De oplossingsarchitectuur verkennen
Laten we de architectuur bekijken die u hebt besloten voor de MACHINE Learning Operations -werkstroom (MLOps) om te begrijpen waar en wanneer we de code moeten verifiëren.
Notitie
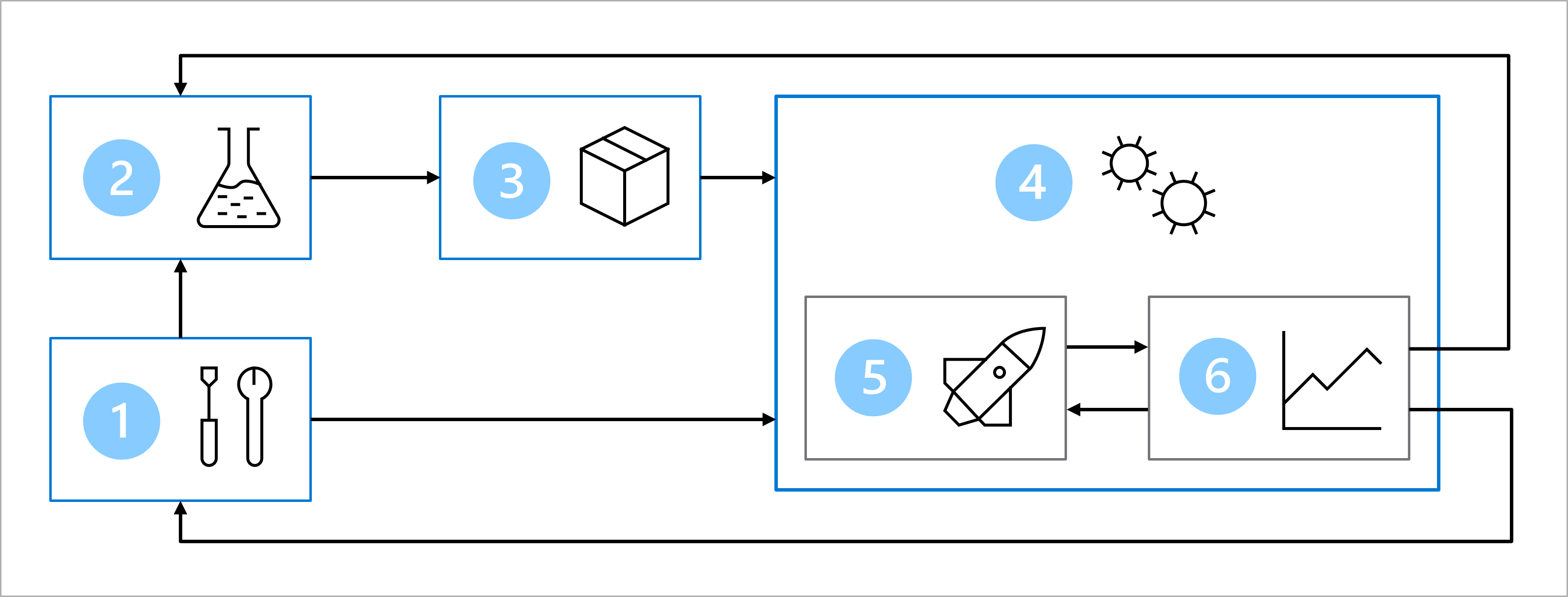
Het diagram is een vereenvoudigde weergave van een MLOps-architectuur. Als u een gedetailleerdere architectuur wilt bekijken, bekijkt u de verschillende use cases in de MLOps-oplossingsversneller (v2).
Het belangrijkste doel van de MLOps-architectuur is het maken van een robuuste en reproduceerbare oplossing. De architectuur omvat:
- Installatie: Maak alle benodigde Azure-resources voor de oplossing.
- Modelontwikkeling (interne lus): de gegevens verkennen en verwerken om het model te trainen en te evalueren.
- Continue integratie: het model verpakken en registreren.
- Modelimplementatie (outer loop): implementeer het model.
- Continue implementatie: test het model en promoot het naar de productieomgeving.
- Monitoring: Prestaties van modellen en eindpunten monitoren.
