Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: ✔️ Virtuele Linux-machines ✔️ van Windows
In dit artikel worden algemene prestatieproblemen van virtuele machines (VM' s) beschreven door het bewaken en observeren van knelpunten en wordt mogelijk herstel geboden voor problemen die zich kunnen voordoen. Naast bewaking kunt u ook Perfinsights gebruiken die een rapport kunnen bieden met aanbevelingen voor best practices en belangrijke knelpunten rond IO/CPU/geheugen. Perfinsights is beschikbaar voor virtuele Windows - en Linux-machines in Azure.
In dit artikel wordt uitgelegd hoe u bewaking gebruikt om knelpunten in prestaties te diagnosticeren.
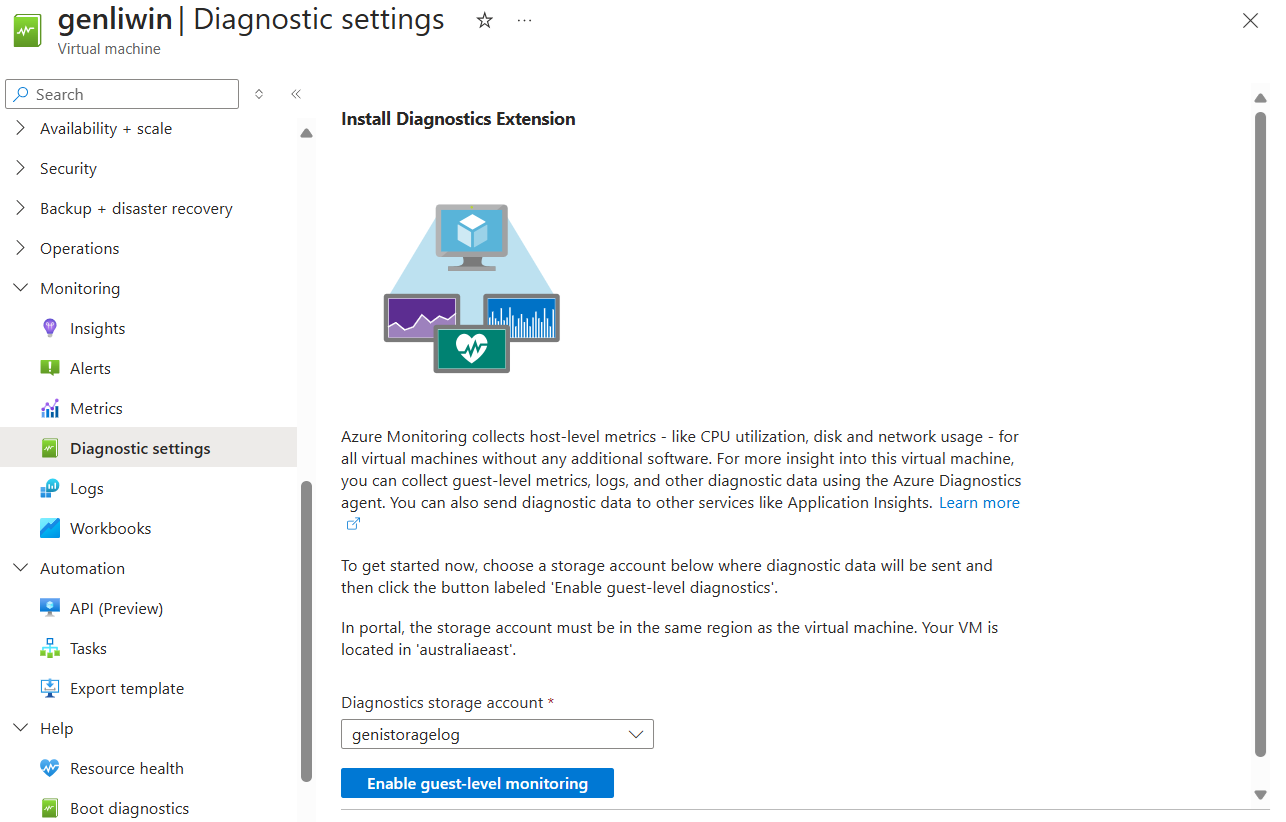
Vm-diagnostische gegevens inschakelen via Azure Portal
Diagnostische gegevens van vm's inschakelen:
Ga naar de VM.
