Apparaatbeheer voor opnieuw verbinden onderzoeken
Op deze pagina vindt u richtlijnen op hoog niveau om tolerante toepassingen te ontwerpen door een strategie voor het opnieuw verbinden van apparaten toe te voegen. Hier wordt uitgelegd waarom apparaten de verbinding verbreken en opnieuw verbinding moeten maken. En het beschrijft specifieke strategieën die ontwikkelaars kunnen gebruiken om opnieuw verbinding te maken met apparaten die zijn losgekoppeld.
De connectiviteits- en betrouwbare berichtenfuncties in Azure IoT-apparaat-SDK's kunnen u helpen bij het ontwerpen van apparaattoepassingen die toleranter zijn. Het toepassen van de juiste richtlijnen op code aan de apparaatzijde kan u helpen de volgende scenario's aan te pakken:
- Een verbroken netwerkverbinding herstellen
- Schakelen tussen verschillende netwerkverbindingen
- Opnieuw verbinding maken vanwege tijdelijke verbindingsfouten van de service
Zie de volgende bronnen voor informatie over de prestaties en hoge beschikbaarheid van IoT Hub, waaronder Een IoT Hub-failover:
- Hoge beschikbaarheid en herstel na noodgevallen van IoT Hub
- Zelfstudie: Handmatige failover uitvoeren voor een IoT-hub
Wat veroorzaakt verbroken verbindingen?
Hier volgen de meest voorkomende redenen waarom apparaten de verbinding met IoT Hub verbreken:
- Verlopen SAS-token of X.509-certificaat. Het SAS-token of X.509-verificatiecertificaat van het apparaat is verlopen.
- Netwerkonderbreking. De verbinding van het apparaat met het netwerk wordt onderbroken.
- Serviceonderbreking. De Azure IoT Hub-service ondervindt fouten of is tijdelijk niet beschikbaar.
- Opnieuw configureren van service. Nadat u de ioT Hub-service-instellingen opnieuw hebt geconfigureerd, kan dit ertoe leiden dat apparaten opnieuw inrichten of opnieuw verbinding moeten maken.
Waarom u een strategie voor opnieuw verbinden nodig hebt
Het is belangrijk dat u een strategie hebt om apparaten opnieuw te verbinden, zoals beschreven in de volgende secties. Zonder een strategie voor opnieuw verbinden kunt u een negatief effect zien op de prestaties, beschikbaarheid en kosten van uw oplossing.
Pogingen om opnieuw verbinding te maken met massa kunnen leiden tot een DDoS
Een groot aantal verbindingspogingen per seconde kan een voorwaarde veroorzaken die vergelijkbaar is met een DDoS (Gedistribueerde Denial-of-Service-aanval). Dit scenario is relevant voor grote vloten apparaten die in miljoenen worden genummerd. Het probleem kan verder gaan dan de tenant die eigenaar is van de vloot en heeft invloed op de gehele schaaleenheid. Een DDoS kan leiden tot een grote kostenstijging voor uw Azure IoT Hub-resources, vanwege een noodzaak om uit te schalen. Een DDoS kan ook de prestaties van uw oplossing schaden vanwege resourcehongering. In het ergere geval kan een DDoS serviceonderbreking veroorzaken.
Hubfout of herconfiguratie kan veel apparaten verbreken
Nadat een IoT-hub een fout heeft opgetreden of nadat u de service-instellingen opnieuw hebt geconfigureerd op een IoT-hub, kunnen apparaten worden losgekoppeld. Voor de juiste failover moeten niet-verbonden apparaten opnieuw worden geprovisioneerd. Zie hoge beschikbaarheid en herstel na noodgevallen voor IoT Hub voor meer informatie over failoveropties.