Als u een model van ontwikkeling naar implementatie wilt verplaatsen, hebt u continue integratie nodig. Tijdens continue integratie verpakt en registreert u het model. Voordat u echter een model inpakt, moet u de code controleren die wordt gebruikt om het model te trainen.
Samen met het data science-team hebt u besloten om trunk-based development te gebruiken. Niet alleen beschermen vertakkingen de productiecode, maar zij maken het ook mogelijk om voorgestelde wijzigingen automatisch te verifiëren voordat je ze samenvoegt met de productiecode.
Laten we de werkstroom voor een data scientist verkennen:
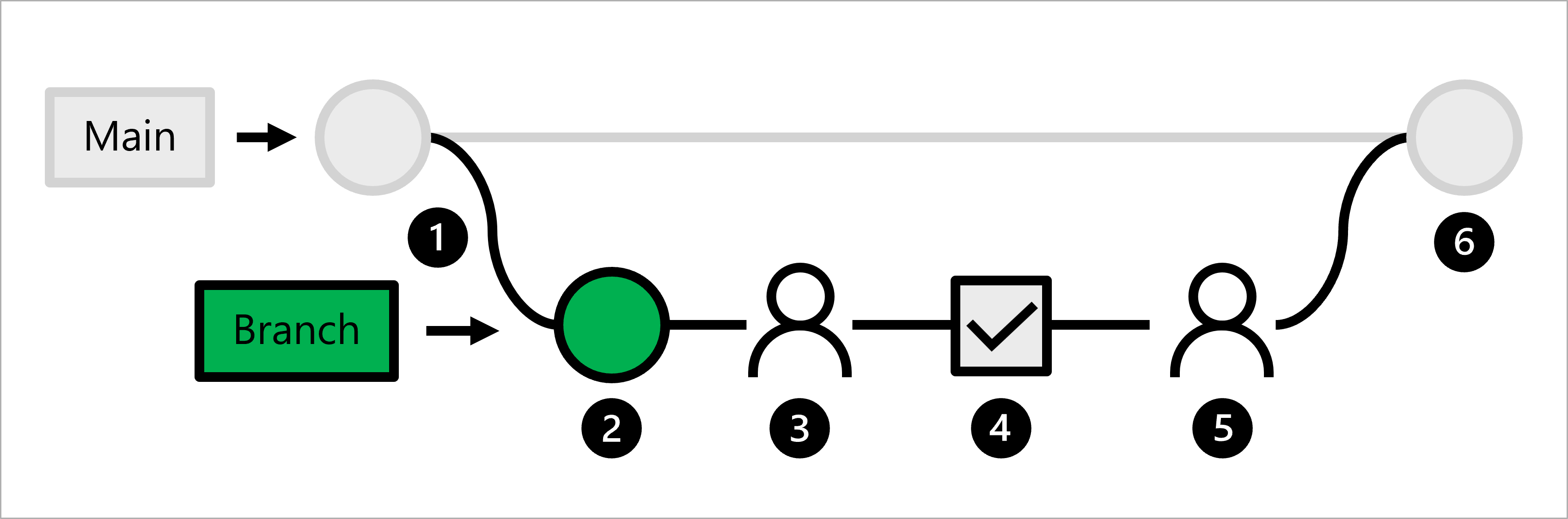
- De productiecode wordt gehost in de hoofdbranch .
- Een data scientist maakt een functiebranch voor modelontwikkeling.
- De data scientist maakt een pull-aanvraag om wijzigingen naar de hoofdbranch te pushen.
- Wanneer een pull-aanvraag wordt gemaakt, wordt een GitHub Actions-werkstroom geactiveerd om de code te verifiëren.
- Wanneer de code linting en unittesting doorstaat, moet de hoofdgegevenswetenschapper de voorgestelde wijzigingen goedkeuren.
- Nadat de hoofdgegevenswetenschapper de wijzigingen goedkeurt, wordt de pull-aanvraag samengevoegd en wordt de hoofdbranch dienovereenkomstig bijgewerkt.
Als machine learning-engineer moet u een GitHub Actions-werkstroom maken die de code verifieert door een linter en eenheidstests uit te voeren wanneer er een pull-aanvraag wordt gemaakt.
Tip
Meer informatie over het werken met broncodebeheer voor machine learning-projecten, waaronder ontwikkeling op basis van trunk en het lokaal verifiëren van uw code.