Selecteer diagnostische instellingen in de sectie Bewaking.
Selecteer een opslagaccount en selecteer bewaking op gastniveau inschakelen.

Metrische gegevens van opslagaccounts weergeven via Azure Portal (voor onbeheerde schijf)
Voor de VIRTUELE machines die onbeheerde schijven gebruiken, is opslag een zeer belangrijke laag wanneer we IO-prestaties willen analyseren. Voor metrische gegevens met betrekking tot opslag moeten we diagnostische gegevens inschakelen als een extra stap:
Bepaal welk opslagaccount (of accounts) uw VIRTUELE machine gebruikt door de VM te selecteren:
- Selecteer uw VIRTUELE machine in Azure Portal.
- Selecteer Onder Instellingen de optie Schijf en zoek vervolgens het opslagaccount waarin de schijf is opgeslagen.
- Navigeer naar het opslagaccount en selecteer Metrische gegevens.
Prestatieknelpunten identificeren
Zodra we het eerste installatieproces voor de benodigde metrische gegevens hebben doorlopen en na het inschakelen van de diagnostische gegevens voor de VM en het gerelateerde opslagaccount, kunnen we overschakelen naar de analysefase.
Toegang tot de bewaking
Selecteer in Azure Portal de Azure-VM die u wilt onderzoeken, selecteer metrische gegevens in de sectie Bewaking en selecteer vervolgens een metrische waarde.

Tijdlijnen van observatie
Controleer uw gegevens om te bepalen of er knelpunten in de resource zijn. Als uw computer goed werkt, maar is gemeld dat de prestaties onlangs zijn verslechterd, controleert u een tijdsbereik met gegevens die metrische gegevens over prestaties omvatten vóór de gerapporteerde wijziging, tijdens en na het probleem.
Controleren op CPU-knelpunt
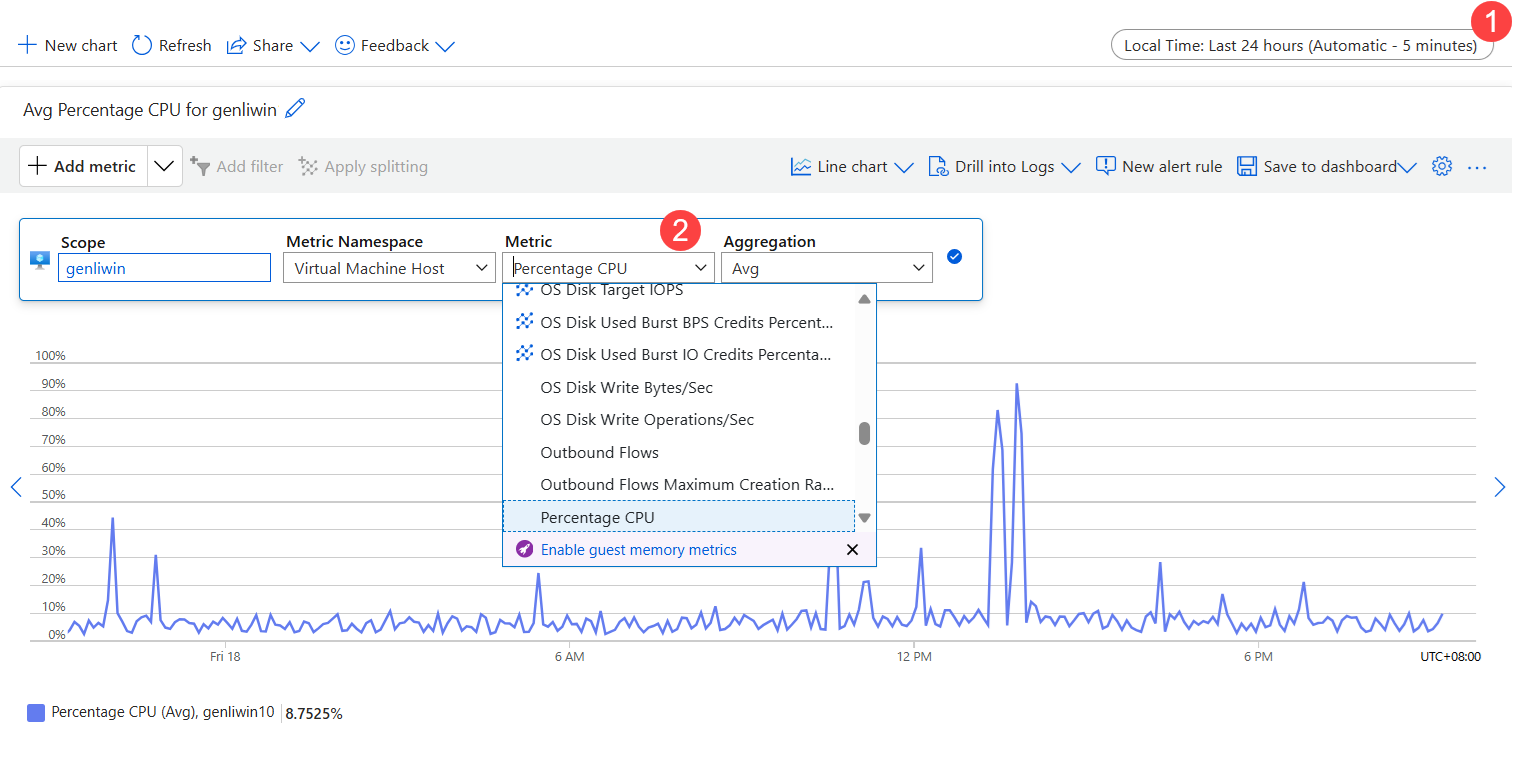
- Stel het tijdsbereik in.
- Selecteer in Metrisch het CPU-percentage.
Trends in CPU-prestaties bewaken
Wanneer u prestatieproblemen bekijkt, moet u rekening houden met de trends en begrijpen of deze van invloed zijn op u. In de volgende secties gebruiken we de bewakingsgrafieken van de portal om trends weer te geven. Ze kunnen ook handig zijn voor het kruisverwijzing naar verschilresourcegedrag in dezelfde periode. Als u de grafieken wilt aanpassen, klikt u op het Azure Monitor-gegevensplatform.