Als u veel apparaten opnieuw wilt inrichten, kunnen de kosten toenemen
Nadat apparaten de verbinding met IoT Hub verbreken, is de optimale oplossing om het apparaat opnieuw te verbinden in plaats van het opnieuw te inrichten. Als u IoT Hub gebruikt met IoT Hub Device Provisioning Service (DPS), heeft DPS een kosten per inrichting. Als u veel apparaten opnieuw in DPS inricht, worden de kosten van uw IoT-oplossing verhoogd.
Ontwerpen voor tolerantie
IoT-apparaten zijn vaak afhankelijk van niet-continue of instabiele netwerkverbindingen (bijvoorbeeld GSM of satelliet). Er kunnen fouten optreden wanneer apparaten communiceren met cloudservices vanwege onregelmatige servicebeschikbaarheid en infrastructuur- of tijdelijke fouten. Een toepassing die op een apparaat wordt uitgevoerd, moet de mechanismen voor verbinding, opnieuw verbinding maken en de logica voor opnieuw proberen voor het verzenden en ontvangen van berichten beheren. De vereisten voor strategie voor opnieuw proberen zijn ook sterk afhankelijk van het IoT-scenario, de context en de mogelijkheden van het apparaat.
De Sdk's voor Azure IoT Hub-apparaten zijn bedoeld om het verbinden en communiceren van cloud-naar-apparaat en apparaat-naar-cloud te vereenvoudigen. Deze SDK's bieden een robuuste manier om verbinding te maken met Azure IoT Hub en een uitgebreide set opties voor het verzenden en ontvangen van berichten. Ontwikkelaars kunnen ook bestaande implementatie aanpassen om een betere strategie voor opnieuw proberen voor een bepaald scenario aan te passen.
De relevante SDK-functies die connectiviteit en betrouwbare berichten ondersteunen, zijn beschikbaar in de volgende Sdk's voor IoT Hub-apparaten. Zie de API-documentatie of specifieke SDK voor meer informatie:
In de volgende secties worden SDK-functies beschreven die ondersteuning bieden voor connectiviteit.
Verbinding maken ion and retry
In deze sectie vindt u een overzicht van de patronen voor opnieuw verbinden en opnieuw proberen die beschikbaar zijn bij het beheren van verbindingen. Het beschrijft de implementatierichtlijnen voor het gebruik van een ander beleid voor opnieuw proberen in uw apparaattoepassing en vermeldt relevante API's van de apparaat-SDK's.
Foutpatronen
Verbinding maken ionfouten kunnen op veel niveaus optreden:
- Netwerkfouten, waaronder verbroken socket- en naamomzettingsfouten
- Fouten op protocolniveau voor HTTP-, AMQP- en MQTT-transport, inclusief losgekoppelde koppelingen of verlopen sessies
- Fouten op toepassingsniveau die het gevolg zijn van lokale fouten, inclusief ongeldige referenties of servicegedrag (bijvoorbeeld het quotum of de beperking overschrijden)
De APPARAAT-SDK's detecteren fouten op alle drie niveaus. Apparaat-SDK's detecteren en verwerken echter geen os-gerelateerde fouten en hardwarefouten. Het SDK-ontwerp is gebaseerd op de richtlijnen voor het afhandelen van tijdelijke fouten vanuit het Azure Architecture Center.
Patronen voor opnieuw proberen
In de volgende stappen wordt het proces voor opnieuw proberen beschreven wanneer er verbindingsfouten worden gedetecteerd:
- De SDK detecteert de fout en eventuele bijbehorende fouten in het netwerk, protocol of de toepassing.
- De SDK gebruikt het foutfilter om het fouttype te bepalen en te bepalen of een nieuwe poging nodig is.
- Als de SDK een onherstelbare fout identificeert, worden bewerkingen zoals verbinding, verzenden en ontvangen gestopt. De SDK meldt de gebruiker. Voorbeelden van onherstelbare fouten zijn een verificatiefout en een onjuiste eindpuntfout.
- Als de SDK een herstelbare fout identificeert, wordt er opnieuw geprobeerd volgens het opgegeven beleid voor opnieuw proberen totdat de gedefinieerde time-out is verstreken. De SDK maakt standaard gebruik van Exponentieel uitstel met jitter-beleid voor opnieuw proberen.
