Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
CPU-druk is een nauwkeurigere indicator van resourceconflicten dan traditionele metrische gegevens over CPU-gebruik. Hoewel hoog CPU-gebruik het resourceverbruik weergeeft, duidt dit niet noodzakelijkerwijs op prestatieproblemen. In een AKS-cluster (Azure Kubernetes Service) kunt u inzicht krijgen in cpu-druk via PSI-metrische gegevens (Pressure Stall Information) om echte problemen met resourceconflicten te identificeren.
Wanneer een knooppunt in een AKS-cluster CPU-druk ondervindt, kunnen toepassingen slechte prestaties ondervinden, zelfs als het CPU-gebruik gemiddeld lijkt. Metrische PSI-gegevens bieden inzicht in werkelijke resourceconflicten door taakvertragingen te meten in plaats van alleen resourceverbruik.
Dit artikel helpt u bij het bewaken van CPU-druk met behulp van PSI-metrische gegevens en biedt aanbevolen procedures voor het oplossen van problemen met resourceconflicten.
Symptomen
De volgende tabel bevat een overzicht van de veelvoorkomende symptomen van CPU-druk:
| Symptoom | Beschrijving |
|---|---|
| Verhoogde toepassingslatentie | Services reageren langzamer, zelfs wanneer het CPU-gebruik gemiddeld lijkt. |
| Beperkte containers | Containers ondervinden vertragingen in de verwerking ondanks dat CPU-resources beschikbaar zijn op het knooppunt. |
| Verminderde prestaties | Toepassingen ervaren onvoorspelbare prestatievariaties die niet correleren met CPU-gebruikspercentages. |
Controlelijst voor probleemoplossing
Volg deze stappen om problemen met CPU-druk te identificeren en op te lossen:
Stap 1: PSI-metrische gegevens inschakelen en bewaken
Gebruik een van de volgende methoden om toegang te krijgen tot psi-metrische gegevens:
- Gebruik azure Monitoring Managed Prometheus of een andere bewakingsoplossing in een webbrowser om query's uit te voeren op psi-metrische gegevens.
- Gebruik in een console het opdrachtregelprogramma van Kubernetes (
kubectl).
Azure Monitoring Managed Prometheus biedt een manier om psi-metrische gegevens te bewaken:
Schakel Azure Monitoring Managed Prometheus in voor uw AKS-cluster door de instructies in Prometheus en Grafana in te schakelen.
Om aangepaste scrape-metrics voor Prometheus in te schakelen, zie Scrape-configuraties. Wij raden aan om
minumum ingestion profilein te stellen opfalseen omnode-exporterin te stellen optrue.Navigeer vanuit Azure Portal naar de Azure Monitor-werkruimte die is gekoppeld aan het AKS-cluster.
Selecteer Metrische gegevens onder Bewaking.
Selecteer metrische gegevens van Prometheus als de gegevensbron.
Opmerking
Als u de metrische gegevens wilt gebruiken, moet u deze inschakelen in Azure Monitoring Managed Prometheus. Deze metrische gegevens worden weergegeven door Node Exporter of cAdvisor.
Query's uitvoeren op specifieke PSI-metrische gegevens in Prometheus Explorer:
Gebruik de
node_pressure_cpu_waiting_seconds_totalPrometheus Query Language (PromQL) voor CPU-druk op knooppuntniveau.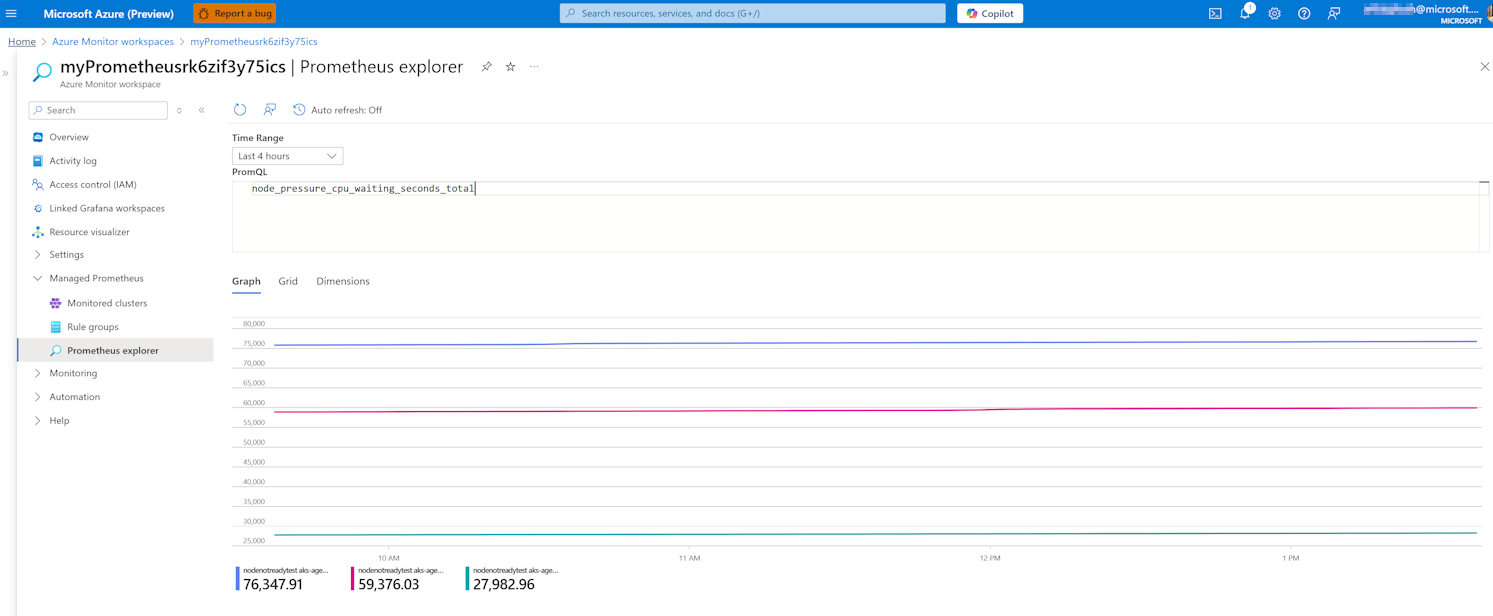
Gebruik de
container_cpu_cfs_throttled_seconds_totalPromQL voor CPU-druk op podniveau.