Spiking : Spiking kan betrekking hebben op een geplande taak/bekende gebeurtenis. Als u de taak kunt identificeren, bepaalt u of de taak wordt uitgevoerd op het vereiste prestatieniveau. Als de prestaties acceptabel zijn, hoeft u mogelijk geen resources te verhogen.
Piek omhoog en constant: geeft vaak een nieuwe workload aan. Als het geen herkende werkbelasting is, schakelt u bewaking in de VM in om erachter te komen welk proces (of processen) het gedrag veroorzaakt. Zodra het proces is herkend, bepaalt u of het toegenomen verbruik wordt veroorzaakt door inefficiënte code of normaal verbruik. Als normaal verbruik, moet u beslissen of het proces op het vereiste prestatieniveau werkt.
Constante: bepaal of uw VIRTUELE machine altijd op dit niveau is uitgevoerd of dat deze alleen op dat niveau wordt uitgevoerd sinds de diagnostische gegevens zijn ingeschakeld. Zo ja, identificeer het proces (of de processen) die het probleem veroorzaken en overweeg meer van die resource toe te voegen.
Geleidelijk toenemen: een constante toename van het verbruik is vaak inefficiënte code of een proces dat meer gebruikersworkloads in beslag neemt.
Herstel van hoog CPU-gebruik
Als uw toepassing of proces niet optimaal wordt uitgevoerd en het CPU-gebruik hoger blijft dan 95%, kunt u een van de volgende taken uitvoeren:
- Voor onmiddellijke hulp: verhoog de grootte van de virtuele machine naar een grootte met meer kernen
- Inzicht krijgen in het probleem: toepassing/proces onderzoeken en vervolgens problemen oplossen.
Als u de VM machine hebt vergroot en het CPU-gebruik nog steeds boven 95% ligt, zorgt dit er dan voor dat prestaties beter zijn of dat de hogere doorvoer de toepassing op een aanvaardbaar niveau brengt? Als dat niet het geval is, moet u de problemen van die afzonderlijke toepassing of dat afzonderlijke proces oplossen.