- Wanneer de gedefinieerde time-out verloopt, probeert de SDK geen verbinding meer te maken of te verzenden. De gebruiker wordt op de hoogte stelt.
- Met de SDK kan de gebruiker een callback koppelen om wijzigingen in de verbindingsstatus te ontvangen.
De SDK's bieden drie beleidsregels voor opnieuw proberen:
- Exponentieel uitstel met jitter: Dit standaardbeleid voor opnieuw proberen is meestal agressief bij het begin en vertraagt na verloop van tijd totdat het een maximale vertraging bereikt. Het ontwerp is gebaseerd op richtlijnen voor opnieuw proberen van Azure Architecture Center.
- Aangepaste nieuwe poging: voor sommige SDK-talen kunt u een aangepast beleid voor opnieuw proberen ontwerpen dat beter geschikt is voor uw scenario en deze vervolgens in de RetryPolicy injecteren. Aangepaste nieuwe pogingen zijn niet beschikbaar in de C- of Python-SDK. De Python SDK maakt zo nodig opnieuw verbinding.
- Geen nieuwe poging: u kunt beleid voor opnieuw proberen instellen op 'geen nieuwe poging', waardoor de logica voor opnieuw proberen wordt uitgeschakeld. De SDK probeert eenmaal verbinding te maken en een bericht één keer te verzenden, ervan uitgaande dat de verbinding tot stand is gebracht. Dit beleid wordt doorgaans gebruikt in scenario's met problemen met bandbreedte of kosten. Als u deze optie kiest, gaan berichten die niet kunnen worden verzonden verloren en kunnen ze niet worden hersteld.
Beleids-API's opnieuw proberen
SDK
Methode SetRetryPolicy
Beleidsuitvoeringen
Begeleiding bij implementatie
E
IOTHUB_CLIENT_RESULT IoTHubClient_SetRetryPolicy
IOTHUB_CLIENT_RETRY_POLICY
Java
SetRetryPolicy
Standaard: ExponentialBackoffWithJitter-klasse Aangepast: RetryPolicy-interface implementeren Geen nieuwe poging: NoRetry-klasse
.NET
DeviceClient.SetRetryPolicy
Standaard: ExponentialBackoff-klasse Aangepast: IRetryPolicy-interface implementeren Geen nieuwe poging: NoRetry-klasse
Knooppunt
setRetryPolicy
Standaard: ExponentialBackoffWithJitter-klasse Aangepast: RetryPolicy-interface implementeren Geen nieuwe poging: NoRetry-klasse
Python
Wordt momenteel niet ondersteund
Wordt momenteel niet ondersteund
Ingebouwde nieuwe pogingen voor verbindingen: verbroken verbindingen worden standaard opnieuw geprobeerd met een vast interval van 10 seconden. Deze functionaliteit kan desgewenst worden uitgeschakeld en het interval kan worden geconfigureerd.
De volgende codevoorbeelden illustreren deze stroom.
Richtlijnen voor .NET-implementatie
In het volgende codevoorbeeld ziet u hoe u het standaardbeleid voor opnieuw proberen definieert en instelt:
// define/set default retry policy
IRetryPolicy retryPolicy = new ExponentialBackoff(int.MaxValue, TimeSpan.FromMilliseconds(100), TimeSpan.FromSeconds(10), TimeSpan.FromMilliseconds(100));
SetRetryPolicy(retryPolicy);
Om hoog CPU-gebruik te voorkomen, worden de nieuwe pogingen beperkt als de code onmiddellijk mislukt. Als er bijvoorbeeld geen netwerk of route naar de bestemming is. De minimale tijd voor het uitvoeren van de volgende nieuwe poging is 1 seconde.
