Een classificatiemodel beoordelen
Een groot deel van machine learning gaat over het beoordelen van hoe goed modellen werken. Deze evaluatie vindt plaats tijdens de training, om het model vorm te geven en na de training, om te beoordelen of het model in de praktijk in orde is. Classificatiemodellen moeten worden beoordeeld, net als regressiemodellen, maar de manier waarop we deze evaluatie uitvoeren, kan soms iets complexer zijn.
Een vernieuwing op kosten
Houd er rekening mee dat we tijdens de training berekenen hoe slecht een model presteert en deze kosten of verliezen aanroepen. In lineaire regressie gebruiken we bijvoorbeeld vaak een metrische waarde met de naam mean-squared error (MSE). MSE wordt berekend door het voorspellings- en werkelijke label te vergelijken, het verschil te kwadraeren en het gemiddelde van het resultaat te nemen. We kunnen MSE gebruiken om ons model aan te passen en om te rapporteren hoe goed het werkt.
Kostenfuncties voor classificatie
Classificatiemodellen worden beoordeeld op hun uitvoerkans, zoals 40% kans op een lawine of definitieve labels,no avalanche of avalanche. Het gebruik van de uitvoerkans kan voordelig zijn tijdens de training. Kleine wijzigingen in het model worden doorgevoerd in wijzigingen in waarschijnlijkheden, zelfs als ze niet voldoende zijn om de definitieve beslissing te wijzigen. Het gebruik van de uiteindelijke labels voor een kostenfunctie is nuttiger als we de werkelijke prestaties van ons model willen schatten. Bijvoorbeeld in de testset. Omdat we voor praktijkgebruik de uiteindelijke labels gebruiken, niet de waarschijnlijkheden.
Logboekverlies
Logboekverlies is een van de populairste kostenfuncties voor eenvoudige classificatie. Logboekverlies wordt toegepast op uitvoerkansen. Net als bij MSE leiden kleine hoeveelheden fouten tot kleine kosten, terwijl gemiddelde hoeveelheden fouten leiden tot grote kosten. We tekenen logboekverlies in de volgende grafiek voor een label waarbij het juiste antwoord 0 (onwaar) was.
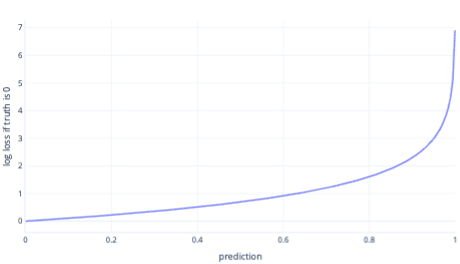
De x-as toont mogelijke modeluitvoer ( waarschijnlijkheden van 0 tot 1 ) en de y-as toont de kosten. Als een model een hoge betrouwbaarheid heeft dat het juiste antwoord 0 is (bijvoorbeeld 0,1 voorspellen). Vervolgens zijn de kosten laag omdat in dit geval het juiste antwoord 0 is. Als het model het resultaat ten onrechte voorspelt (bijvoorbeeld 0,9 voorspellen), worden de kosten hoog. In feite is de kosten bij x=1 zo hoog dat we hier de x-as bijsnijden tot 0,999 om de grafiek leesbaar te houden.
Waarom niet MSE?
MSE en logboekverlies zijn vergelijkbare metrische gegevens. Er zijn een aantal complexe redenen waarom logboekverlies wordt begunstigd voor logistieke regressie, maar ook enkele eenvoudigere redenen. Logboekverlies bestraft bijvoorbeeld veel sterker verkeerde antwoorden dan MSE. In de volgende grafiek, waarbij het juiste antwoord bijvoorbeeld 0 is, hebben voorspellingen boven 0,8 hogere kosten voor logboekverlies dan MSE.
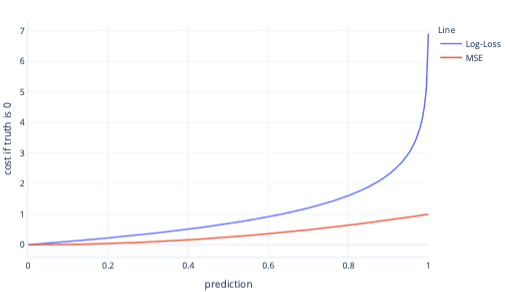
Als u op deze manier hogere kosten hebt, kan het model sneller leren vanwege de steilere kleurovergang van de lijn. Op dezelfde manier kunnen modellen met logboekverlies meer vertrouwen krijgen in het geven van het juiste antwoord. U ziet in de vorige plot dat de MSE-kosten voor waarden kleiner dan 0,2 klein zijn en dat de kleurovergang bijna vlak is. Deze relatie zorgt ervoor dat de training traag is voor modellen die bijna correct zijn. Logboekverlies heeft een steilere kleurovergang voor deze waarden, waardoor het model sneller kan leren.
Beperkingen van kostenfuncties
Het gebruik van één kostenfunctie voor menselijke evaluatie van het model is altijd beperkt, omdat het u niet vertelt wat voor soort fouten uw model maakt. Denk bijvoorbeeld aan ons voorspellingsscenario voor avalanche. Een hoge waarde voor logboekverlies kan betekenen dat het model herhaaldelijkvalanches voorspelt wanneer er geen zijn. Het kan ook betekenen dat het herhaaldelijk niet lukt om avalanches te voorspellen die wel gebeuren.
Om onze modellen beter te begrijpen, kan het eenvoudiger zijn om meer dan één getal te gebruiken om te beoordelen of ze goed werken. We behandelen dit grotere onderwerp in andere leermateriaal, hoewel we het in de volgende oefeningen aanraken.