U kunt Perfinsights voor Windows of Linux gebruiken om te analyseren welk proces het grootste CPU-verbruik heeft.
Controleren op knelpunten in het geheugen
De metrische gegevens weergeven:
- Voeg een sectie toe.
- Voeg een tegel toe.
- Open de galerie.
- Selecteer het geheugengebruik en sleep. Wanneer de tegel is vastgezet, klikt u met de rechtermuisknop en selecteert u 6x4.
Trends in geheugenprestaties bewaken
Het geheugengebruik laat zien hoeveel geheugen er wordt verbruikt met de VIRTUELE machine. Inzicht in de trend en of deze is toegewezen aan het tijdstip waarop u problemen ziet. U moet altijd meer dan 100 MB beschikbaar geheugen hebben.
Piek en constant/constant onveranderlijk verbruik: hoog geheugengebruik is mogelijk niet de oorzaak van slechte prestaties, omdat sommige toepassingen zoals relationele database-engines een grote hoeveelheid geheugen toewijzen en dit gebruik mogelijk niet significant is. Als er echter meerdere geheugen-hongerige toepassingen zijn, ziet u mogelijk slechte prestaties van geheugenconflicten waardoor het bijsnijden en wisselen/wisselen naar schijf veroorzaakt. Deze slechte prestaties zijn vaak een merkbare oorzaak van de invloed op de prestaties van toepassingen.
Geleidelijk toenemend verbruik – Een mogelijke toepassing 'opwarmen', dit verbruik komt vaak voor bij het starten van database-engines. Het kan echter ook duiden op een geheugenlek in een toepassing. Identificeer de toepassing en begrijp of het gedrag wordt verwacht.
Pagina- of wisselbestandsgebruik: controleer of u het Wisselbestand van Windows (op D:) of linux-wisselbestand (op /dev/sdb) gebruikt. Als u niets op deze volumes behalve deze bestanden hebt, controleert u op hoge lees-/schrijfbewerkingen op deze schijven. Dit probleem wijst op lage geheugenomstandigheden.
Herstel van hoog geheugengebruik
Voer een van de volgende taken uit om een hoog geheugengebruik op te lossen:
- Voor onmiddellijke hulp of pagina- of wisselbestandsgebruik: verhoog de VM-grootte naar een met meer geheugen en bewaak vervolgens.
- Probleem begrijpen: zoek toepassingen/processen en los problemen op voor het identificeren van geheugentoepassingen met een hoog verbruik.
- Als u de toepassing kent, controleert u of de geheugentoewijzing kan worden beperkt.
Als u na een upgrade naar een grotere VIRTUELE machine ontdekt dat u nog steeds een constante toename tot 100% hebt, identificeert u de toepassing/het proces en lost u problemen op.
U kunt Perfinsights voor Windows of Linux gebruiken om te analyseren welk proces het geheugenverbruik aansturen.
Controleren op knelpunten op schijf (voor niet-beheerde schijf)
Als u het opslagsubsysteem voor de virtuele machine wilt controleren, controleert u de diagnostische gegevens op azure-VM-niveau met behulp van de tellers in VM Diagnostics en ook de diagnostische gegevens van het opslagaccount.
Voor specifieke probleemoplossing voor VM's kunt u Perfinsights voor Windows of Linux gebruiken, wat kan helpen bij het analyseren van welk proces de IO's aansturen.
Houd er rekening mee dat er geen tellers zijn voor zone-redundante en Premium Storage-accounts. Voor problemen met betrekking tot deze tellers dient u een ondersteuningsaanvraag in.