Als de service reageert met een beperkingsfout, is het beleid voor opnieuw proberen anders en kan het niet worden gewijzigd via de openbare API:
// throttled retry policy
IRetryPolicy retryPolicy = new ExponentialBackoff(RetryCount, TimeSpan.FromSeconds(10),
TimeSpan.FromSeconds(60), TimeSpan.FromSeconds(5)); SetRetryPolicy(retryPolicy);
Het mechanisme voor opnieuw proberen stopt na DefaultOperationTimeoutInMilliseconds, dat momenteel is ingesteld op 4 minuten.
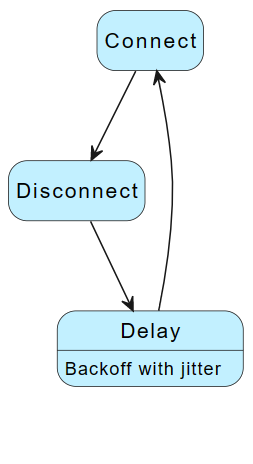
Hub-herverbindingsstroom
Als u IoT Hub alleen zonder DPS gebruikt, gebruikt u de volgende strategie voor opnieuw verbinden.
Wanneer een apparaat geen verbinding kan maken met IoT Hub of als de verbinding met IoT Hub is verbroken:
- Gebruik een exponentieel uitstel met jittervertragingsfunctie.
- Maak opnieuw verbinding met IoT Hub.
In het volgende diagram ziet u een overzicht van de stroom voor opnieuw verbinden.
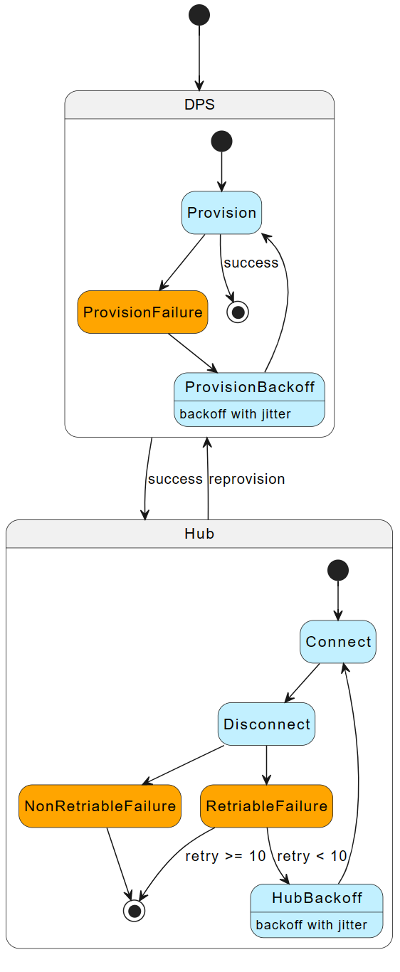
Hub met DPS-herverbindingsstroom
Als u IoT Hub met DPS gebruikt, gebruikt u de volgende strategie voor opnieuw verbinden.
Wanneer een apparaat geen verbinding kan maken met IoT Hub of de verbinding met IoT Hub is verbroken, maakt u opnieuw verbinding op basis van de volgende gevallen.
Scenario voor opnieuw verbinden
Strategie voor opnieuw verbinden
Voor fouten die nieuwe pogingen tot verbinding toestaan (HTTP-antwoordcode 500)
Gebruik een exponentieel uitstel met jittervertragingsfunctie. Maak opnieuw verbinding met IoT Hub.
Voor fouten die aangeven dat een nieuwe poging mogelijk is, maar opnieuw verbinden mislukt 10 opeenvolgende keren
Het apparaat opnieuw inrichten naar DPS.
Voor fouten die geen nieuwe pogingen tot verbinding toestaan (HTTP-antwoorden 401, Niet geautoriseerd of 403, Verboden of 404, Niet gevonden)
Het apparaat opnieuw inrichten naar DPS.
In het volgende diagram ziet u een overzicht van de stroom voor opnieuw verbinden.