïtief, maar het is een effectieve manier om ervoor te zorgen dat het model niet te veel afhankelijk is van de trainingsafbeeldingen.
Andere technieken die u kunt gebruiken om overfitting te beperken, zijn willekeurig omdraaien, spiegelen of verdraaien van de trainingsafbeeldingen om gegevensvariatie te creëren tussen de trainingsperioden.
Platmakende lagen
Nadat u convolutionele en poollagen hebt gebruikt om de opvallende kenmerken in de afbeeldingen te extraheren, zijn de resulterende functiekaarten multidimensionale matrices van pixelwaarden. Een afvlakkende laag wordt gebruikt om de kenmerkenkaarten af te vlakken tot een vector van waarden die kunnen worden gebruikt als invoer voor een volledig verbonden laag.
Volledig verbonden lagen
Normaal gesproken eindigt een CNN met een volledig verbonden netwerk waarin de functiewaarden worden doorgegeven aan een invoerlaag, via een of meer verborgen lagen en voorspelde waarden genereren in een uitvoerlaag.
Een algemene CNN-architectuur kan er ongeveer als volgt uitzien:
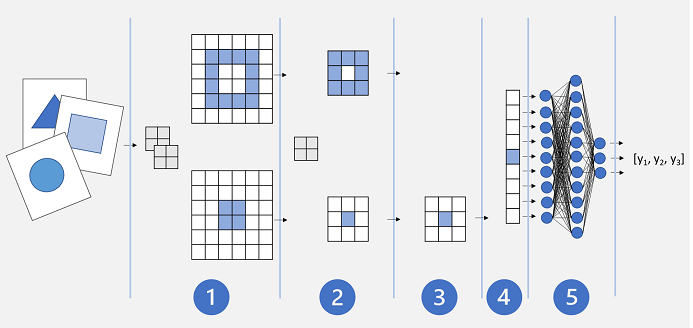
- Afbeeldingen worden ingevoerd in een convolutionele laag. In dit geval zijn er twee filters, dus elke afbeelding produceert twee kenmerkkaarten.
- De functietoewijzingen worden doorgegeven aan een poollaag, waarbij een poolkernel van 2x2 de grootte van de functietoewijzingen vermindert.
- Een neerhalende laag laat een deel van de functietoewijzingen willekeurig vallen om overfitting te voorkomen.
- Een afvlakkende laag neemt de resterende kenmerkkaarten en vlakt ze af tot een vector.
- De vectorelementen worden ingevoerd in een volledig verbonden netwerk, waarmee de voorspellingen worden gegenereerd. In dit geval is het netwerk een classificatiemodel dat waarschijnlijkheden voorspelt voor drie mogelijke afbeeldingsklassen (driehoek, vierkant en cirkel).
Een CNN-model trainen
Net als bij elk diep neuraal netwerk wordt een CNN getraind door batches van trainingsgegevens door te geven over meerdere epochen, waarbij de gewichten en biaswaarden worden aangepast op basis van het verlies dat voor elke epoch wordt berekend. In het geval van een CNN omvat backpropagatie van aangepaste gewichten filterkernelgewichten die worden gebruikt in convolutionele lagen, evenals de gewichten die in volledig verbonden lagen worden gebruikt.