Diagnostische gegevens van opslagaccounts weergeven in bewaking
Als u aan de onderstaande items wilt werken, gaat u naar het opslagaccount voor de VIRTUELE machine in de portal:
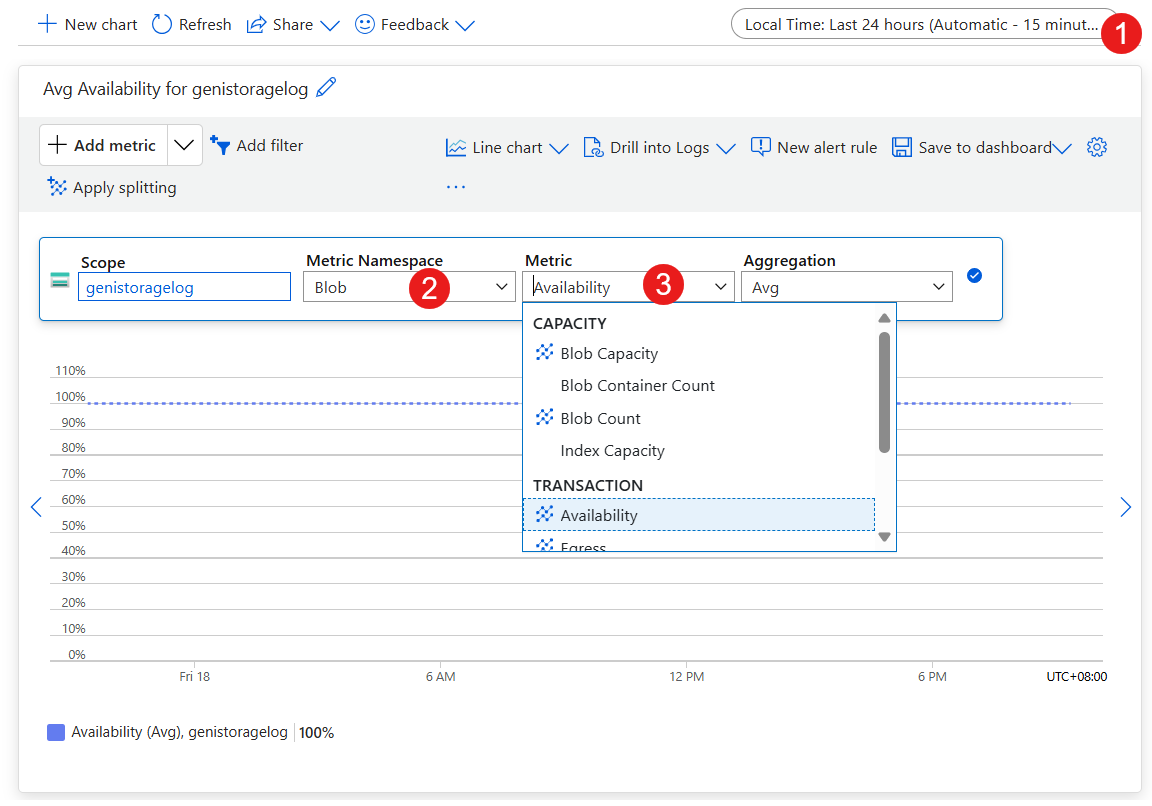
- Stel het tijdsbereik in.
- Stel de metrische naamruimte in op Blob.
- Stel metrische waarde in op Beschikbaarheid.
Prestatietrends voor schijven bewaken (alleen standaardopslag)
Als u problemen met opslag wilt identificeren, bekijkt u de metrische prestatiegegevens van de diagnostische gegevens van het opslagaccount en de diagnostische gegevens van de VM.
Zoek voor elke controle hieronder naar belangrijke trends wanneer de problemen zich voordoen binnen het tijdsbereik van het probleem.
Beschikbaarheid van Azure Storage controleren : de metrische gegevens van het opslagaccount toevoegen: beschikbaarheid
Als u een daling van beschikbaarheid ziet, kan er een probleem zijn met het platform, controleert u de Azure-status. Als er geen probleem wordt weergegeven, dient u een nieuwe ondersteuningsaanvraag in.
Controleren op time-out van Azure Storage - Metrische gegevens van het opslagaccount toevoegen
- ClientTimeOutError
- ServerTimeOutError
- AverageE2ELatency
- AverageServerLatency
- TotalRequests
Waarden in de metrische gegevens van *TimeOutError geven aan dat een IO-bewerking te lang duurde en een time-out heeft plaatsgevonden. Door de volgende stappen te doorlopen, kunt u mogelijke oorzaken identificeren.
AverageServerLatency neemt tegelijkertijd toe op de TimeOutErrors kan een platformprobleem zijn. Dien in deze situatie een nieuw ondersteuningsverzoek in.