Bereken het PSI-sommige percentage (percentage van de tijd dat ten minste één taak is vastgelopen op CPU):
rate(node_pressure_cpu_waiting_seconds_total[5m]) * 100


Opmerking
Sommige metrische gegevens op containerniveau, zoals container_pressure_cpu_waiting_seconds_total en container_pressure_cpu_stalled_seconds_total zijn niet beschikbaar in AKS omdat ze deel uitmaken van de Kubelet PSI-functiepoort die de alfastatus heeft. AKS begint met het ondersteunen van het gebruik van de functie wanneer deze de bètafase bereikt.
Stap 2: Best practices bekijken om CPU-druk te voorkomen
Bekijk de volgende tabel voor meer informatie over het implementeren van aanbevolen procedures voor het voorkomen van CPU-druk:
| Best practice | Beschrijving |
|---|---|
| Focus op PSI-metrics in plaats van gebruiksstatistieken | Gebruik PSI-metrische gegevens als primaire indicator van resourceconflicten in plaats van cpu-gebruikspercentages. Zie PSI - Pressure Stall Information voor meer informatie. |
| Pods identificeren die de meeste CPU gebruiken | Isoleer de pods die gebruikmaken van de meeste CPU en identificeer oplossingen om de druk te verminderen. Zie Problemen met hoog CPU-gebruik in AKS-clusters oplossen voor meer informatie. |
| CPU-limieten minimaliseren | Overweeg CPU-limieten te verwijderen en te vertrouwen op de Completely Fair Scheduler van Linux met CPU-aandelen op basis van aanvragen. Zie Resourcebeheer voor pods en containers voor meer informatie. |
| De juiste QoS-klassen (Quality of Service) gebruiken | Stel de juiste QoS-klasse in voor elke pod op basis van het belang en de gevoeligheid voor conflicten. Voor meer informatie, zie Quality of Service voor Pods configureren. |
| Podplaatsing optimaliseren | Gebruik antiaffiniteitsregels voor pods om cpu-intensieve workloads op dezelfde knooppunten te voorkomen. Zie Pods toewijzen aan knooppunten voor meer informatie. |
| Monitor voor korte drukpieken | Korte drukpieken kunnen problemen aangeven, zelfs wanneer het gemiddelde gebruik acceptabel lijkt. Voor meer informatie, zie De pijplijn voor metrische resourcegegevens. |
Belangrijke PSI-metrische gegevens die moeten worden bewaakt
Opmerking
Als het CPU-gebruik van een knooppunt gemiddeld is, maar de containers op het knooppunt CFS-beperking ondervinden, verhoog de resourcelimieten of verwijder ze en volg het CFS-algoritme (Completely Fair Scheduler) van Linux.
PSI-metrische gegevens op knooppuntniveau
-
node_pressure_cpu_waiting_seconds_total: Cumulatieve tijdtaken wachten op CPU. -
node_cpu_seconds_total: Traditioneel CPU-gebruik voor vergelijking.
PSI-indicatoren op containerniveau
-
container_cpu_cfs_throttled_periods_total: Het aantal perioden dat een container wordt geknepen. -
container_cpu_cfs_throttled_seconds_total: Totale tijd dat een container wordt opgeschroefd. - Beperkingspercentage:
rate(container_cpu_cfs_throttled_periods_total[5m]) / rate(container_cpu_cfs_periods_total[5m]) * 100
Waarom metrische PSI-gegevens gebruiken?
AKS gebruikt PSI-metrische gegevens als indicator voor CPU-druk in plaats van het belastingsmiddelde om verschillende redenen:
- Bij grote en multi-core knooppunten wordt de load average vaak onderschat wat betreft cpu-verzadiging.
- Op spraakzamere en containerknooppunten kan het belastingsgemiddelde te vaak signaleren, wat leidt tot waarschuwingsmoeheid.
- Omdat het systeemlastgemiddelde per cgroup geen inzicht biedt, kunnen lawaaierige pods zich verbergen achter een laag systeemgemiddelde.
Referenties
- Documentatie voor Linux PSI
- Kubernetes-resourcebeheer
- Best practices voor AKS-prestaties
- Prometheus en Grafana inschakelen
- Quality of Service in Kubernetes
- Linux Completely Fair Scheduler
Contacteer ons voor hulp
Als u vragen hebt of hulp nodig hebt, maak een ondersteuningsaanvraag of vraag de Azure-communityondersteuning. U kunt ook productfeedback verzenden naar de Azure-feedbackcommunity.