AverageE2ELatency vertegenwoordigt de clientlatentie. Controleer hoe de IOPS wordt uitgevoerd door de toepassing. Zoek naar een toename of constant hoge totalRequests-metrische waarde. Deze metrische waarde vertegenwoordigt IOPS. Als u begint met het bereiken van de limieten van het opslagaccount of één VHD, kan de latentie te maken hebben met beperking.
Controleren op beperking van Azure Storage - Metrische gegevens van het opslagaccount toevoegen: ThrottlingError
Waarden voor beperking geven aan dat u wordt beperkt op opslagaccountniveau, wat betekent dat u de IOPS-limiet van het account bereikt. U kunt bepalen of u de drempelwaarde voor IOPS bereikt door de metrische TotalRequests te controleren.
Houd er rekening mee dat elke VHD een limiet van 500 IOPS of 60 MBits heeft, maar is gebonden aan de cumulatieve limiet van 20000 IOPS per opslagaccount.
Met deze metrische waarde kunt u niet zien welke blob de beperking veroorzaakt en welke worden beïnvloed door deze blob. U bereikt echter de IOPS- of inkomend/uitgaand verkeer van het opslagaccount.
Als u wilt bepalen of u de IOPS-limiet bereikt, gaat u naar de diagnostische gegevens van het opslagaccount en controleert u de TotalRequests en kijkt u of u 20 duizend TotalRequests nadert. Identificeer een wijziging in het patroon, of u de limiet voor de eerste keer ziet of of deze limiet op een bepaald moment plaatsvindt.
Met nieuwe schijfaanbiedingen onder Standard-opslag kunnen de IOPS- en doorvoerlimieten verschillen, maar de cumulatieve limiet van het Standard Storage-account is 20000 IOPS (Premium-opslag heeft verschillende limieten op account- of schijfniveau). Meer informatie over verschillende standaardopslagschijven en limieten per schijf:
Verwijzingen
De bandbreedte van het opslagaccount wordt gemeten door de metrische gegevens van het opslagaccount: TotalIngress en TotalEgress. U hebt verschillende drempelwaarden voor bandbreedte, afhankelijk van het type redundantie en regio's:
- Schaalbaarheids- en prestatiedoelen voor standaardopslagaccounts
- Schaalbaarheids- en prestatiedoelen voor Premium-blobopslagaccounts
Controleer de limieten TotalIngress en TotalEgress op basis van de limieten voor inkomend en uitgaand verkeer voor het type redundantie van het opslagaccount en de regio.
Controleer de doorvoerlimieten van de VHD's die zijn gekoppeld aan de virtuele machine. Voeg de metrische vm-schijf lezen en schrijven toe.
Nieuwe schijfaanbiedingen onder Standard-opslag hebben verschillende IOPS- en doorvoerlimieten (IOPS worden niet per VHD weergegeven). Bekijk de gegevens om te zien of u de limieten van gecombineerde doorvoer MB van de VHD('s) op VM-niveau bereikt met schijflees- en schrijfbewerkingen, en optimaliseer vervolgens de configuratie van uw VM-opslag om te schalen naar eerdere VHD-limieten. Meer informatie over verschillende standaardopslagschijven en limieten per schijf:
Hoog schijfgebruik/latentieherstel
Clientlatentie verminderen en VM-IO optimaliseren om eerdere VHD-limieten te schalen
Beperking verminderen
Als u de bovengrens van opslagaccounts bereikt, moet u de VHD's tussen opslagaccounts opnieuw verdelen. Raadpleeg Azure Storage-schaalbaarheids- en prestatiedoelen.
Doorvoer verhogen en latentie verminderen
Als u een latentiegevoelige toepassing hebt en hoge doorvoer nodig hebt, migreert u uw VHD's naar Azure Premium-opslag met behulp van de VM uit de DS- en GS-serie.
In deze artikelen worden de specifieke scenario's besproken:
Contacteer ons voor hulp
Als u vragen hebt of hulp nodig hebt, maak een ondersteuningsaanvraag of vraag de Azure-communityondersteuning. U kunt ook productfeedback verzenden naar de Azure-feedbackcommunity.